โปรเจ็กต์นี้ใช้โมเดล GPT เพื่อแยกวิเคราะห์ไฟล์ PDF อย่างชาญฉลาด และจัดการเนื้อหาที่ซับซ้อน เช่น การเรียงพิมพ์ สูตรทางคณิตศาสตร์ ตาราง รูปภาพ และแผนภูมิได้อย่างมีประสิทธิภาพ ข้อได้เปรียบหลักอยู่ที่ความแม่นยำสูงและค่าใช้จ่ายในการแยกวิเคราะห์เฉลี่ยเพียง 0.013 ดอลลาร์ต่อหน้า ซึ่งช่วยปรับปรุงประสิทธิภาพการประมวลผล PDF ได้อย่างมาก โซลูชันต้นทุนต่ำและประสิทธิภาพสูงนี้มีคุณค่าในทางปฏิบัติสูงมากสำหรับผู้ใช้หรือธุรกิจที่ต้องการประมวลผลเอกสาร PDF จำนวนมาก โปรเจ็กต์นี้ใช้ไลบรารี PyMuPDF สำหรับการแยกวิเคราะห์เบื้องต้น รวมกับโมเดลภาพขนาดใหญ่ (เช่น GPT-4) สำหรับการประมวลผลเชิงลึก และสุดท้ายก็สร้างไฟล์ Markdown ที่แก้ไขและใช้งานได้ง่าย ต่อไปนี้เป็นขั้นตอนโดยละเอียด:
โปรเจ็กต์ Github นี้ใช้โมเดล GPT เพื่อแยกวิเคราะห์ไฟล์ PDF ซึ่งสามารถแยกวิเคราะห์เค้าโครง สูตรทางคณิตศาสตร์ ตาราง รูปภาพ แผนภูมิ และเนื้อหาอื่นๆ ในรูปแบบ PDF ได้อย่างสมบูรณ์แบบ โดยมีค่าใช้จ่ายต่อหน้าเฉลี่ย 0.013 ดอลลาร์ ขั้นตอนในการแยกวิเคราะห์ไฟล์ PDF มีดังนี้: 1. ใช้ไลบรารี PyMuPDF เพื่อแยกวิเคราะห์ PDF ในพื้นที่ที่ไม่ใช่ข้อความและพื้นที่ข้อความ
ใช้ไลบรารี PyMuPDF เพื่อแยกวิเคราะห์ PDF ลงในพื้นที่ที่ไม่ใช่ข้อความและพื้นที่ข้อความ และใช้โมเดลการแสดงภาพขนาดใหญ่ เช่น GPT-4o เพื่อแยกวิเคราะห์และรับไฟล์ Markdown 2. ใช้โมเดลการแสดงภาพขนาดใหญ่ (เช่น GPT-4o) เพื่อแยกวิเคราะห์และรับไฟล์ Markdown
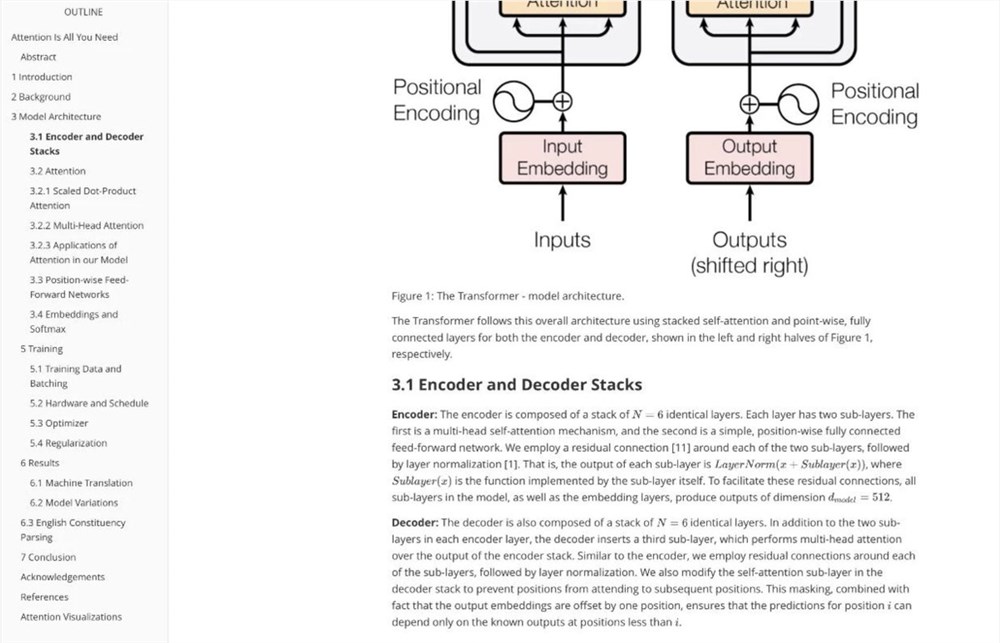
โปรเจ็กต์นี้ใช้เทคโนโลยี AI ขั้นสูงเพื่อมอบโซลูชันใหม่สำหรับการประมวลผลเอกสาร PDF ซึ่งช่วยลดต้นทุนและปรับปรุงประสิทธิภาพได้อย่างมาก ผู้ใช้ที่สนใจสามารถไปที่ Github เพื่อดูรายละเอียดโครงการและสัมผัสกับฟังก์ชันการแยกวิเคราะห์ PDF ที่มีประสิทธิภาพและสะดวกสบาย ในอนาคต โปรเจ็กต์นี้คาดว่าจะมีการใช้กันอย่างแพร่หลายมากขึ้นในด้านต่างๆ เช่น การดึงข้อมูลและการทำเอกสารอัตโนมัติ