EnlightenGAN
1.0.0
Yifan Jiang, Xinyu Gong, Ding Liu, Yu Cheng, Chen Fang, Xiaohui Shen, Jianchao Yang, Pan Zhou, Zhangyang Wang
[Papier] [ergänzende Materialien]

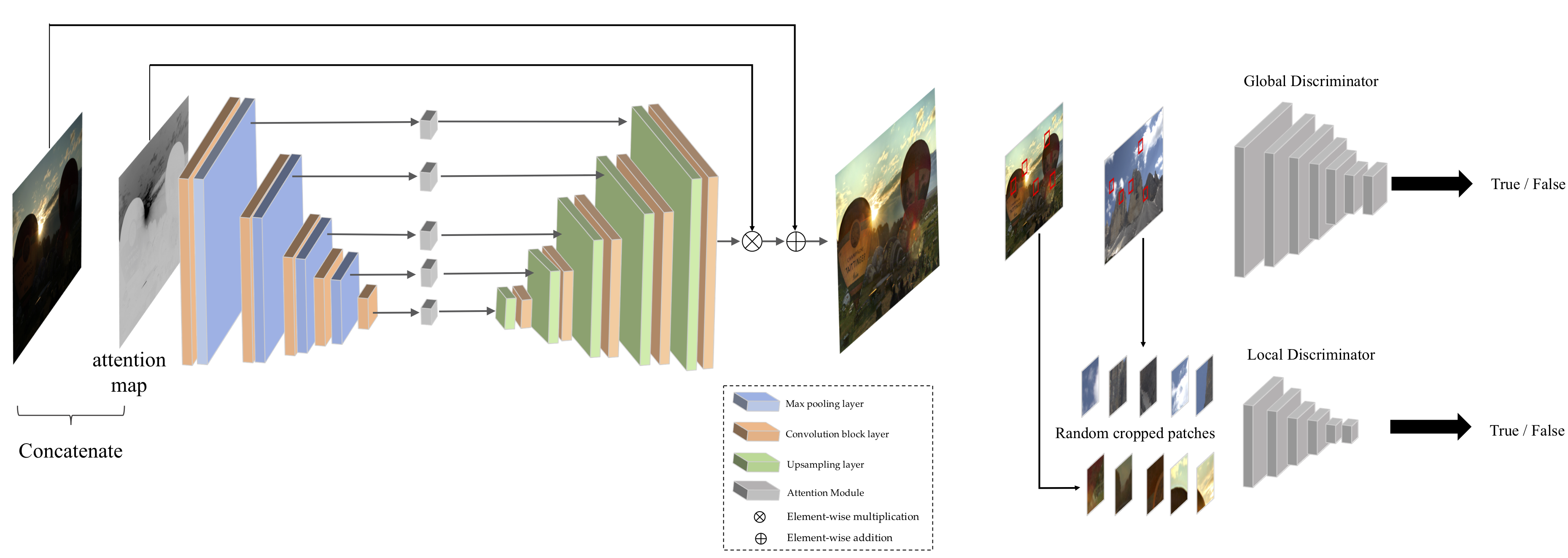
python3.5
Sie sollten mindestens 3 1080Ti -GPUs vorbereiten oder die Chargengröße ändern.
pip install -r requirement.txt
mkdir model
Laden Sie das vorgeläte Modell von VGG von [Google Drive 1] herunter und geben Sie es dann in das model ein.
Bevor Sie mit dem Schulungsprozess beginnen, sollten Sie das visdom.server zum Visualisierung starten.
nohup python -m visdom.server -port=8097
Führen Sie dann den folgenden Befehl aus
python scripts/script.py --train
Laden Sie ein vorgezogenes Modell herunter und geben Sie es in ./checkpoints/enlightening ein
Verzeichnisse erstellen ../test_dataset/testA und ../test_dataset/testB . Setzen Sie Ihre Testbilder auf ../test_dataset/testA (und Sie sollten das Bild in ../test_dataset/testB beibehalten, um sicherzustellen, dass das Programm starten kann.)
Laufen
python scripts/script.py --predict
Trainingsdaten [Google Drive] (ungepaarte Bilder, die aus mehreren Datensätzen gesammelt wurden)
Testen von Daten [Google Drive] (einschließlich Kalk, MEF, NPE, VV, DICP)
Und [Baiduyun] ist jetzt dank @yhlelaine erhältlich!
https://github.com/arsenyinfo/enligherngan-inference von @arsenyinfo
Wenn Sie diese Arbeit für Sie nützlich finden, zitieren Sie bitte
@article{jiang2021enlightengan,
title={Enlightengan: Deep light enhancement without paired supervision},
author={Jiang, Yifan and Gong, Xinyu and Liu, Ding and Cheng, Yu and Fang, Chen and Shen, Xiaohui and Yang, Jianchao and Zhou, Pan and Wang, Zhangyang},
journal={IEEE Transactions on Image Processing},
volume={30},
pages={2340--2349},
year={2021},
publisher={IEEE}
}


