pytorch a3c
1.0.0
Dies ist eine Pytorch -Implementierung von Asynchronous Advantage Actor Critic (A3C) aus "asynchronen Methoden zum Tiefenstärkungslernen".
Diese Implementierung ist vom Universum Starter Agent inspiriert. Im Gegensatz zum Starteragenten verwendet es einen Optimierer mit gemeinsam genutzten Statistiken wie im Originalpapier.
Bitte verwenden Sie dieses Bibtex, wenn Sie dieses Repository in Ihren Veröffentlichungen zitieren möchten:
@misc{pytorchaaac,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Asynchronous Advantage Actor Critic},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a3c}},
}
Ich empfehle dringend, eine sychrone Version und andere Algorithmen zu überprüfen: Pytorch-A2C-PPO-ACKTR.
Nach meiner Erfahrung funktioniert A2C besser als A3C und ACKTR ist besser als beide. Darüber hinaus ist PPO ein großartiger Algorithmus für die kontinuierliche Kontrolle. Daher empfehle ich, zuerst A2C/PPO/ACKTR auszuprobieren und A3C nur zu verwenden, wenn Sie ihn aus bestimmten Gründen speziell benötigen.
Lesen Sie auch OpenAI -Blog, um weitere Informationen zu erhalten.
Beiträge sind sehr willkommen. Wenn Sie wissen, wie Sie diesen Code besser machen können, zögern Sie nicht, eine Pull -Anfrage zu senden.
# Works only wih Python 3.
python3 main.py --env-name " PongDeterministic-v4 " --num-processes 16In diesem Code wird die Bewertung in einem separaten Thread zusätzlich zu 16 Prozessen ausgeführt.
Mit 16 Prozessen konvergiert es in 15 Minuten für PongDeterministic-V4. 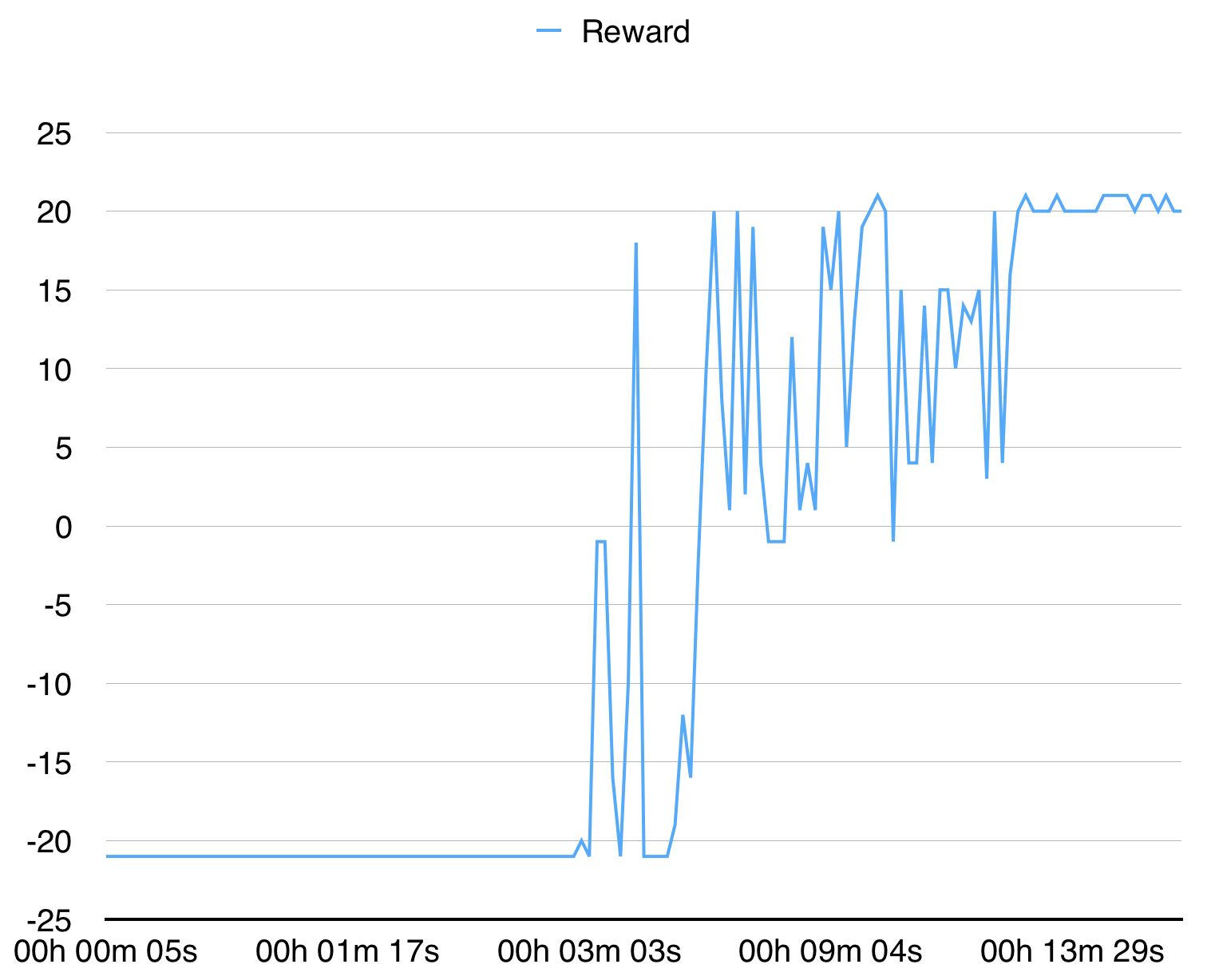
Für BreakoutDeterministic-V4 dauert es mehr als mehrere Stunden.


