EnlightenGAN
1.0.0
Йифан Цзян, Синью Гонг, Дин Лю, Ю Ченг, Чен Фанг, Сяохуи Шен, Цзяньчао Ян, Пан Чжоу, Чжаньян Ванг
[Бумага] [Дополнительные материалы]

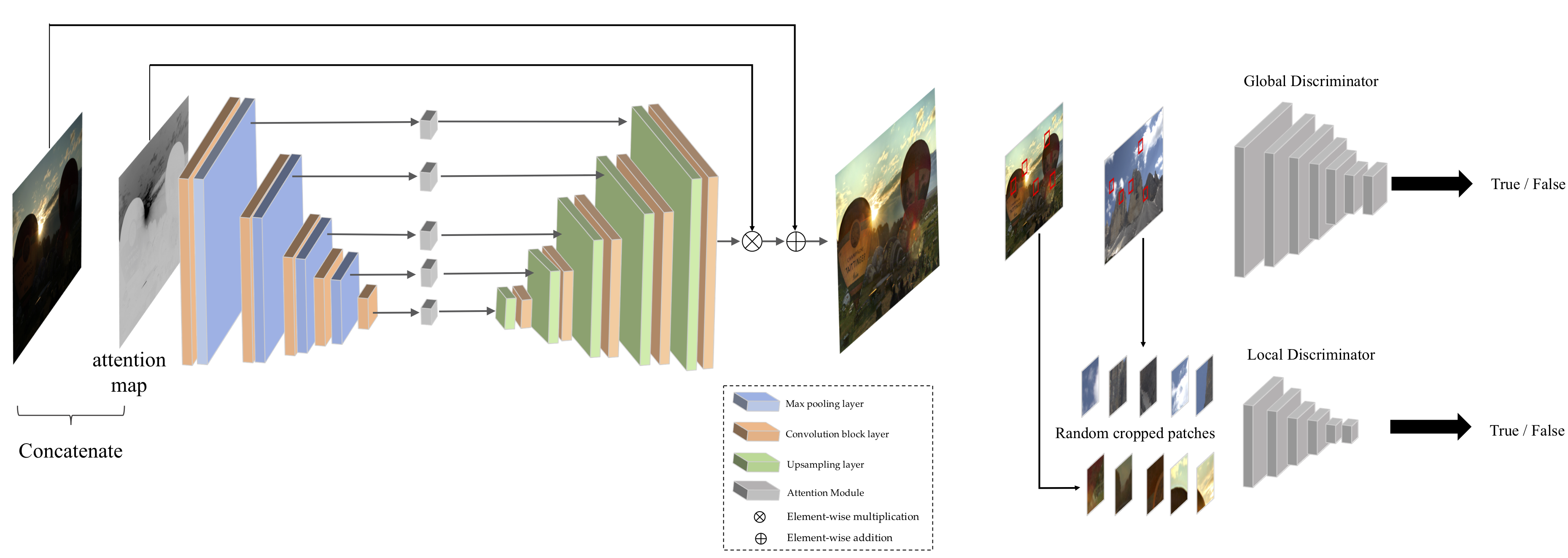
python3.5
Вы должны подготовить как минимум 3 1080TI графические процессоры или изменить размер партии.
pip install -r requirement.txt
mkdir model
Загрузите предварительную модель VGG из [Google Drive 1], а затем поместите ее в model каталога.
Перед началом обучения вам следует запустить visdom.server для визуализации.
nohup python -m visdom.server -port=8097
Затем запустите следующую команду
python scripts/script.py --train
Загрузите предварительную модель и поместите ее в ./checkpoints/enlightening
Создать каталоги ../test_dataset/testA и ../test_dataset/testB . Поместите свои тестовые изображения на ../test_dataset/testA (и вы должны сохранить любое изображение в ../test_dataset/testB , чтобы убедиться, что программа может начать.)
Бегать
python scripts/script.py --predict
Данные обучения [Google Drive] (непарные изображения, собранные из нескольких наборов данных)
Данные тестирования [Google Drive] (включая лайм, MEF, NPE, VV, DICP)
И [Baiduyun] теперь доступен благодаря @yhlelaine!
https://github.com/arsenyinfo/enlightengan-inference от @arsenyinfo
Если вы найдете эту работу полезной для вас, пожалуйста, цитируйте
@article{jiang2021enlightengan,
title={Enlightengan: Deep light enhancement without paired supervision},
author={Jiang, Yifan and Gong, Xinyu and Liu, Ding and Cheng, Yu and Fang, Chen and Shen, Xiaohui and Yang, Jianchao and Zhou, Pan and Wang, Zhangyang},
journal={IEEE Transactions on Image Processing},
volume={30},
pages={2340--2349},
year={2021},
publisher={IEEE}
}


