EnlightenGAN
1.0.0
Yifan Jiang, Xinyu Gong, Ding Liu, Yu Cheng, Chen Fang, XiaoHui Shen, Jianchao Yang, Pan Zhou, Zhangyang Wang
[Document] [Matériaux supplémentaires]

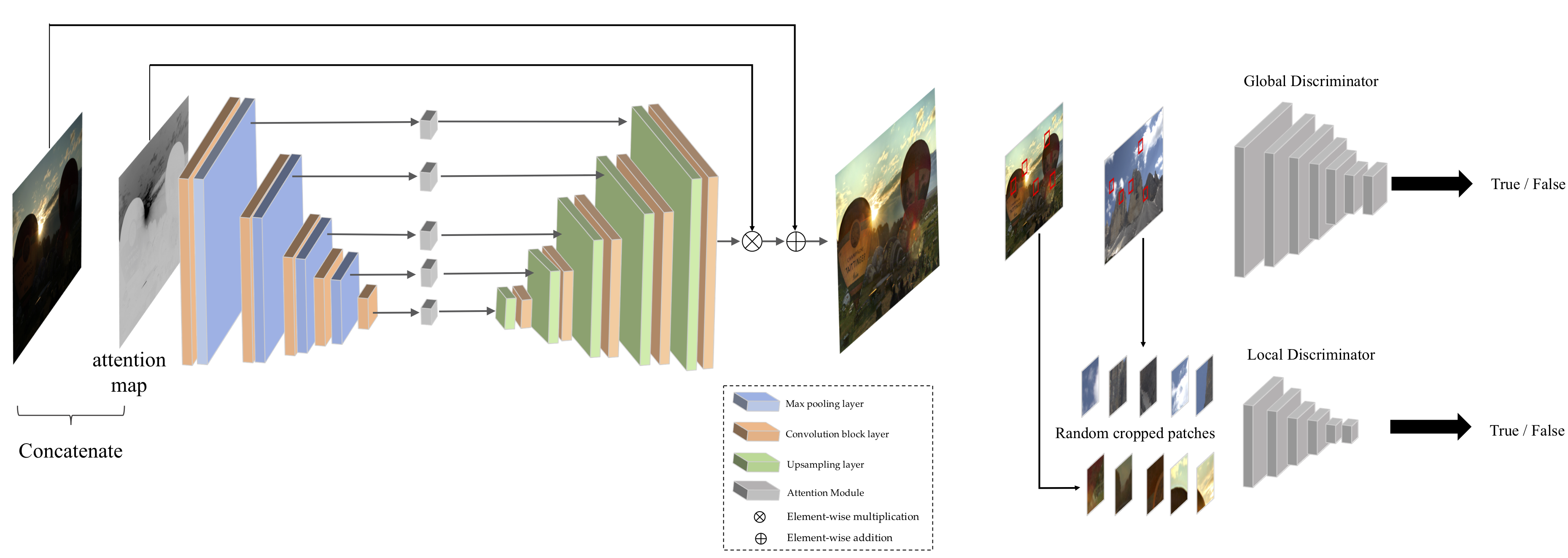
python3.5
Vous devez préparer au moins 3 GPU 1080ti ou modifier la taille du lot.
pip install -r requirement.txt
mkdir model
Téléchargez le modèle VGG prétrait de [Google Drive 1], puis mettez-le dans le model de répertoire.
Avant de commencer le processus de formation, vous devez lancer le visdom.server pour la visualisation.
nohup python -m visdom.server -port=8097
puis exécutez la commande suivante
python scripts/script.py --train
Téléchargez le modèle pré-entraîné et mettez-le dans ./checkpoints/enlightening
Créer des répertoires ../test_dataset/testA et ../test_dataset/testB . Mettez vos images de test sur ../test_dataset/testA (et vous devriez garder l'image dans ../test_dataset/testB pour vous assurer que le programme peut commencer.)
Courir
python scripts/script.py --predict
Données de formation [Google Drive] (images non appariées collectées à partir de plusieurs ensembles de données)
Tester les données [Google Drive] (y compris Lime, MEF, NPE, VV, DICP)
Et [Baiduyun] est disponible maintenant grâce à @yhlelaine!
https://github.com/arsenyinfo/enlightgan-inference de @arsenyinfo
Si vous trouvez ce travail utile pour vous, veuillez citer
@article{jiang2021enlightengan,
title={Enlightengan: Deep light enhancement without paired supervision},
author={Jiang, Yifan and Gong, Xinyu and Liu, Ding and Cheng, Yu and Fang, Chen and Shen, Xiaohui and Yang, Jianchao and Zhou, Pan and Wang, Zhangyang},
journal={IEEE Transactions on Image Processing},
volume={30},
pages={2340--2349},
year={2021},
publisher={IEEE}
}


