org ai
1.0.0
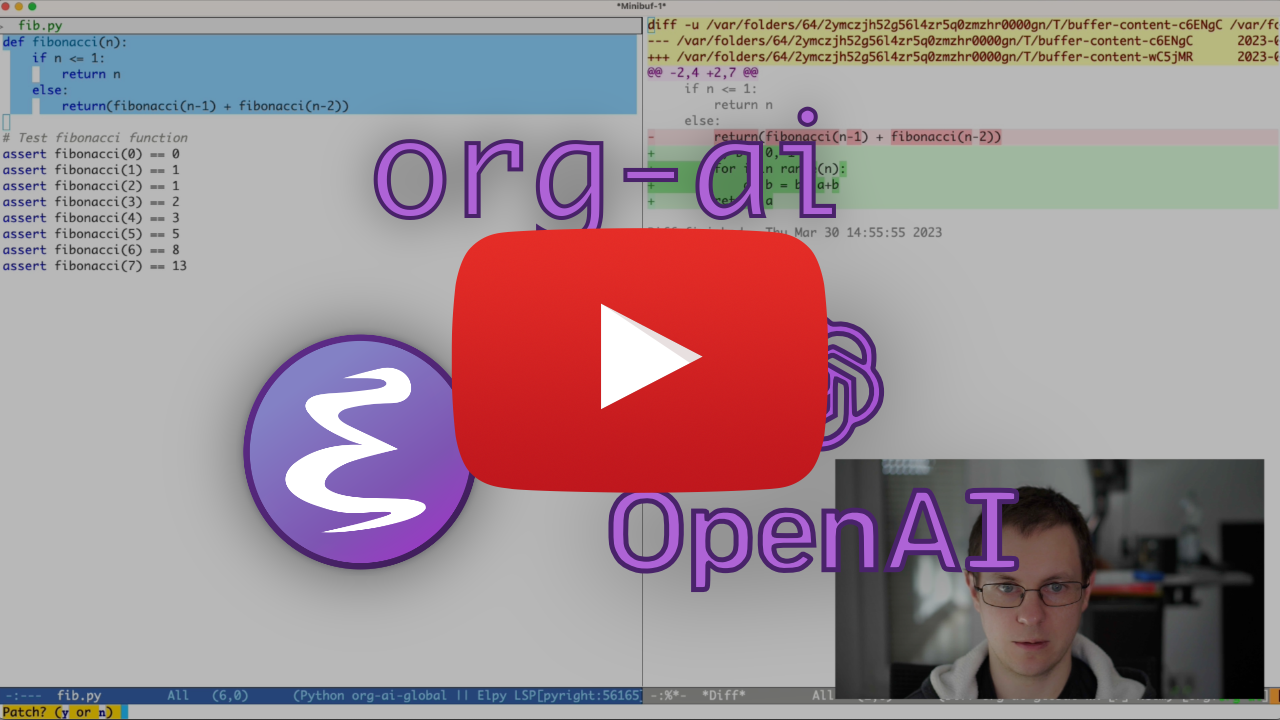
โหมดรองสำหรับโหมด emacs org ที่ให้การเข้าถึงโมเดล AI แบบกำเนิด รองรับในปัจจุบันคือ
ภายในบัฟเฟอร์โหมดองค์กรที่คุณสามารถทำได้
หมายเหตุ: ในการใช้ OpenAI API คุณจะต้องใช้บัญชี OpenAI และคุณต้องได้รับโทเค็น API เท่าที่ฉันสามารถบอกได้ขีด จำกัด การใช้งานปัจจุบันสำหรับระดับฟรีทำให้คุณค่อนข้างไกล
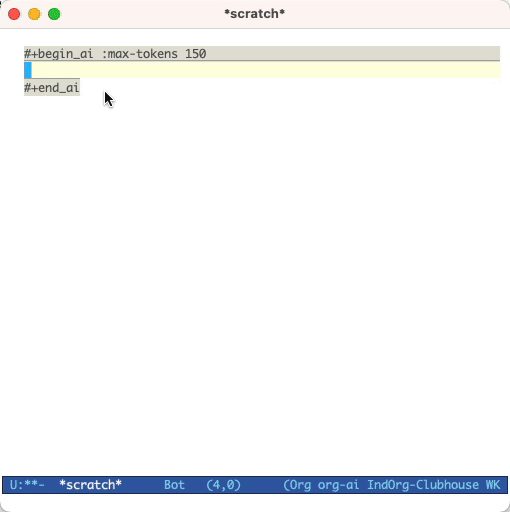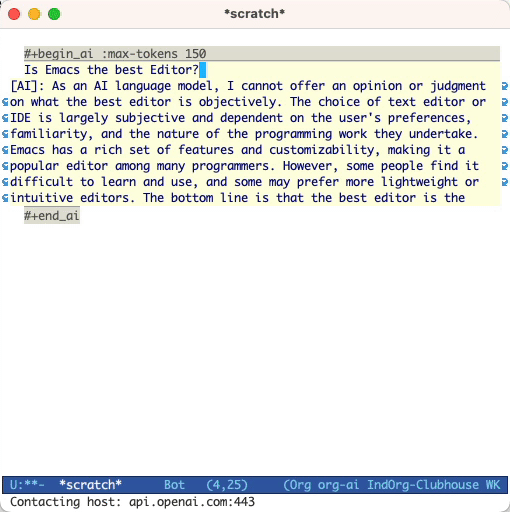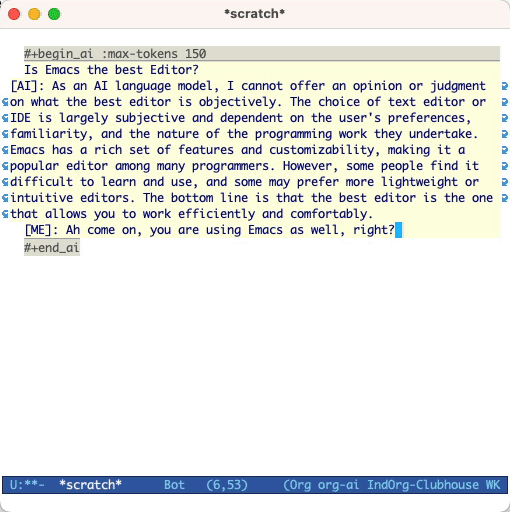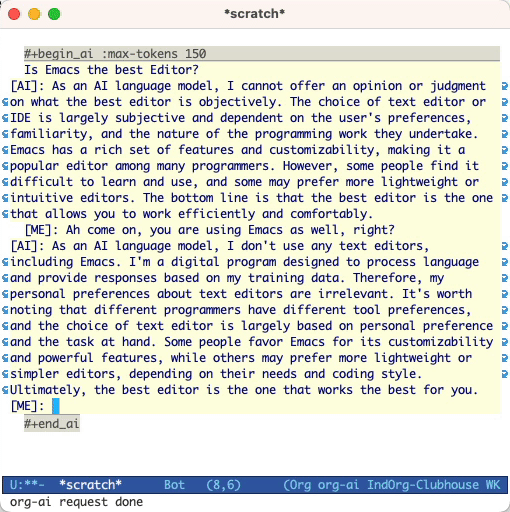
#+begin_ai...#+end_ai บล็อกพิเศษ #+begin_ai
Is Emacs the greatest editor?
#+end_ai
คุณสามารถพิมพ์ต่อไปและกด Cc Cc เพื่อสร้างการสนทนา Cg จะขัดจังหวะคำขอที่กำลังทำงานอยู่
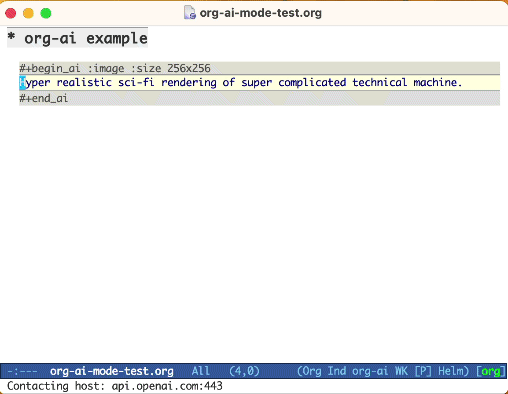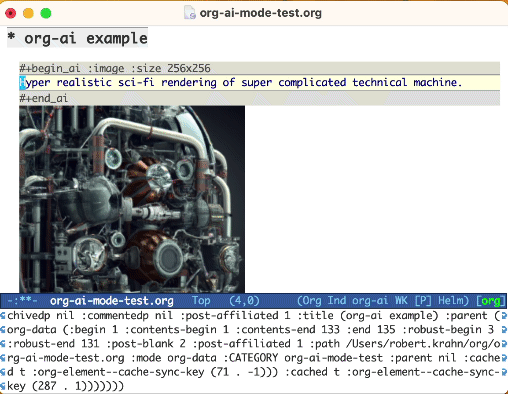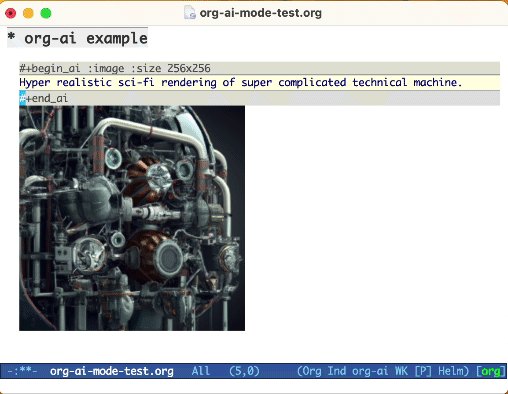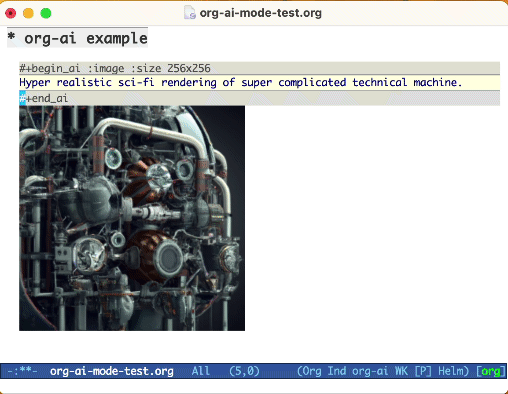
ใช้คำหลัก :image เพื่อสร้างภาพ สิ่งนี้ใช้ Dall · E-3 โดยค่าเริ่มต้น
#+begin_ai :image :size 1024x1024
Hyper realistic sci-fi rendering of super complicated technical machine.
#+end_ai
คุณสามารถใช้คำหลักต่อไปนี้เพื่อควบคุมการสร้างภาพ:
:size <width>x<height> - ขนาดของภาพที่จะสร้าง (ค่าเริ่มต้น: 1024x1024):model <model> -รุ่นที่จะใช้ (ค่าเริ่มต้น: "dall-e-3" ):quality <quality> - คุณภาพของภาพ (ตัวเลือก: hd , standard ):style <style> - สไตล์ที่จะใช้ (ตัวเลือก: vivid natural )(สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการตั้งค่าเหล่านั้นดูโพสต์บล็อก OpenAI นี้
คุณสามารถปรับแต่งค่าเริ่มต้นสำหรับตัวแปรเหล่านั้นด้วย customize-variable หรือโดยการตั้งค่าในการกำหนดค่าของคุณ:
( setq org-ai-image-model " dall-e-3 " )
( setq org-ai-image-default-size " 1792x1024 " )
( setq org-ai-image-default-count 2 )
( setq org-ai-image-default-style 'vivid )
( setq org-ai-image-default-quality 'hd )
( setq org-ai-image-directory ( expand-file-name " org-ai-images/ " org-directory))
#+begin_ai...#+end_ai บล็อกพิเศษเช่นเดียวกับ Org-Babel บล็อกเหล่านี้จะกำหนดอินพุต (และสำหรับ chatgpt ยังเอาต์พุต) สำหรับรุ่น AI คุณสามารถใช้สำหรับการแชท AI การกรอกข้อความและข้อความ -> การสร้างภาพ ดูตัวเลือกด้านล่างสำหรับข้อมูลเพิ่มเติม
สร้างบล็อกเช่น
#+begin_ai
Is Emacs the greatest editor?
#+end_ai
และกด Cc Cc อินพุตการแชทจะปรากฏแบบอินไลน์และเมื่อการตอบกลับเสร็จสมบูรณ์คุณสามารถป้อนคำตอบของคุณและอื่น ๆ ดูการสาธิตด้านล่าง คุณสามารถกด Cg ในขณะที่คำขอ AI กำลังดำเนินการเพื่อยกเลิก
คุณยังสามารถแก้ไขพรอมต์ ระบบ และพารามิเตอร์อื่น ๆ ที่ใช้ พรอมต์ระบบจะถูกฉีดก่อนอินพุตของผู้ใช้และ "primes" โมเดลที่จะตอบในรูปแบบที่แน่นอน ตัวอย่างเช่นคุณสามารถทำได้:
#+begin_ai :max-tokens 250
[SYS]: Act as if you are a powerful medival king.
[ME]: What will you eat today?
#+end_ai
ซึ่งจะส่งผลให้น้ำหนักบรรทุก API เช่น
{
"messages" : [
{
"role" : " system " ,
"content" : " Act as if you are a powerful medival king. "
},
{
"role" : " user " ,
"content" : " What will you eat today? "
}
],
"model" : " gpt-4o-mini " ,
"stream" : true ,
"max_tokens" : 250 ,
"temperature" : 1.2
}สำหรับแนวคิดที่พร้อมท์บางอย่างให้ดูตัวอย่างที่น่ากลัว chatgpt
เมื่อสร้างภาพโดยใช้ :image ภาพจะปรากฏขึ้นใต้บล็อก AI Inline รูปภาพจะถูกจัดเก็บ (พร้อมกับพรอมต์) ภายใน org-ai-image-directory ซึ่งเริ่มต้นเป็น ~/org/org-ai-images/
คุณยังสามารถใช้อินพุตคำพูดเพื่อถอดความอินพุต กด Cc r สำหรับ org-ai-talk-capture-in-org เพื่อเริ่มการบันทึก โปรดทราบว่าสิ่งนี้จะทำให้คุณต้องตั้งค่าการจดจำคำพูด (ดูด้านล่าง) เอาต์พุตคำพูดสามารถเปิดใช้งานได้ด้วย org-ai-talk-output-enable
ภายใน #+begin_ai...#+end_ai คุณสามารถแก้ไขและเลือกชิ้นส่วนของการแชทด้วยคำสั่งเหล่านี้:
Cc <backspace> ( org-ai-kill-region-at-point ) เพื่อลบส่วนแชทภายใต้จุดorg-ai-mark-region-at-point จะทำเครื่องหมายภูมิภาค ณ จุดorg-ai-mark-last-region จะทำเครื่องหมายส่วนแชทสุดท้าย ในการใช้ไวยากรณ์ที่เน้นไปที่ #+begin_ai ... บล็อกเพียงเพิ่มชื่อโหมดหลักของภาษาหลังจาก _ai เช่น #+begin_ai markdown สำหรับ Markdown โดยเฉพาะอย่างยิ่งเพื่อเน้นรหัสอย่างถูกต้องใน backticks คุณสามารถตั้งค่า (setq markdown-fontify-code-blocks-natively t) ตรวจสอบให้แน่ใจว่าคุณติดตั้งแพ็คเกจ markdown-mode ขอบคุณ @tavisrudd สำหรับเคล็ดลับนี้!
พฤติกรรมนี้เปิดใช้งานโดยค่าเริ่มต้นเพื่อให้การโต้ตอบคล้ายกับการแชทมากขึ้น มันอาจจะน่ารำคาญเมื่อมีเอาต์พุตยาวและบัฟเฟอร์เลื่อนในขณะที่คุณกำลังอ่าน ดังนั้นคุณสามารถปิดการใช้งานได้ด้วย:
( setq org-ai-jump-to-end-of-block nil ) Set (setq org-ai-auto-fill t) เป็น "เติม" (ห่อเส้นโดยอัตโนมัติตาม fill-column ) ข้อความที่แทรก โดยทั่วไปเช่น auto-fill-mode แต่สำหรับ AI
#+begin_ai...#+end_ai บล็อกสามารถใช้ตัวเลือกต่อไปนี้
โดยค่าเริ่มต้นเนื้อหาของบล็อก AI จะถูกตีความว่าเป็นข้อความสำหรับ CHATGPT ข้อความต่อไปนี้ [ME]: เชื่อมโยงกับผู้ใช้ข้อความต่อไปนี้ [AI]: เกี่ยวข้องกับการตอบสนองของโมเดล ทางเลือกคุณสามารถเริ่มบล็อกด้วย [SYS]: <behavior> อินพุตไปยัง Prime the Model (ดู org-ai-default-chat-system-prompt ด้านล่าง)
:max-tokens number - จำนวนโทเค็นสูงสุดที่จะสร้าง (ค่าเริ่มต้น: ไม่มีค่าเริ่มต้นของ OpenAI):temperature number - อุณหภูมิของโมเดล (ค่าเริ่มต้น: 1):top-p number - top_p ของรุ่น (ค่าเริ่มต้น: 1):frequency-penalty number - การลงโทษความถี่ของโมเดล (ค่าเริ่มต้น: 0):presence-penalty - การลงโทษการแสดงตนของโมเดล (ค่าเริ่มต้น: 0):sys-everywhere - ทำซ้ำระบบพรอมต์สำหรับทุกข้อความผู้ใช้ (ค่าเริ่มต้น: ไม่มี) หากคุณมีเธรดการสนทนาที่แตกต่างกันมากมายเกี่ยวกับหัวข้อและการตั้งค่าเดียวกัน (พรอมต์ระบบอุณหภูมิ ฯลฯ ) และคุณไม่ต้องการทำซ้ำตัวเลือกทั้งหมดคุณสามารถตั้งค่าคุณสมบัติขอบเขตไฟล์ org ลิ้นชักเช่นทั้งหมด #+begin_ai...#+end_ai บล็อกภายใต้หัวข้อนั้นจะสืบทอดการตั้งค่า
ตัวอย่าง:
* Emacs (multiple conversations re emacs continue in this subtree)
:PROPERTIES:
:SYS: You are a emacs expert. You can help me by answering my questions. You can also ask me questions to clarify my intention.
:temperature: 0.5
:model: gpt-4o-mini
:END:
** Web programming via elisp
#+begin_ai
How to call a REST API and parse its JSON response?
#+end_ai
** Other emacs tasks
#+begin_ai...#+end_ai
* Python (multiple conversations re python continue in this subtree)
:PROPERTIES:
:SYS: You are a python programmer. Respond to the task with detailed step by step instructions and code.
:temperature: 0.1
:model: gpt-4
:END:
** Learning QUIC
#+begin_ai
How to setup a webserver with http3 support?
#+end_ai
** Other python tasks
#+begin_ai...#+end_ai
ตัวแปรที่กำหนดเองต่อไปนี้สามารถใช้ในการกำหนดค่าการแชท:
org-ai-default-chat-model (ค่าเริ่มต้น: "gpt-4o-mini" )org-ai-default-max-tokens ควรใช้เวลานานแค่ไหน ปัจจุบันต้องไม่เกิน 4096 หากค่านี้มีคำตอบเล็กเกินไปอาจถูกตัดออก (ค่าเริ่มต้น: ไม่มี)org-ai-default-chat-system-prompt วิธีการ "สำคัญ" โมเดล นี่คือพรอมต์ที่ถูกฉีดก่อนอินพุตของผู้ใช้ (ค่าเริ่มต้น: "You are a helpful assistant inside Emacs." )org-ai-default-inject-sys-prompt-for-all-messages จะทำซ้ำระบบพรอมต์สำหรับข้อความผู้ใช้ทุกข้อความ บางครั้งโมเดล "ลืม" มันเป็นวิธีการเตรียมไว้ สิ่งนี้สามารถช่วยเตือนได้ (ค่าเริ่มต้น: nil ) เมื่อคุณเพิ่ม :image ลงในบล็อก AI พรอมต์จะถูกใช้สำหรับการสร้างภาพ
:image - สร้างภาพแทนข้อความ:size - ขนาดของภาพที่จะสร้าง (ค่าเริ่มต้น: 256x256 สามารถเป็น 512x512 หรือ 1024x1024):n - จำนวนรูปภาพที่จะสร้าง (ค่าเริ่มต้น: 1)ตัวแปรที่กำหนดเองต่อไปนี้สามารถใช้เพื่อกำหนดค่าการสร้างภาพ:
org-ai-image-directory สถานที่จัดเก็บภาพที่สร้างขึ้น (ค่าเริ่มต้น: ~/org/org-ai-images/ ) คล้ายกับ Dall-e แต่ใช้
#+begin_ai :sd-image
<PROMPT>
#+end_ai
คุณสามารถเรียกใช้ IMG2IMG โดยการติดฉลากอิมเมจโหมดองค์กรของคุณด้วยชื่อ #+และอ้างอิงด้วย: image-ref จากบล็อก org-ai ของคุณ
#+begin_ai :sd-image :image-ref label1
forest, Gogh style
#+end_ai
MX org-ai-sd-clip คาดเดาพรอมต์ของภาพก่อนหน้าในโหมด org โดย clip interrogator และบันทึกไว้ในแหวนฆ่า
MX org-ai-sd-deepdanbooru เดาว่าภาพก่อนหน้าของภาพก่อนหน้าในโหมด org โดย DeepDanBooru Interrogator และบันทึกไว้ในแหวนฆ่า
สำหรับการร้องขอความสำเร็จจากรุ่นท้องถิ่นที่เสิร์ฟพร้อมกับ Oobabooga/Text-Generation-Webui ให้ผ่านขั้นตอนการตั้งค่าที่อธิบายไว้ด้านล่าง
จากนั้นเริ่มเซิร์ฟเวอร์ API:
cd ~ /.emacs.d/org-ai/text-generation-webui
conda activate org-ai
python server.py --api --model SOME-MODEL เมื่อคุณเพิ่ม A :local ลงในบล็อก ORG-AI และขอความสมบูรณ์ด้วย Cc Cc บล็อกจะถูกส่งไปยังเซิร์ฟเวอร์ API ท้องถิ่นแทน OpenAI API ตัวอย่างเช่น:
#+begin_ai :local
...
#+end_ai
สิ่งนี้จะส่งคำขอไปยัง org-ai-oobabooga-websocket-url และสตรีมการตอบกลับไปยังบัฟเฟอร์ org
รุ่นที่เสร็จสมบูรณ์แบบเก่าสามารถได้รับแจ้งโดยการเพิ่ม :completion ในบล็อก AI
:completion - แทนที่จะใช้โมเดล chatgpt ให้ใช้โมเดลที่สมบูรณ์:model - โมเดลที่จะใช้ดู https://platform.openai.com/docs/models สำหรับรายการรุ่นสำหรับความหมายโดยละเอียดของพารามิเตอร์เหล่านั้นดูเอกสาร OpenAI API
ตัวแปรที่กำหนดเองต่อไปนี้สามารถใช้เพื่อกำหนดค่าการสร้างข้อความ:
org-ai-default-completion-model (ค่าเริ่มต้น: "text-davinci-003" ) คุณยังสามารถใช้ภาพที่มีอยู่เป็นอินพุตเพื่อสร้างภาพที่ดูคล้ายกันมากขึ้น คำสั่ง org-ai-image-variation จะแจ้งให้เส้นทางไฟล์ไปยังรูปภาพขนาดและการนับจากนั้นจะสร้างภาพจำนวนมากและแทรกลิงก์ไปยังพวกเขาภายในบัฟเฟอร์ org-mode ปัจจุบัน รูปภาพจะถูกเก็บไว้ภายใน org-ai-image-directory ดูการสาธิตด้านล่าง
สำหรับข้อมูลเพิ่มเติมโปรดดูเอกสาร OpenAI ภาพอินพุตต้องเป็นสี่เหลี่ยมและขนาดของมันจะต้องน้อยกว่า 4MB และขณะนี้คุณต้องการ Curl เป็นเครื่องมือบรรทัดคำสั่ง 1
org-ai สามารถใช้นอกบัฟเฟอร์ org-mode ได้เช่นกัน เมื่อคุณเปิดใช้งาน org-ai-global-mode , คำนำหน้า Cc Ma จะถูกผูกไว้กับจำนวนคำสั่ง:
| สั่งการ | การคีย์ | คำอธิบาย |
|---|---|---|
org-ai-on-region | Cc Ma r | ถามคำถามเกี่ยวกับข้อความที่เลือกหรือบอกให้ AI ทำอะไรบางอย่างกับมัน การตอบกลับจะเปิดในบัฟเฟอร์โหมดองค์กรเพื่อให้คุณสามารถสนทนาต่อไปได้ การตั้งค่าตัวแปร org-ai-on-region-file (เช่น (setq org-ai-on-region-file (expand-file-name "org-ai-on-region.org" org-directory)) ) จะเชื่อมโยง ไฟล์ที่มีบัฟเฟอร์นั้น |
org-ai-summarize | Cc Ma s | สรุปข้อความที่เลือก |
org-ai-refactor-code | Cc Ma c | บอก AI ถึงวิธีการเปลี่ยนรหัสที่เลือกบัฟเฟอร์ DIFF จะปรากฏขึ้นพร้อมกับการเปลี่ยนแปลง |
org-ai-on-project | Cc Ma p | เรียกใช้พรอมต์และแก้ไข / refactor หลายไฟล์ในครั้งเดียว จะใช้กระสุนปืนถ้ามีให้กลับไปที่ไดเรกทอรีปัจจุบันถ้าไม่ |
org-ai-prompt | Cc Ma P | แจ้งให้ผู้ใช้สำหรับข้อความจากนั้นพิมพ์การตอบสนองของ AI ในบัฟเฟอร์ปัจจุบัน |
org-ai-switch-chat-model | Cc Ma m | เปลี่ยนแบบโต้ตอบ org-ai-default-chat-model |
org-ai-open-account-usage-page | Cc Ma $ | เปิด https://platform.openai.com/account/usage เพื่อดูว่าคุณถูกเผาเงินเท่าไหร่ |
org-ai-open-request-buffer | Cc Ma ! | เปิดบัฟเฟอร์คำขอ url หากสิ่งที่ไม่ทำงานอาจเป็นประโยชน์ในการดู |
org-ai-talk-input-toggle | Cc Ma t | โดยทั่วไปเปิดใช้งานอินพุตคำพูดสำหรับคำสั่งพรอมต์ที่แตกต่างกัน |
org-ai-talk-output-toggle | Cc Ma T | โดยทั่วไปเปิดใช้งานผลลัพธ์การพูด |
การใช้บัฟเฟอร์ Org-on-on-Project ช่วยให้คุณสามารถเรียกใช้คำสั่งบนไฟล์ในโครงการหรือเพียงแค่ในข้อความที่เลือกในไฟล์เหล่านั้น คุณสามารถเลือก readme ของโครงการและถามว่า "มันเกี่ยวกับอะไร?" หรือมีรหัสอธิบายให้คุณทราบ คุณยังสามารถขอการเปลี่ยนแปลงรหัสซึ่งจะสร้างความแตกต่าง หากคุณรู้ว่าใครคิดว่ามีเพียงรหัสเทียบกับรหัสที่เปิดใช้งาน Copilot สามารถทำได้ให้ชี้ไปที่นี่
การรันคำสั่ง org-ai-on-project จะเปิดบัฟเฟอร์แยกต่างหากที่ช่วยให้คุณเลือกเลือกหลายไฟล์ (และเลือกเลือกภูมิภาคย่อยภายในไฟล์) จากนั้นเรียกใช้พรอมต์
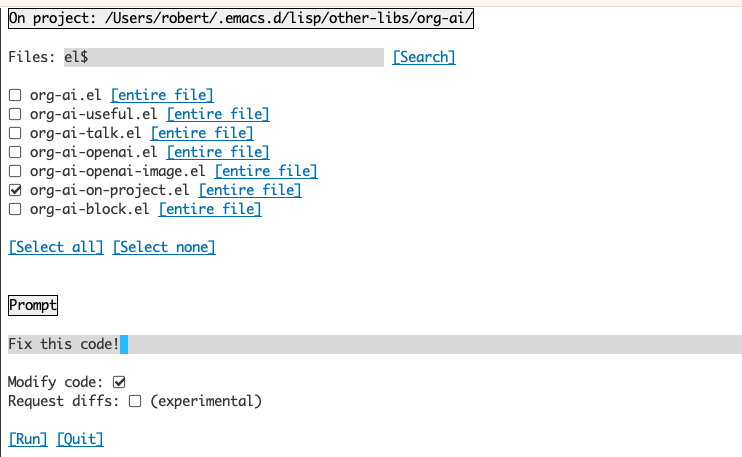
หากคุณปิดการใช้งาน "แก้ไขรหัส" เอฟเฟกต์จะคล้ายกับการรัน org-ai-on-region เพียงว่าเนื้อหาไฟล์ทั้งหมดจะปรากฏในพรอมต์
ด้วยการเปิดใช้งาน "Modify Code" คุณสามารถขอให้ AI แก้ไขหรือ refactor รหัส โดยค่าเริ่มต้น ("คำขอ diffs") ปิดการใช้งานเราจะแจ้งให้สร้างรหัสใหม่สำหรับไฟล์/ภูมิภาคที่เลือกทั้งหมดและจากนั้นคุณสามารถดู diff ต่อไฟล์และตัดสินใจที่จะใช้หรือไม่ ด้วยการใช้งาน "คำขอ diffs" AI จะถูกขอให้สร้าง Diff Unified ที่สามารถนำไปใช้โดยตรงได้
ได้รับบล็อกต้นทางที่มีชื่อ
#+name: sayhi
#+begin_src shell
echo "Hello there"
#+end_src
เราสามารถลองอ้างอิงด้วยชื่อ แต่มันไม่ได้ผล
#+begin_ai
[SYS]: You are a mimic. Whenever I say something, repeat back what I say to you. Say exactly what I said, do not add anything.
[ME]: <<sayhi()>>
[AI]: <<sayhi()>>
[ME]:
#+end_ai
กับ :noweb yes
#+begin_ai :noweb yes
[SYS]: You are a mimic. Whenever I say something, repeat back what I say to you. Say exactly what I said, do not add anything.
[ME]: <<sayhi()>>
[AI]: Hello there.
[ME]:
#+end_ai
นอกจากนี้คุณยังสามารถกระตุ้นการขยายตัวของ Noweb ด้วย org-ai-noweb: yes หัวเรื่องที่เป็นอยู่ทุกที่ในส่วนหัวแม่ (ส่วนหัว args มีความสำคัญกว่า)
หากต้องการดูว่าเอกสารของคุณจะขยายไปยัง API อย่างไรให้เรียกใช้ org-ai-expand-block
นี่คือแฮ็ค แต่ใช้งานได้ดีจริงๆ
สร้างบล็อก
#+name: identity
#+begin_src emacs-lisp :var x="fill me in"
(format "%s" x)
#+end_src
เราสามารถเรียกใช้และปล่อยให้พารามิเตอร์ Noweb (ซึ่งรองรับ LISP) ประเมินเป็นรหัส
#+begin_ai :noweb yes
Tell me some 3, simple ways to improve this dockerfile
<<identity(x=(quelpa-slurp-file "~/code/ibr-api/Dockerfile"))>>
[AI]: 1. Use a more specific version of Python, such as "python:3.9.6-buster" instead of "python:3.9-buster", to ensure compatibility with future updates.
2. Add a cleanup step after installing poetry to remove any unnecessary files or dependencies, thus reducing the size of the final image.
3. Use multi-stage builds to separate the build environment from the production environment, thus reducing the size of the final image and increasing security. For example, the first stage can be used to install dependencies and build the code, while the second stage can contain only the final artifacts and be used for deployment.
[ME]:
#+end_ai
org-ai อยู่ใน Melpa: https://melpa.org/#/org-ai หากคุณได้เพิ่ม Melpa ลงในคลังเก็บแพ็คเกจของคุณด้วย
( require 'package )
( add-to-list 'package-archives '( " melpa " . " http://melpa.org/packages/ " ) t )
( package-initialize )คุณสามารถติดตั้งด้วย:
( use-package org-ai
:ensure t
:commands (org-ai-mode
org-ai-global-mode)
:init
( add-hook 'org-mode-hook # 'org-ai-mode ) ; enable org-ai in org-mode
(org-ai-global-mode) ; installs global keybindings on C-c M-a
:config
( setq org-ai-default-chat-model " gpt-4 " ) ; if you are on the gpt-4 beta:
(org-ai-install-yasnippets)) ; if you are using yasnippet and want `ai` snippets
( straight-use-package
'(org-ai :type git :host github :repo " rksm/org-ai "
:local-repo " org-ai "
:files ( " *.el " " README.md " " snippets " )))ชำระเงินที่เก็บนี้
git clone
https://github.com/rksm/org-ai จากนั้นถ้าคุณใช้ use-package :
( use-package org-ai
:ensure t
:load-path ( lambda () " path/to/org-ai " ))
; ; ...rest as above...
หรือเพียงแค่ require :
( package-install 'websocket )
( add-to-list 'load-path " path/to/org-ai " )
( require 'org )
( require 'org-ai )
( add-hook 'org-mode-hook # 'org-ai-mode )
(org-ai-global-mode)
( setq org-ai-default-chat-model " gpt-4 " ) ; if you are on the gpt-4 beta:
(org-ai-install-yasnippets) ; if you are using yasnippet and want `ai` snippetsคุณสามารถตั้งค่าโทเค็น API ของคุณโดยตรงในการกำหนดค่าของคุณ:
( setq org-ai-openai-api-token " <ENTER YOUR API TOKEN HERE> " )
อีกทางเลือกหนึ่ง org-ai สนับสนุนการรับรอง auth-source สำหรับการดึงรหัส API ของคุณ คุณสามารถเก็บความลับในรูปแบบ
machine api.openai.com login org-ai password <your-api-key>
ในไฟล์ ~/authinfo.gpg ของคุณ หากมีอยู่ Org-AI จะใช้กลไกนี้เพื่อดึงโทเค็นเมื่อมีการร้องขอ หากคุณไม่ต้องการให้ org-ai พยายามดึงคีย์จาก auth-source คุณสามารถตั้งค่า org-ai-use-auth-source เป็น nil ก่อนที่จะโหลด org-ai
คุณสามารถเปลี่ยนเป็น Azure ได้โดยการปรับแต่งตัวแปรเหล่านี้ไม่ว่าจะเป็นแบบโต้ตอบกับ Mx customize-variable หรือโดยการเพิ่มลงในการกำหนดค่าของคุณ:
( setq org-ai-service 'azure-openai
org-ai-azure-openai-api-base " https://your-instance.openai.azure.com "
org-ai-azure-openai-deployment " azure-openai-deployment-name "
org-ai-azure-openai-api-version " 2023-07-01-preview " ) ในการจัดเก็บข้อมูลรับรอง API ให้ทำตามคำแนะนำ Authinfo ด้านบน แต่ใช้ org-ai-azure-openai-api-base เป็นชื่อเครื่อง
สำหรับรายการของรุ่นที่มีอยู่ดูเอกสาร Perplexity.AI
สลับบริการเริ่มต้นในการกำหนดค่าของคุณ:
( setq org-ai-service 'perplexity .ai)
( setq org-ai-default-chat-model " llama-3-sonar-large-32k-online " )หรือต่อบล็อก:
#+begin_ai :service perplexity.ai :model llama-3-sonar-large-32k-online
[ME]: Tell me fun facts about Emacs.
#+end_ai
สำหรับการรับรองความถูกต้องมีรายการเช่น machine api.perplexity.ai login org-ai password pplx-*** ใน authinfo.gpg ของคุณหรือตั้ง org-ai-openai-api-token ของคุณ
หมายเหตุ: ปัจจุบัน perplexity.ai ไม่ให้การเข้าถึงการอ้างอิง/ลิงก์ผ่าน API ดังนั้น Emacs จะไม่สามารถแสดงการอ้างอิงได้ พวกเขามีโปรแกรมเบต้าสำหรับการทำงานนั้นและฉันหวังว่าจะมีให้โดยทั่วไปในไม่ช้า
คล้ายกับข้างต้น เช่น
#+begin_ai :service anthropic :model claude-3-opus-20240229
[ME]: Tell me fun facts about Emacs.
#+end_ai
โมเดลมานุษยวิทยาอยู่ที่นี่ ขณะนี้มีเพียงรุ่น API เดียวที่ตั้งค่าผ่าน org-ai-anthropic-api-version หากเวอร์ชันอื่นออกมาคุณสามารถค้นหาได้ที่นี่
สำหรับโทเค็น API ใช้ machine api.anthropic.com login org-ai password sk-ant-*** ใน authinfo.gpg ของคุณ
ขั้นตอนการตั้งค่าเหล่านี้เป็นทางเลือก หากคุณไม่ต้องการใช้คำพูด / เอาต์พุตคุณสามารถข้ามส่วนนี้ได้
หมายเหตุ: การกำหนดค่าส่วนบุคคลของฉันสำหรับ org-ai สามารถพบได้ในส่วนสำคัญนี้ มันมีการตั้งค่ากระซิบที่ใช้งานได้
สิ่งนี้ได้รับการทดสอบใน MacOS และ Linux คนที่มีคอมพิวเตอร์ Windows โปรดทดสอบสิ่งนี้และแจ้งให้เราทราบว่าต้องทำอะไรเพื่อให้มันใช้งานได้ (ขอบคุณ!)
อินพุตคำพูดใช้ Whisper.el และ ffmpeg คุณต้องโคลน repo โดยตรงหรือใช้ straight.el เพื่อติดตั้ง
brew install ffmpeg บน MACOS) หรือ sudo apt install ffmpeg บน Linuxgit clone https://github.com/natrys/whisper.el path/to/whisper.elตอนนี้คุณควรจะสามารถโหลดภายใน emacs:
( use-package whisper
:load-path " path/to/whisper.el "
:bind ( " M-s-r " . whisper-run))ตอนนี้โหลดด้วย:
( use-package greader :ensure )
( require 'whisper )
( require 'org-ai-talk )
; ; macOS speech settings, optional
( setq org-ai-talk-say-words-per-minute 210 )
( setq org-ai-talk-say-voice " Karen " )บน macOS คุณจะต้องทำอีกสองสิ่ง:
คุณสามารถใช้ Tccutil Helper:
git clone https://github.com/DocSystem/tccutil
cd tccutil
sudo python ./tccutil.py -p /Applications/Emacs.app -e --microphone เมื่อคุณเรียกใช้ ffmpeg -f avfoundation -i :0 output.mp3 จากภายในเปลือก emacs ไม่ควรมีกับ abort trap: 6 ข้อผิดพลาด
(เป็นทางเลือกแทน tccutil.py ดูวิธีการที่กล่าวถึงในปัญหานี้)
คุณสามารถใช้เอาต์พุตของ ffmpeg -f avfoundation -list_devices true -i "" เพื่อแสดงรายการอุปกรณ์อินพุตเสียงแล้วบอก Whisper.el เกี่ยวกับเรื่องนี้: (setq whisper--ffmpeg-input-device ":0") :0 คือดัชนีไมโครโฟนดูเอาต์พุตของคำสั่งด้านบนเพื่อใช้อีกอันหนึ่ง
ฉันได้สร้างตัวช่วย Emacs ที่ให้คุณเลือกไมโครโฟนแบบโต้ตอบ ดูส่วนสำคัญนี้
คำพูดเต็มของฉันเปิดใช้งานการกำหนดค่าแล้วดูเหมือนว่า:
( use-package whisper
:load-path ( lambda () ( expand-file-name " lisp/other-libs/whisper.el " user-emacs-directory))
:config
( setq whisper-model " base "
whisper-language " en "
whisper-translate nil )
( when *is-a-mac*
(rk/select-default-audio-device " Macbook Pro Microphone " )
( when rk/default-audio-device)
( setq whisper--ffmpeg-input-device ( format " : %s " rk/default-audio-device)))) บน MacOS แทนที่จะเป็น Whisper คุณสามารถใช้การเขียนตามคำบอกของ Siri ในตัว หากต้องการเปิดใช้งานให้ไปที่ Preferences -> Keyboard -> Dictation เปิดใช้งานและตั้งค่าทางลัด ค่าเริ่มต้นคือ ctrl-ctrl
วิธี (defun Whisper-ตรวจสอบการติดตั้งและวิ่ง) ไม่ทำงานบน Win10 (ดู #66)
วิธีแก้ปัญหาคือการติดตั้ง whisper.cpp และโมเดลด้วยตนเองและแพตช์:
( defun whisper--check-install-and-run ( buffer status )
(whisper--record-audio)) เอาต์พุตคำพูดบนระบบที่ไม่ใช่มาแมคัลค่าเริ่มต้นในการใช้แพ็คเกจ Greader ซึ่งใช้ espeak ใต้เพื่อสังเคราะห์คำพูด คุณจะต้องติดตั้ง Greader ด้วยตนเอง (เช่นผ่าน Mx package-install ) จากจุดนั้นมันควร "แค่ทำงาน" คุณสามารถทดสอบได้โดยเลือกข้อความและเรียก Mx org-ai-talk-read-region
API สำหรับการแพร่กระจายที่เสถียรสามารถโฮสต์ด้วยโครงการที่มีความเสถียร diffusion-webui ทำตามขั้นตอนการติดตั้งสำหรับแพลตฟอร์มของคุณจากนั้นเริ่มเซิร์ฟเวอร์ API เท่านั้น:
cd path/to/stable-diffusion-webui
./webui.sh --nowebui สิ่งนี้จะเริ่มต้นเซิร์ฟเวอร์บน http://127.0.0.1:7861 โดยค่าเริ่มต้น ในการใช้งานกับ Org-AI คุณต้องตั้งค่า org-ai-sd-endpoint-base :
( setq org-ai-sd-endpoint-base " http://localhost:7861/sdapi/v1/ " )หากคุณใช้เซิร์ฟเวอร์โฮสต์ที่อื่นให้เปลี่ยน URL นั้นตามนั้น
เนื่องจากเวอร์ชัน 0.4 org-ai รองรับรุ่นท้องถิ่นที่เสิร์ฟพร้อมกับ Oobabooga/Text-Generation-Webui ดูคำแนะนำการติดตั้งเพื่อตั้งค่าสำหรับระบบของคุณ
นี่คือการตั้งค่าการเดินผ่านที่ได้รับการทดสอบใน Ubuntu 22.04 มันถือว่า Miniconda หรือ Anaconda รวมถึง GIT-LFS ที่จะติดตั้ง
conda create -n org-ai python=3.10.9
conda activate org-ai
pip3 install torch torchvision torchaudiomkdir -p ~ /.emacs.d/org-ai/
cd ~ /.emacs.d/org-ai/
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
pip install -r requirements.txt Oobabooga/Text-Generation-Webui รองรับรูปแบบภาษาจำนวนหนึ่ง โดยปกติคุณจะติดตั้งจาก HuggingFace ตัวอย่างเช่นในการติดตั้งโมเดล CodeLlama-7b-Instruct :
cd ~ /.emacs.d/org-ai/text-generation-webui/models
git clone [email protected]:codellama/CodeLlama-7b-Instruct-hf cd ~ /.emacs.d/org-ai/text-generation-webui
conda activate org-ai
python server.py --api --model CodeLlama-7b-Instruct-hf ขึ้นอยู่กับฮาร์ดแวร์ของคุณและรุ่นที่ใช้คุณอาจต้องปรับพารามิเตอร์เซิร์ฟเวอร์เช่นการใช้ --load-in-8bit เพื่อลดการใช้หน่วยความจำหรือ --cpu หากคุณไม่มี GPU ที่เหมาะสม
ตอนนี้คุณควรใช้โมเดลท้องถิ่นกับ Org-AI โดยการเพิ่ม :local ในบล็อก #+begin_ai :
#+begin_ai :local
Hello CodeLlama!
#+end_ai
ไม่ OpenAI เป็นวิธีที่ง่ายที่สุดในการตั้งค่า (คุณต้องการคีย์ API เท่านั้น) แต่คุณสามารถใช้โมเดลท้องถิ่นได้เช่นกัน ดูวิธีการใช้การแพร่กระจายที่เสถียรและ LLM ในท้องถิ่นด้วย Oobabooga/Text-Generation-Webui ด้านบน นอกจากนี้ยังได้รับการสนับสนุนมานุษยวิทยา claude และ perplexity.ai กรุณาเปิดปัญหาหรือประชาสัมพันธ์สำหรับบริการอื่น ๆ ที่คุณต้องการดูที่ได้รับการสนับสนุน ฉันสามารถตอบกลับได้ช้า แต่จะเพิ่มการสนับสนุนหากมีความสนใจเพียงพอ
แพ็คเกจ GPTEL จัดเตรียมอินเทอร์เฟซทางเลือกให้กับ OpenAI chatgpt API: https://github.com/karthink/gptel
หากคุณพบว่าโครงการนี้มีประโยชน์โปรดพิจารณาการสนับสนุน ขอบคุณ!
หมายเหตุ: การใช้งานการแปรผันของภาพต้องใช้เส้นขั้วคำสั่งที่จะติดตั้ง เหตุผลก็คือ OpenAI API คาดว่าจะมีการร้องขอแบบหลายส่วน/ฟอร์มข้อมูลและ EMACS- url-retrieve ในตัวไม่สนับสนุน (อย่างน้อยฉันก็ไม่ได้คิดว่าจะทำอย่างไร) การสลับไปที่ request.el อาจเป็นทางเลือกที่ดีกว่า หากคุณสนใจที่จะมีส่วนร่วม PRS ยินดีต้อนรับมาก!


