Este projeto usa o modelo GPT para realizar a análise inteligente de arquivos PDF e lidar com eficiência com conteúdo complexo, como composição tipográfica, fórmulas matemáticas, tabelas, imagens e gráficos. Sua principal vantagem reside na alta precisão e no custo médio de análise de apenas US$ 0,013 por página, o que melhora muito a eficiência do processamento de PDF. Esta solução de baixo custo e alta eficácia tem um valor prático extremamente elevado para usuários ou empresas que precisam processar um grande número de documentos PDF. Este projeto utiliza a biblioteca PyMuPDF para análise inicial, combinada com grandes modelos visuais (como GPT-4) para processamento aprofundado e, finalmente, gera arquivos Markdown que são fáceis de editar e usar. A seguir estão as etapas detalhadas:
Este projeto Github usa o modelo GPT para analisar arquivos PDF, que pode analisar perfeitamente o layout, fórmulas matemáticas, tabelas, imagens, gráficos e outros conteúdos em PDF, com um custo médio por página de US$ 0,013. As etapas para analisar arquivos PDF são as seguintes: 1. Use a biblioteca PyMuPDF para analisar PDF em áreas sem texto e áreas de texto.
Use a biblioteca PyMuPDF para analisar PDF em áreas não textuais e áreas de texto e use grandes modelos de visualização, como GPT-4o, para analisar e obter arquivos Markdown. 2. Use um modelo de visualização grande (como GPT-4o) para analisar e obter arquivos Markdown.
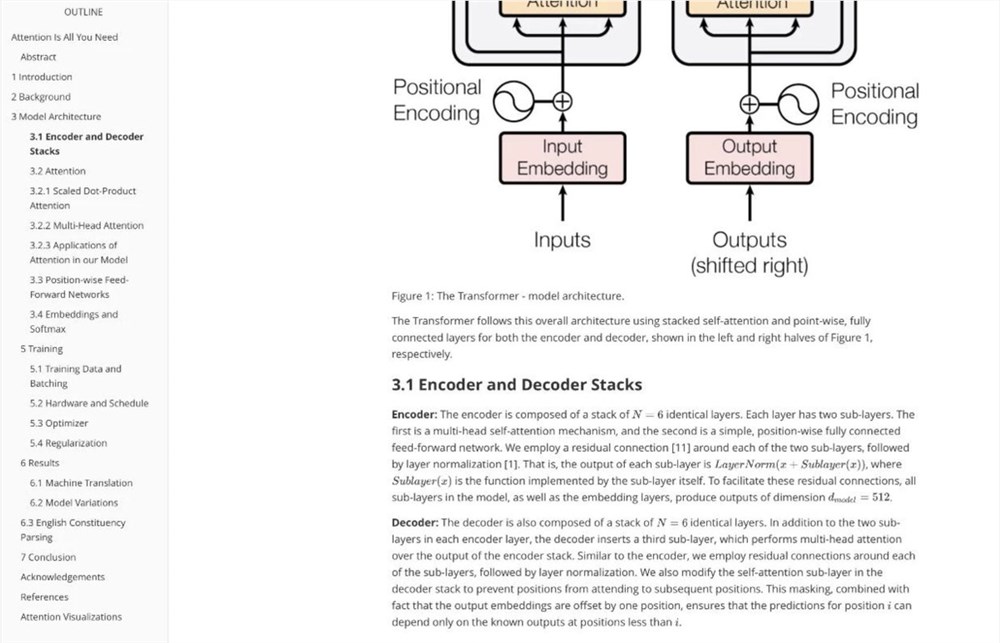
Este projeto utiliza tecnologia avançada de IA para fornecer novas soluções para processamento de documentos PDF, reduzindo significativamente os custos e melhorando a eficiência. Os usuários interessados podem acessar o Github para visualizar os detalhes do projeto e experimentar sua função eficiente e conveniente de análise de PDF. No futuro, espera-se que este projeto seja mais amplamente utilizado em áreas como extração de dados e automação de documentos.