EnlightenGAN
1.0.0
Yifan Jiang, Xinyu Gong, Ding Liu, Yu Cheng, Chen Fang, Xiaohui Shen, Jianchao Yang, Pan Zhou, Zhangyang Wang
[กระดาษ] [วัสดุเสริม]

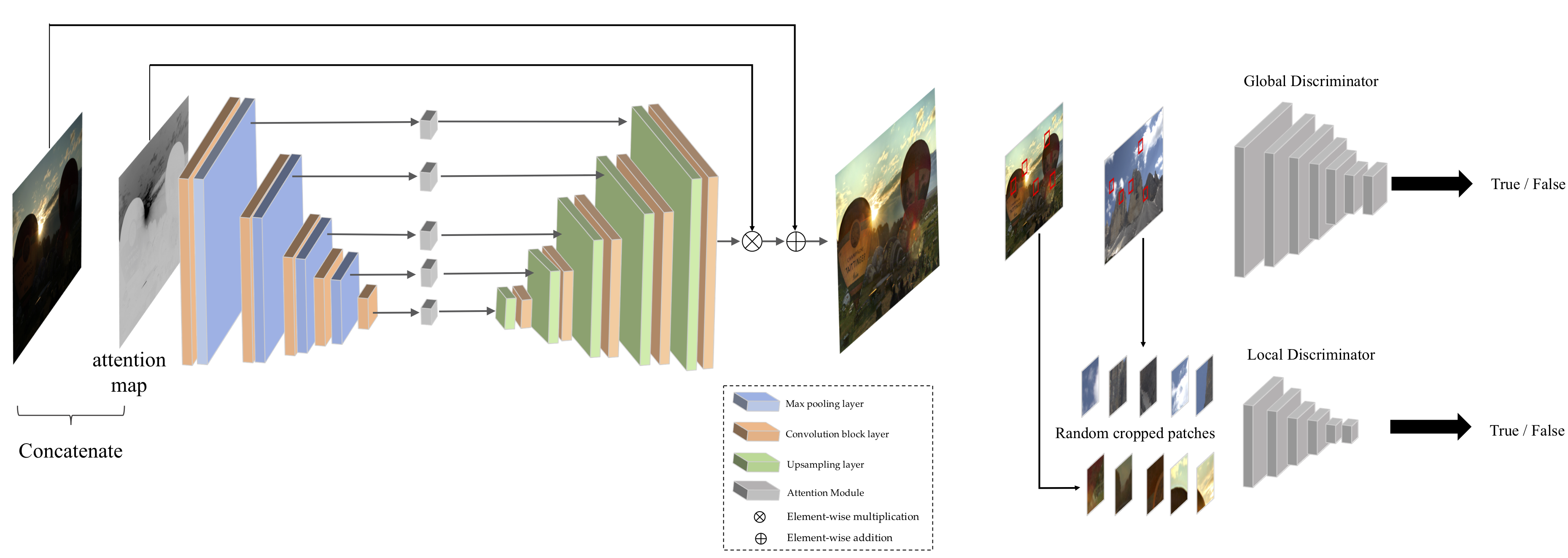
python3.5
คุณควรเตรียม GPU อย่างน้อย 3 1080Ti หรือเปลี่ยนขนาดแบทช์
pip install -r requirement.txt
mkdir model
ดาวน์โหลด VGG Pretrained Model จาก [Google Drive 1] จากนั้นใส่ลงใน model ไดเรกทอรี
ก่อนที่จะเริ่มกระบวนการฝึกอบรมคุณควรเปิดตัว visdom.server เพื่อแสดงภาพ
nohup python -m visdom.server -port=8097
จากนั้นเรียกใช้คำสั่งต่อไปนี้
python scripts/script.py --train
ดาวน์โหลดโมเดล pretrained และใส่ลงใน ./checkpoints/enlightening enlightening
สร้างไดเรกทอรี ../test_dataset/testA และ ../test_dataset/testB test_dataset/testb ใส่ภาพทดสอบของคุณบน ../test_dataset/testA testa (และคุณควรเก็บภาพใด ๆ ไว้ใน ../test_dataset/testB test_dataset/testb เพื่อให้แน่ใจว่าโปรแกรมสามารถเริ่มต้นได้)
วิ่ง
python scripts/script.py --predict
ข้อมูลการฝึกอบรม [Google Drive] (ภาพที่ไม่มีคู่ที่รวบรวมจากชุดข้อมูลหลายชุด)
การทดสอบข้อมูล [Google Drive] (รวมถึง Lime, MEF, NPE, VV, DICP)
และ [Baiduyun] พร้อมใช้งานแล้วขอบคุณ @yhlelaine!
https://github.com/arsenyinfo/enlightengan-inference จาก @arsenyinfo
หากคุณพบว่างานนี้มีประโยชน์สำหรับคุณโปรดอ้างอิง
@article{jiang2021enlightengan,
title={Enlightengan: Deep light enhancement without paired supervision},
author={Jiang, Yifan and Gong, Xinyu and Liu, Ding and Cheng, Yu and Fang, Chen and Shen, Xiaohui and Yang, Jianchao and Zhou, Pan and Wang, Zhangyang},
journal={IEEE Transactions on Image Processing},
volume={30},
pages={2340--2349},
year={2021},
publisher={IEEE}
}


