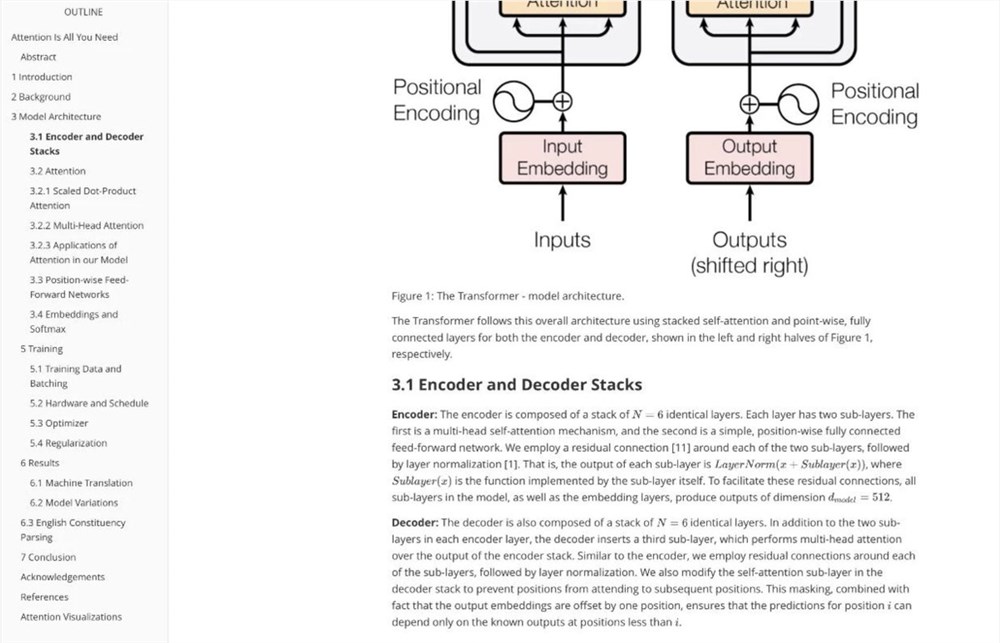
Proyek ini menggunakan model GPT untuk mewujudkan penguraian file PDF yang cerdas dan secara efisien menangani konten kompleks seperti penyusunan huruf, rumus matematika, tabel, gambar, dan bagan. Keunggulan intinya terletak pada akurasi tinggi dan biaya penguraian rata-rata hanya $0,013 per halaman, yang sangat meningkatkan efisiensi pemrosesan PDF. Solusi berbiaya rendah dan sangat efektif ini memiliki nilai praktis yang sangat tinggi bagi pengguna atau bisnis yang perlu memproses dokumen PDF dalam jumlah besar. Proyek ini menggunakan perpustakaan PyMuPDF untuk parsing awal, dikombinasikan dengan model visual besar (seperti GPT-4) untuk pemrosesan mendalam, dan akhirnya menghasilkan file Markdown yang mudah diedit dan digunakan. Berikut langkah-langkah detailnya:
Proyek Github ini menggunakan model GPT untuk mengurai file PDF, yang dapat dengan sempurna mengurai tata letak, rumus matematika, tabel, gambar, bagan, dan konten lainnya dalam PDF, dengan biaya rata-rata per halaman $0,013. Langkah-langkah untuk mengurai file PDF adalah sebagai berikut: 1. Gunakan perpustakaan PyMuPDF untuk mengurai PDF menjadi area non-teks dan area teks.
Gunakan pustaka PyMuPDF untuk mengurai PDF ke dalam area non-teks dan area teks, dan gunakan model visualisasi besar seperti GPT-4o untuk mengurai dan mendapatkan file Markdown. 2. Gunakan model visualisasi besar (seperti GPT-4o) untuk mengurai dan mendapatkan file Markdown.
Proyek ini menggunakan teknologi AI canggih untuk memberikan solusi baru dalam pemrosesan dokumen PDF, sehingga sangat mengurangi biaya dan meningkatkan efisiensi. Pengguna yang tertarik dapat mengunjungi Github untuk melihat detail proyek dan merasakan fungsi penguraian PDF yang efisien dan nyaman. Kedepannya, proyek ini diharapkan dapat lebih banyak digunakan di bidang-bidang seperti ekstraksi data dan otomatisasi dokumen.