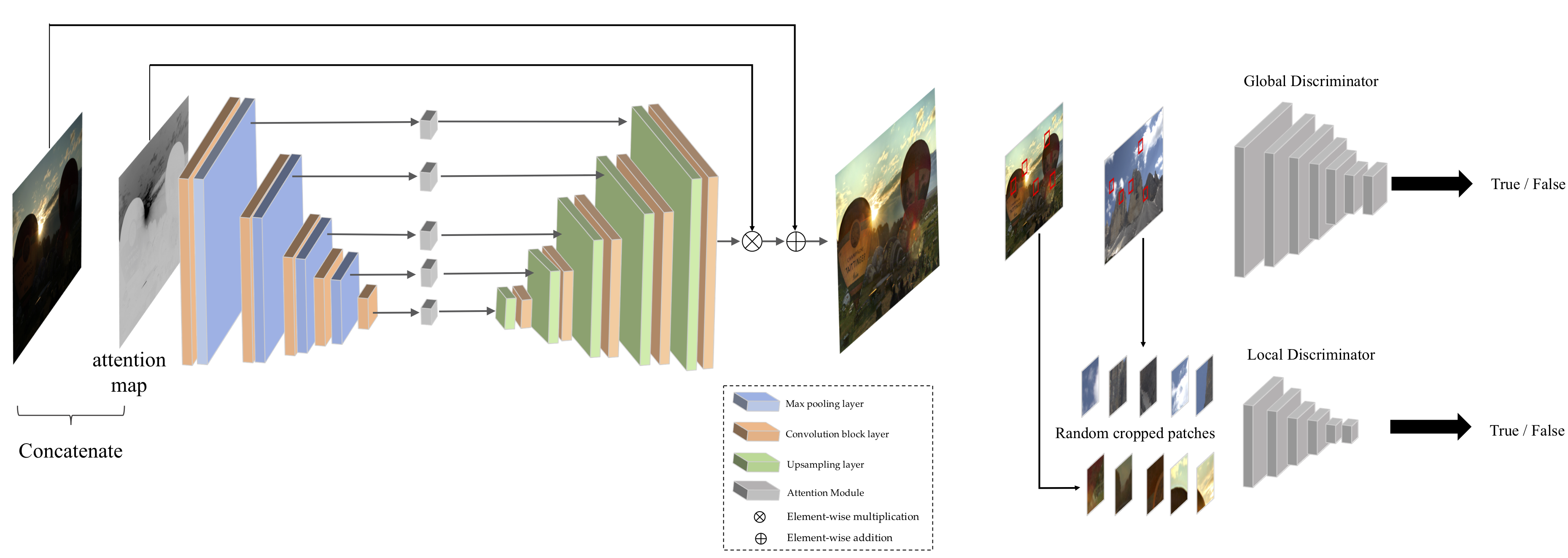
EnlightenGAN
1.0.0
Yifan Jiang ، Xinyu Gong ، Ding Liu ، Yu Cheng ، Chen Fang ، Xiaohui Shen ، Jianchao Yang ، Pan Zhou ، Zhangyang Wang
[ورقة] [المواد التكميلية]

python3.5
يجب عليك إعداد 3 1080ti على الأقل وحدات معالجة الرسومات أو تغيير حجم الدُفعة.
pip install -r requirement.txt
mkdir model
قم بتنزيل نموذج VGG PretRained من [Google Drive 1] ، ثم ضعه في model الدليل.
قبل البدء في عملية التدريب ، يجب عليك تشغيل visdom.server لتصورها.
nohup python -m visdom.server -port=8097
ثم قم بتشغيل الأمر التالي
python scripts/script.py --train
قم بتنزيل النموذج المسبق ووضعه في ./checkpoints/enlightening
إنشاء الدلائل ../test_dataset/testA و ../test_dataset/testB . ضع صور الاختبار الخاصة بك على ../test_dataset/testA (ويجب عليك الاحتفاظ بأي صورة واحدة في ../test_dataset/testB للتأكد من أن البرنامج يمكن أن يبدأ.)
يجري
python scripts/script.py --predict
بيانات التدريب [Google Drive] (الصور غير المقيدة التي تم جمعها من مجموعات بيانات متعددة)
اختبار البيانات [Google Drive] (بما في ذلك الجير ، MEF ، NPE ، VV ، DICP)
و [Baiduyun] متاح الآن بفضل @Yhelaine!
https://github.com/arsenyinfo/enlightengan-inference من @arsenyinfo
إذا وجدت هذا العمل مفيدًا لك ، يرجى الاستشهاد
@article{jiang2021enlightengan,
title={Enlightengan: Deep light enhancement without paired supervision},
author={Jiang, Yifan and Gong, Xinyu and Liu, Ding and Cheng, Yu and Fang, Chen and Shen, Xiaohui and Yang, Jianchao and Zhou, Pan and Wang, Zhangyang},
journal={IEEE Transactions on Image Processing},
volume={30},
pages={2340--2349},
year={2021},
publisher={IEEE}
}


