pytorch a3c
1.0.0
นี่คือการใช้ Pytorch ของนักวิจารณ์นักแสดง Asynchronous Advantage (A3C) จาก "วิธีการแบบอะซิงโครนัสสำหรับการเรียนรู้การเสริมแรงอย่างลึกล้ำ"
การใช้งานนี้ได้รับแรงบันดาลใจจากตัวแทนเริ่มต้นจักรวาล ตรงกันข้ามกับตัวแทนเริ่มต้นใช้เครื่องมือเพิ่มประสิทธิภาพที่มีสถิติที่ใช้ร่วมกันเช่นเดียวกับในกระดาษต้นฉบับ
โปรดใช้ bibtex นี้หากคุณต้องการอ้างถึงที่เก็บนี้ในสิ่งพิมพ์ของคุณ:
@misc{pytorchaaac,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Asynchronous Advantage Actor Critic},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a3c}},
}
ฉัน ขอแนะนำ ให้ตรวจสอบเวอร์ชัน sychronous และอัลกอริทึมอื่น ๆ : Pytorch-A2C-PPO-ACKTR
จากประสบการณ์ของฉัน A2C ทำงานได้ดีกว่า A3C และ ACKTR ดีกว่าทั้งคู่ ยิ่งไปกว่านั้น PPO เป็นอัลกอริทึมที่ยอดเยี่ยมสำหรับการควบคุมอย่างต่อเนื่อง ดังนั้นฉันขอแนะนำให้ลอง A2C/PPO/ACKTR ก่อนและใช้ A3C เฉพาะในกรณีที่คุณต้องการโดยเฉพาะด้วยเหตุผลบางอย่าง
อ่านบล็อก OpenAI สำหรับข้อมูลเพิ่มเติม
ยินดีต้อนรับการมีส่วนร่วมอย่างมาก หากคุณรู้วิธีทำให้รหัสนี้ดีขึ้นอย่าลังเลที่จะส่งคำขอดึง
# Works only wih Python 3.
python3 main.py --env-name " PongDeterministic-v4 " --num-processes 16รหัสนี้เรียกใช้การประเมินผลในเธรดแยกต่างหากนอกเหนือจาก 16 กระบวนการ
ด้วยกระบวนการ 16 ครั้งมันมาบรรจบกันสำหรับ pongdeterministic-V4 ใน 15 นาที 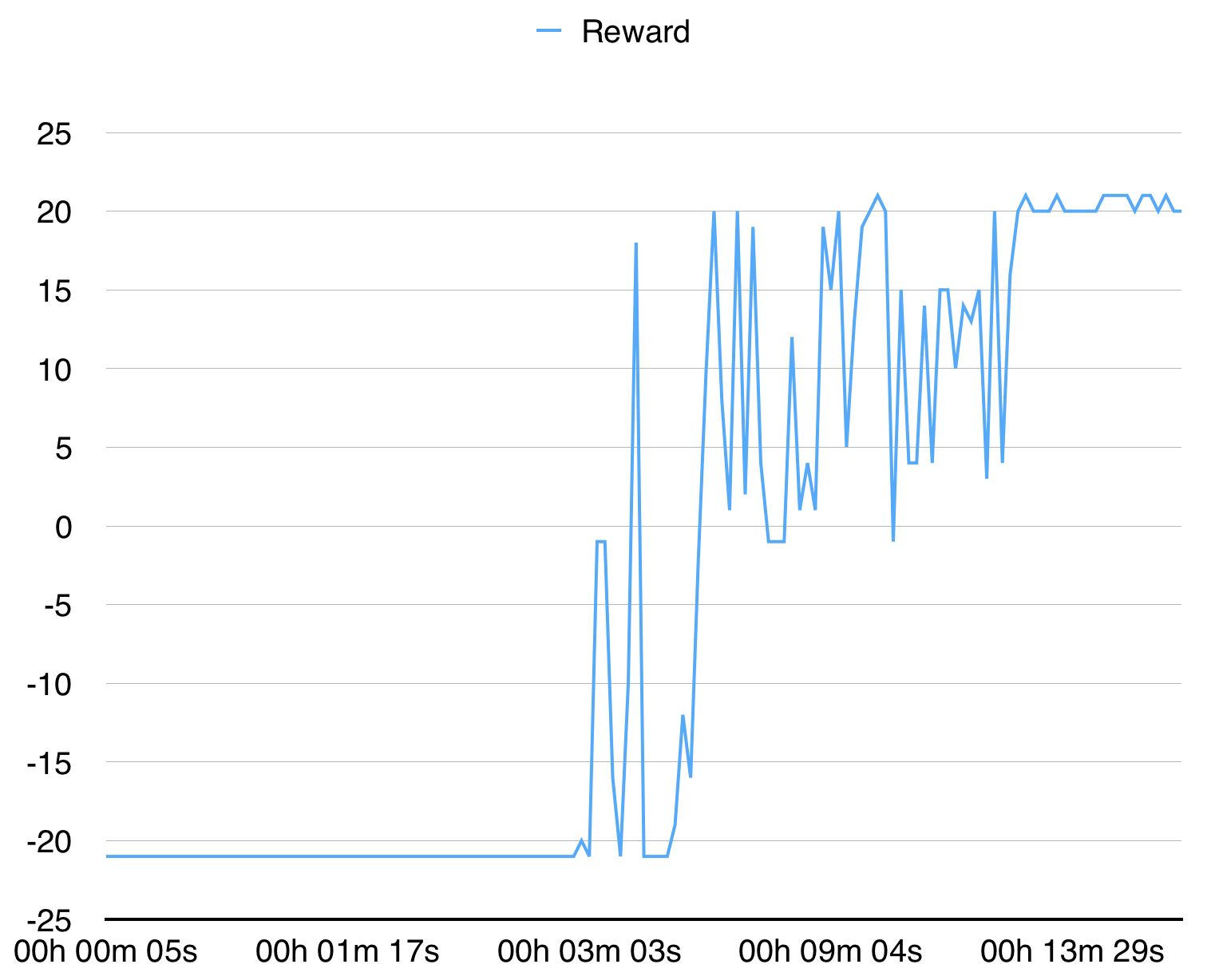
สำหรับ BreakoutDeterministic-V4 ใช้เวลามากกว่าหลายชั่วโมง


