org ai
1.0.0
Modo menor para EMACS Org-Mode que proporciona acceso a modelos de IA generativos. Actualmente compatibles son
Dentro de un búfer en modo de orgía puede
Nota: Para usar la API de OpenAI, necesitará una cuenta de OpenAI y necesitará obtener un token API. Por lo que puedo decir, los límites de uso actuales para el nivel gratuito lo llevan bastante lejos.
#+begin_ai...#+end_ai bloques especiales #+begin_ai
Is Emacs the greatest editor?
#+end_ai
Puede continuar escribiendo y presionando Cc Cc para crear una conversación. Cg interrumpirá una solicitud de ejecución.
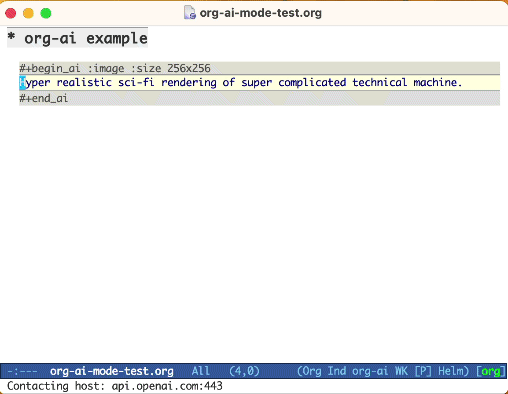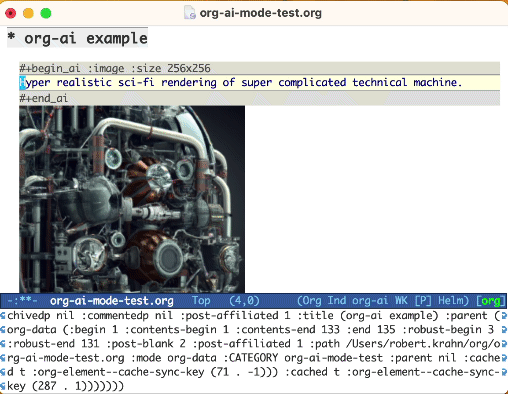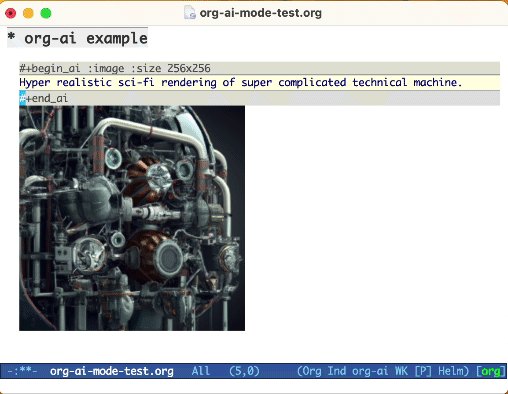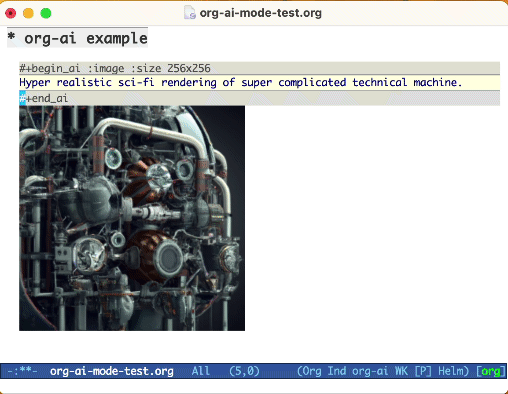
Use la palabra clave :image para generar una imagen. Esto usa Dall · E-3 por defecto.
#+begin_ai :image :size 1024x1024
Hyper realistic sci-fi rendering of super complicated technical machine.
#+end_ai
Puede usar las siguientes palabras clave para controlar la generación de imágenes:
:size <width>x<height> - El tamaño de la imagen para generar (predeterminado: 1024x1024):model <model> -El modelo a usar (predeterminado: "dall-e-3" ):quality <quality> - La calidad de la imagen (opciones: hd , standard ):style <style> - El estilo de usar (opciones: vivid , natural )(Para obtener más información sobre esa configuración, consulte esta publicación de blog de OpenAI.
Puede personalizar los valores predeterminados para esas variables con customize-variable o configurandolas en su configuración:
( setq org-ai-image-model " dall-e-3 " )
( setq org-ai-image-default-size " 1792x1024 " )
( setq org-ai-image-default-count 2 )
( setq org-ai-image-default-style 'vivid )
( setq org-ai-image-default-quality 'hd )
( setq org-ai-image-directory ( expand-file-name " org-ai-images/ " org-directory))
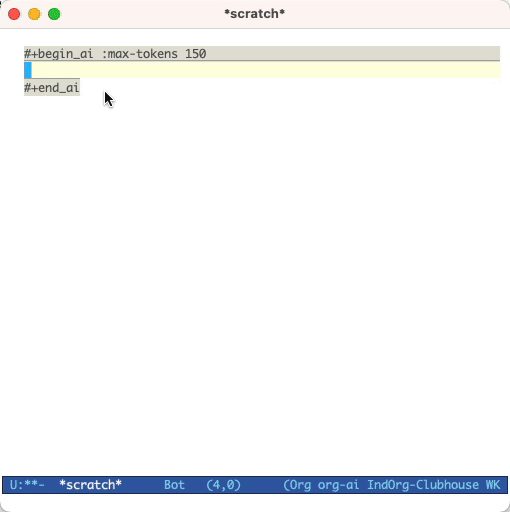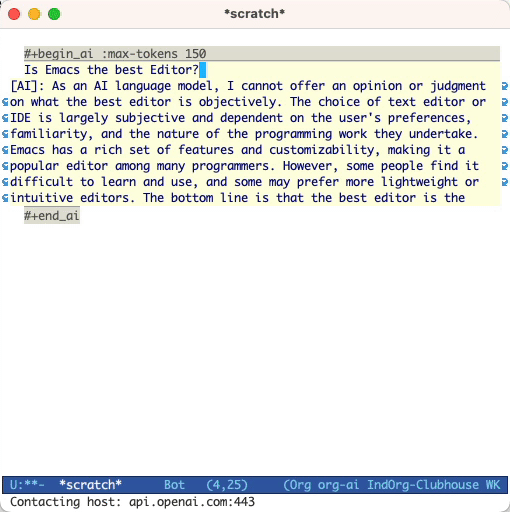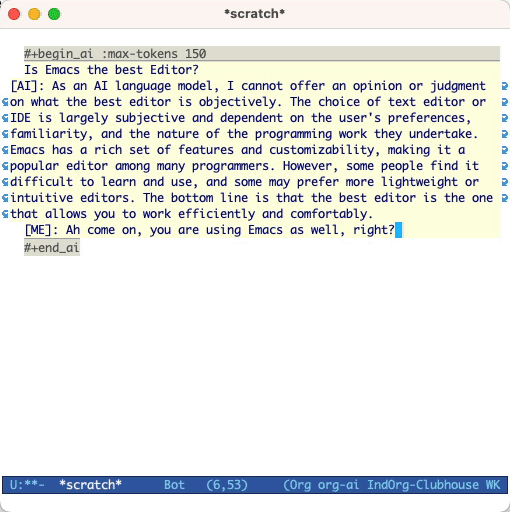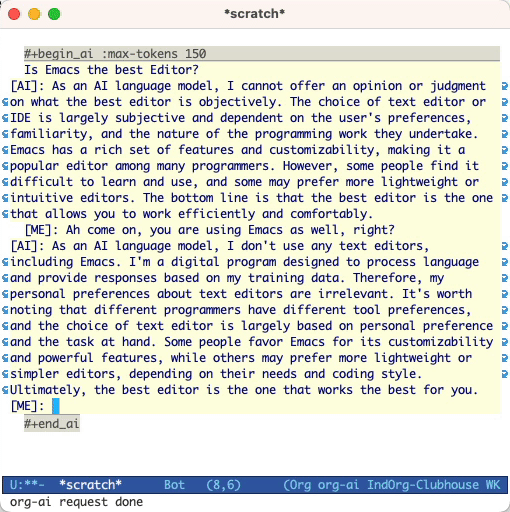
#+begin_ai...#+end_ai bloques especialesSimilar a Org-Babel, estos bloques demarcan la entrada (y para la salida de ChatGPT) para el modelo AI. Puede usarlo para el chat Ai, la finalización del texto y el texto -> Generación de imágenes. Consulte las opciones a continuación para obtener más información.
Crear un bloque como
#+begin_ai
Is Emacs the greatest editor?
#+end_ai
y presione Cc Cc . La entrada de chat aparecerá en línea y una vez que se complete la respuesta, puede ingresar su respuesta, etc. Vea la demostración a continuación. Puede presionar Cg mientras la solicitud de IA se ejecuta para cancelarla.
También puede modificar el indicador del sistema y otros parámetros utilizados. El mensaje del sistema se inyecta antes de la entrada del usuario y "primos" del modelo para responder en cierto estilo. Por ejemplo, puedes hacer:
#+begin_ai :max-tokens 250
[SYS]: Act as if you are a powerful medival king.
[ME]: What will you eat today?
#+end_ai
Esto dará como resultado una carga útil de API como
{
"messages" : [
{
"role" : " system " ,
"content" : " Act as if you are a powerful medival king. "
},
{
"role" : " user " ,
"content" : " What will you eat today? "
}
],
"model" : " gpt-4o-mini " ,
"stream" : true ,
"max_tokens" : 250 ,
"temperature" : 1.2
}Para algunas ideas rápidas, consulte, por ejemplo, las impresionantes indicaciones de ChatGPT.
Al generar imágenes utilizando el indicador :image , aparecerán debajo del bloque AI en línea. Las imágenes se almacenarán (junto con su aviso) dentro de org-ai-image-directory que es predeterminado a ~/org/org-ai-images/ .
También puede usar la entrada del habla para transcribir la entrada. Presione Cc r para org-ai-talk-capture-in-org para comenzar a grabar. Tenga en cuenta que esto requerirá que configure el reconocimiento de voz (ver más abajo). La salida del habla se puede habilitar con org-ai-talk-output-enable .
Dentro de un #+begin_ai...#+end_ai puede modificar y seleccionar las partes del chat con estos comandos:
Cc <backspace> ( org-ai-kill-region-at-point ) para eliminar la parte de chat bajo el punto.org-ai-mark-region-at-point marcará la región en el punto.org-ai-mark-last-region marcará la última parte de chat. Para aplicar la sintaxis resaltada a su #+begin_ai ... Bloqueos simplemente agregue un nombre de modo principal de idioma después de _ai . Por ejemplo, #+begin_ai markdown . Para Markdown en particular, para entonces también resaltar correctamente el código en Backticks, puede establecer (setq markdown-fontify-code-blocks-natively t) . Asegúrese de que también tenga instalado el paquete de modo Markdown. ¡Gracias @TavisRudd por este truco!
Este comportamiento está habilitado de forma predeterminada para que la interacción sea más similar a un chat. Puede ser molesto cuando la salida larga está presente y el búfer se desplaza mientras lee. Para que pueda deshabilitar esto con:
( setq org-ai-jump-to-end-of-block nil ) Set (setq org-ai-auto-fill t) para "llenar" (envolver automáticamente las líneas de acuerdo con la fill-column ) el texto insertado. Básicamente como auto-fill-mode pero para la IA.
El bloque #+begin_ai...#+end_ai puede tomar las siguientes opciones.
Por defecto, el contenido de los bloques de IA se interpreta como mensajes para ChatGPT. Texto siguiente [ME]: está asociado con el usuario, texto siguiente [AI]: está asociado como la respuesta del modelo. Opcionalmente, puede iniciar el bloque con una entrada [SYS]: <behavior> para cebar el modelo (ver org-ai-default-chat-system-prompt a continuación).
:max-tokens number : número de tokens máximos para generar (predeterminado: nulo, use el valor predeterminado de OpenAI):temperature number : temperatura del modelo (predeterminado: 1):top-p number - Top_p del modelo (predeterminado: 1):frequency-penalty number : penalización de frecuencia del modelo (predeterminado: 0):presence-penalty - Presencia Penalización del modelo (predeterminado: 0):sys-everywhere : repita la solicitud del sistema para cada mensaje de usuario (predeterminado: nulo) Si tiene muchos hilos diferentes de conversación con respecto al mismo tema y configuración (aviso del sistema, temperatura, etc.) y no desea repetir todas las opciones, puede establecer propiedades de alcance del archivo de organización o crear un encabezado de Org con propiedad cajón, de modo que todos los bloqueos #+begin_ai...#+end_ai debajo de ese encabezado heredarán la configuración.
Ejemplos:
* Emacs (multiple conversations re emacs continue in this subtree)
:PROPERTIES:
:SYS: You are a emacs expert. You can help me by answering my questions. You can also ask me questions to clarify my intention.
:temperature: 0.5
:model: gpt-4o-mini
:END:
** Web programming via elisp
#+begin_ai
How to call a REST API and parse its JSON response?
#+end_ai
** Other emacs tasks
#+begin_ai...#+end_ai
* Python (multiple conversations re python continue in this subtree)
:PROPERTIES:
:SYS: You are a python programmer. Respond to the task with detailed step by step instructions and code.
:temperature: 0.1
:model: gpt-4
:END:
** Learning QUIC
#+begin_ai
How to setup a webserver with http3 support?
#+end_ai
** Other python tasks
#+begin_ai...#+end_ai
Se pueden usar las siguientes variables personalizadas para configurar el chat:
org-ai-default-chat-model (predeterminado: "gpt-4o-mini" )org-ai-default-max-tokens cuánto tiempo debería ser la respuesta. Actualmente no puede exceder el 4096. Si este valor es demasiado pequeño, se puede cortar una respuesta (predeterminada: nulo)org-ai-default-chat-system-prompt cómo "preparar" el modelo. Este es un mensaje que se inyecta antes de la entrada del usuario. (Valor predeterminado: "You are a helpful assistant inside Emacs." ).org-ai-default-inject-sys-prompt-for-all-messages para repetir el indicador del sistema para cada mensaje de usuario. A veces, el modelo "olvida" cómo estaba preparado. Esto puede ayudar a recordarlo. (predeterminado: nil ) Cuando agrega una opción :image al bloque AI, el mensaje se utilizará para la generación de imágenes.
:image : generar una imagen en lugar de texto:size : tamaño de la imagen para generar (predeterminado: 256x256, puede ser 512x512 o 1024x1024):n - el número de imágenes para generar (predeterminado: 1)Las siguientes variables personalizadas se pueden usar para configurar la generación de imágenes:
org-ai-image-directory : dónde almacenar las imágenes generadas (predeterminada: ~/org/org-ai-images/ ) Similar a Dall-E pero usa
#+begin_ai :sd-image
<PROMPT>
#+end_ai
Puede ejecutar IMG2Img etiquetando su imagen en modo Org con el nombre #+y hace referencia con: Image-Ref desde su bloque Org-AI.
#+begin_ai :sd-image :image-ref label1
forest, Gogh style
#+end_ai
MX org-ai-sd-clip adivina el mensaje de la imagen anterior en el modo de org por el clip interrogador y lo guarda en el anillo de matar.
MX Org-Ai-Sd-Deepdanbooru adivina el indicador de la imagen anterior en el modo org por el interrogador DeepDanbooru y lo guarda en el anillo de matar.
Para solicitar finalizaciones de un modelo local servido con Oobabooga/Texto-Generación-Webui, revise los pasos de configuración descritos a continuación
Luego inicie un servidor API:
cd ~ /.emacs.d/org-ai/text-generation-webui
conda activate org-ai
python server.py --api --model SOME-MODEL Cuando agrega una clave :local a un bloque ORG-AI y complementos de solicitud con Cc Cc , el bloque se enviará al servidor API local en lugar de la API de OpenAI. Por ejemplo:
#+begin_ai :local
...
#+end_ai
Esto enviará una solicitud a org-ai-oobabooga-websocket-url y transmitirá la respuesta al búfer de Org.
Los modelos de finalización más antiguos también se pueden solicitar agregando la opción :completion al bloque AI.
:completion : en lugar de usar el modelo CHATGPT, use el modelo de finalización:model : qué modelo usar, consulte https://platform.openai.com/docs/models para obtener una lista de modelosPara el significado detallado de esos parámetros, consulte la documentación de la API de OpenAI.
Las siguientes variables personalizadas se pueden usar para configurar la generación de texto:
org-ai-default-completion-model (predeterminado: "text-davinci-003" ) También puede usar una imagen existente como entrada para generar imágenes más similares. El comando org-ai-image-variation solicitará una ruta de archivo a una imagen, un tamaño y un recuento y luego generará tantas imágenes e insertará enlaces dentro del búfer org-mode actual. Las imágenes se almacenarán dentro de org-ai-image-directory . Vea la demostración a continuación.
Para obtener más información, consulte la documentación de OpenAI. La imagen de entrada debe ser cuadrada y su tamaño debe ser inferior a 4 MB. Y actualmente necesita curl disponible como una herramienta de línea de comandos 1 .
org-ai también se puede usar fuera de los búferes org-mode . Cuando habilita org-ai-global-mode , el prefijo Cc Ma estará vinculado a una serie de comandos:
| dominio | pandeo de llaves | descripción |
|---|---|---|
org-ai-on-region | Cc Ma r | Haga una pregunta sobre el texto seleccionado o dígale a la IA que haga algo con él. La respuesta se abrirá en un búfer en modo ORG para que pueda continuar la conversación. Configuración de la variable org-ai-on-region-file (por ejemplo (setq org-ai-on-region-file (expand-file-name "org-ai-on-region.org" org-directory)) ) se asociará un archivo con ese búfer. |
org-ai-summarize | Cc Ma s | Resume el texto seleccionado. |
org-ai-refactor-code | Cc Ma c | Dígale a la IA cómo cambiar el código seleccionado, aparecerá un búfer DIFF con los cambios. |
org-ai-on-project | Cc Ma p | Ejecutar las indicaciones y modificar / refactor múltiples archivos a la vez. Utilizará proyectil si está disponible, vuelve al directorio actual si no. |
org-ai-prompt | Cc Ma P | Solicite al usuario un texto y luego imprima la respuesta de la IA en el búfer actual. |
org-ai-switch-chat-model | Cc Ma m | Cambiar interactivamente org-ai-default-chat-model |
org-ai-open-account-usage-page | Cc Ma $ | Abre https://platform.openai.com/account/usage para ver cuánto dinero ha quemado. |
org-ai-open-request-buffer | Cc Ma ! | Abre el búfer de solicitud url . Si algo no funciona, puede ser útil echar un vistazo. |
org-ai-talk-input-toggle | Cc Ma t | Generalmente habilite la entrada del habla para los diferentes comandos de solicitud. |
org-ai-talk-output-toggle | Cc Ma T | Generalmente habilita la salida del habla. |
El uso del búfer Org-AI-on-Project le permite ejecutar comandos en archivos en un proyecto, alternativamente también en el texto seleccionado en esos archivos. Puede seleccionar el lectura de un proyecto y preguntar "¿De qué se trata?" o tener código explicado a usted. También puede solicitar cambios en el código, lo que generará una diferencia. Si sabe de alguna manera que piensa que solo VS Código con Copilot habilitado puede hacerlo, señale aquí.
Ejecutar el comando org-ai-on-project abrirá un búfer separado que le permite seleccionar elegir múltiples archivos (y opcionalmente seleccionar una subregión dentro de un archivo) y luego ejecutar una solicitud en él.
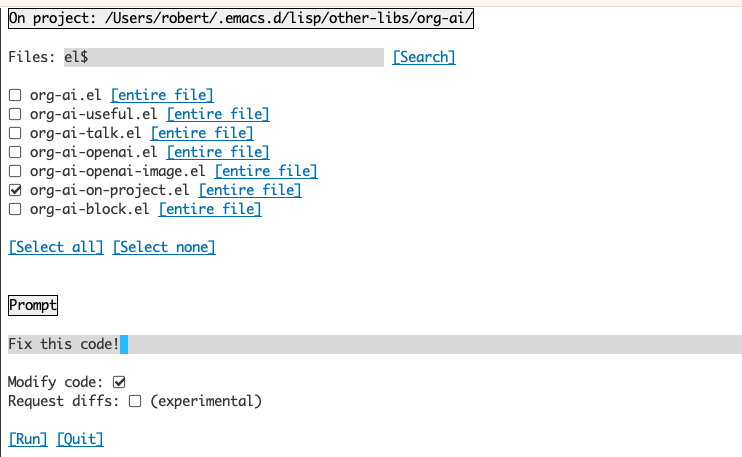
Si desactiva el "código de modificación", el efecto es similar a la ejecución de org-ai-on-region solo que todos los contenidos del archivo aparecen en el mensaje.
Con el "código de modificación" activado, puede pedirle a la IA que modifique o refactorice el código. De manera predeterminada ("solicitud, diffs") desactivó, solicitaremos generar el nuevo código para todos los archivos/regiones seleccionados y luego puede ver una diferencia por archivo y decidir aplicarlo o no. Con "solicitudes de solicitud" activas, se le pedirá a la IA que cree directamente una diferencia unificada que luego se puede aplicar.
Dado un bloque de origen con nombre
#+name: sayhi
#+begin_src shell
echo "Hello there"
#+end_src
Podemos intentar hacer referencia a él por su nombre, pero no funciona.
#+begin_ai
[SYS]: You are a mimic. Whenever I say something, repeat back what I say to you. Say exactly what I said, do not add anything.
[ME]: <<sayhi()>>
[AI]: <<sayhi()>>
[ME]:
#+end_ai
Con :noweb yes
#+begin_ai :noweb yes
[SYS]: You are a mimic. Whenever I say something, repeat back what I say to you. Say exactly what I said, do not add anything.
[ME]: <<sayhi()>>
[AI]: Hello there.
[ME]:
#+end_ai
También puede activar la expansión de NowEB con un org-ai-noweb: yes , encabezando la condición en cualquier lugar de los encabezados de los padres (el encabezado args tiene prioridad).
Para ver a qué se expandirá su documento cuando se envíe a la API, ejecute org-ai-expand-block .
Este es un truco pero funciona muy bien.
Crear un bloque
#+name: identity
#+begin_src emacs-lisp :var x="fill me in"
(format "%s" x)
#+end_src
Podemos invocarlo y dejar que los parámetros de Noweb (que admiten LISP) evalúan como código
#+begin_ai :noweb yes
Tell me some 3, simple ways to improve this dockerfile
<<identity(x=(quelpa-slurp-file "~/code/ibr-api/Dockerfile"))>>
[AI]: 1. Use a more specific version of Python, such as "python:3.9.6-buster" instead of "python:3.9-buster", to ensure compatibility with future updates.
2. Add a cleanup step after installing poetry to remove any unnecessary files or dependencies, thus reducing the size of the final image.
3. Use multi-stage builds to separate the build environment from the production environment, thus reducing the size of the final image and increasing security. For example, the first stage can be used to install dependencies and build the code, while the second stage can contain only the final artifacts and be used for deployment.
[ME]:
#+end_ai
org-ai está en Melpa: https://melpa.org/#/org-ai. Si ha agregado MELPA a sus archivos de paquete con
( require 'package )
( add-to-list 'package-archives '( " melpa " . " http://melpa.org/packages/ " ) t )
( package-initialize )Puede instalarlo con:
( use-package org-ai
:ensure t
:commands (org-ai-mode
org-ai-global-mode)
:init
( add-hook 'org-mode-hook # 'org-ai-mode ) ; enable org-ai in org-mode
(org-ai-global-mode) ; installs global keybindings on C-c M-a
:config
( setq org-ai-default-chat-model " gpt-4 " ) ; if you are on the gpt-4 beta:
(org-ai-install-yasnippets)) ; if you are using yasnippet and want `ai` snippets
( straight-use-package
'(org-ai :type git :host github :repo " rksm/org-ai "
:local-repo " org-ai "
:files ( " *.el " " README.md " " snippets " )))Vea este repositorio.
git clone
https://github.com/rksm/org-ai Entonces, si usa use-package :
( use-package org-ai
:ensure t
:load-path ( lambda () " path/to/org-ai " ))
; ; ...rest as above...
o solo con require :
( package-install 'websocket )
( add-to-list 'load-path " path/to/org-ai " )
( require 'org )
( require 'org-ai )
( add-hook 'org-mode-hook # 'org-ai-mode )
(org-ai-global-mode)
( setq org-ai-default-chat-model " gpt-4 " ) ; if you are on the gpt-4 beta:
(org-ai-install-yasnippets) ; if you are using yasnippet and want `ai` snippetsPuede configurar directamente su token API en su configuración:
( setq org-ai-openai-api-token " <ENTER YOUR API TOKEN HERE> " )
Alternativamente, org-ai admite auth-source para recuperar su clave API. Puedes almacenar un secreto en el formato
machine api.openai.com login org-ai password <your-api-key>
en su archivo ~/authinfo.gpg . Si esto está presente, Org-AI utilizará este mecanismo para recuperar el token cuando se realice una solicitud. Si no desea que org-ai intente recuperar la clave de auth-source , puede establecer org-ai-use-auth-source a nil antes de cargar org-ai .
Puede cambiar a Azure personalizando estas variables, ya sea interactivamente con Mx customize-variable o agregándolas a su configuración:
( setq org-ai-service 'azure-openai
org-ai-azure-openai-api-base " https://your-instance.openai.azure.com "
org-ai-azure-openai-deployment " azure-openai-deployment-name "
org-ai-azure-openai-api-version " 2023-07-01-preview " ) Para almacenar las credenciales de API, siga las instrucciones de AuthInfo anteriores, pero use org-ai-azure-openai-api-base como nombre de la máquina.
Para obtener una lista de modelos disponibles, consulte la documentación de perplejidad.ai.
Cambie el servicio predeterminado en su configuración:
( setq org-ai-service 'perplexity .ai)
( setq org-ai-default-chat-model " llama-3-sonar-large-32k-online " )o por bloque:
#+begin_ai :service perplexity.ai :model llama-3-sonar-large-32k-online
[ME]: Tell me fun facts about Emacs.
#+end_ai
Para la autenticación org-ai-openai-api-token authinfo.gpg una entrada como machine api.perplexity.ai login org-ai password pplx-*** .
Nota: Actualmente la perplejidad.ai no da acceso a referencias/enlaces a través de la API, por lo que las emacs no podrán mostrar referencias. Tienen un programa beta para esa ejecución y espero que esto esté disponible en general pronto.
Similar a lo anterior. P.ej
#+begin_ai :service anthropic :model claude-3-opus-20240229
[ME]: Tell me fun facts about Emacs.
#+end_ai
Los modelos antrópicos están aquí. Actualmente solo hay una versión API que se establece a través de org-ai-anthropic-api-version . Si sale otra versión, puedes encontrarla aquí.
Para el token API, use machine api.anthropic.com login org-ai password sk-ant-*** En su authinfo.gpg .
Estos pasos de configuración son opcionales. Si no desea usar la entrada / salida del habla, puede omitir esta sección.
Nota: Mi configuración personal para Org-AI se puede encontrar en este esencia. Contiene una configuración de susurro en funcionamiento.
Esto se ha probado en MacOS y Linux. Alguien con una computadora de Windows, por favor prueba esto y hazme saber qué hay que hacer para que funcione (¡gracias!).
La entrada del habla usa Whisper.EL y ffmpeg . Debe clonar el repositorio directamente o usar recto. Para instalarlo.
brew install ffmpeg en macOS) o sudo apt install ffmpeg en Linux.git clone https://github.com/natrys/whisper.el path/to/whisper.elAhora deberías poder cargarlo dentro de Emacs:
( use-package whisper
:load-path " path/to/whisper.el "
:bind ( " M-s-r " . whisper-run))Ahora también carga:
( use-package greader :ensure )
( require 'whisper )
( require 'org-ai-talk )
; ; macOS speech settings, optional
( setq org-ai-talk-say-words-per-minute 210 )
( setq org-ai-talk-say-voice " Karen " )En los macos necesitarás hacer dos cosas más:
Puedes usar el ayudante tccutil:
git clone https://github.com/DocSystem/tccutil
cd tccutil
sudo python ./tccutil.py -p /Applications/Emacs.app -e --microphone Cuando ahora ejecuta ffmpeg -f avfoundation -i :0 output.mp3 desde dentro de un shell emacs, no debería haber abort trap: 6 error.
(Como alternativa a tccutil.py, consulte el método mencionado en este tema).
Puede usar la salida de ffmpeg -f avfoundation -list_devices true -i "" para enumerar los dispositivos de entrada de audio y luego decirle a Whisper.el al respecto: (setq whisper--ffmpeg-input-device ":0") . :0 es el índice de micrófono, consulte la salida del comando anterior para usar otro.
He creado un ayudante de emacs que te permite seleccionar el micrófono interactivamente. Ver esta esencia.
Mi configuración habilitada para el habla completa se parece:
( use-package whisper
:load-path ( lambda () ( expand-file-name " lisp/other-libs/whisper.el " user-emacs-directory))
:config
( setq whisper-model " base "
whisper-language " en "
whisper-translate nil )
( when *is-a-mac*
(rk/select-default-audio-device " Macbook Pro Microphone " )
( when rk/default-audio-device)
( setq whisper--ffmpeg-input-device ( format " : %s " rk/default-audio-device)))) En MacOS, en lugar de Whisper, también puede usar el dictado Siri incorporado. Para habilitar eso, vaya a Preferences -> Keyboard -> Dictation , habilitarlo y configurar un atajo. El valor predeterminado es Ctrl-Ctrl.
La forma (Defun Whisper-Check-Install-and-Run) se implementa no funciona en Win10 (ver #66).
Una solución es instalar whisper.cpp y modelar manualmente y parche:
( defun whisper--check-install-and-run ( buffer status )
(whisper--record-audio)) La salida del habla en los sistemas que no son MACOS predeterminan el uso del paquete Greader que usa espeak debajo para sintetizar el habla. Deberá instalar Greader manualmente (por ejemplo, a través de Mx package-install ). A partir de ese momento, debería "trabajar". Puede probarlo seleccionando algún texto y llamando Mx org-ai-talk-read-region .
Se puede alojar una API para la difusión estable con el proyecto de Difusión Estable-Webui. Realice los pasos de instalación para su plataforma, luego inicie un servidor de API-solo:
cd path/to/stable-diffusion-webui
./webui.sh --nowebui Esto iniciará un servidor en http://127.0.0.1:7861 de forma predeterminada. Para usarlo con Org-AI, debe establecer org-ai-sd-endpoint-base :
( setq org-ai-sd-endpoint-base " http://localhost:7861/sdapi/v1/ " )Si usa un servidor alojado en otro lugar, cambie esa URL en consecuencia.
Dado que la versión 0.4 ORG-AI admite modelos locales atendidos con Oobabooga/Texto-Generación-Webui. Consulte las instrucciones de instalación para configurarlo para su sistema.
Aquí hay un recorrido de configuración que se probó en Ubuntu 22.04. Asume que se instalará Miniconda o Anaconda, así como GIT-LFS.
conda create -n org-ai python=3.10.9
conda activate org-ai
pip3 install torch torchvision torchaudiomkdir -p ~ /.emacs.d/org-ai/
cd ~ /.emacs.d/org-ai/
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
pip install -r requirements.txt Oobabooga/Text-Generation-Webui admite una serie de modelos de idiomas. Normalmente, los instalarías desde Huggingface. Por ejemplo, para instalar el modelo CodeLlama-7b-Instruct :
cd ~ /.emacs.d/org-ai/text-generation-webui/models
git clone [email protected]:codellama/CodeLlama-7b-Instruct-hf cd ~ /.emacs.d/org-ai/text-generation-webui
conda activate org-ai
python server.py --api --model CodeLlama-7b-Instruct-hf Dependiendo de su hardware y el modelo utilizado, es posible que necesite ajustar los parámetros del servidor, por ejemplo, uso --load-in-8bit para reducir el uso de la memoria o --cpu si no tiene una GPU adecuada.
Ahora debería poder usar el modelo local con Org-AI agregando la opción :local al bloque #+begin_ai :
#+begin_ai :local
Hello CodeLlama!
#+end_ai
No, OpenAi es el más fácil de configurar (solo necesita una clave API) pero también puede usar modelos locales. Vea cómo usar difusión estable y LLM locales con Oobabooga/Texto-Generación-Webui arriba. Claude antrópico y perplejidad. Losi también son apoyados. Abra un problema o relaciones públicas para otros servicios que le gustaría ver con el apoyo. Puedo ser lento para responder, pero agregaré apoyo si hay suficiente interés.
El paquete GPTEL proporciona una interfaz alternativa a la API de Operai Chatgpt: https://github.com/karthink/gptel
Si encuentra útil este proyecto, considere patrocinar. ¡Gracias!
Nota: Currenly La implementación de la variación de la imagen requiere que se instale un curl de línea de comando. La razón de eso es que la API de OpenAI espera solicitudes multipart/de datos de forma y el url-retrieve incorporado EMACS no lo admite (al menos no he descubierto cómo). Cambiar a request.el podría ser una mejor alternativa. Si está interesado en contribuir, ¡los PR son bienvenidos! ↩


