pytorch a3c
1.0.0
Il s'agit d'une mise en œuvre pytorch de l'avantage asynchrone Critique d'acteur (A3C) à partir de "méthodes asynchrones d'apprentissage en renforcement profond".
Cette implémentation est inspirée par l'agent de démarrage de l'univers. Contrairement à l'agent de démarrage, il utilise un optimiseur avec des statistiques partagées comme dans l'article d'origine.
Veuillez utiliser ce bibtex si vous souhaitez citer ce référentiel dans vos publications:
@misc{pytorchaaac,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Asynchronous Advantage Actor Critic},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a3c}},
}
Je recommande fortement de vérifier une version sychronique et d'autres algorithmes: pytorch-a2c-pppo-backtr.
D'après mon expérience, A2C fonctionne mieux que A3C et ACKTR est meilleur que les deux. De plus, PPO est un excellent algorithme pour le contrôle continu. Ainsi, je recommande d'abord d'essayer A2C / PPO / ACKTR et d'utiliser A3C uniquement si vous en avez besoin spécifiquement pour certaines raisons.
Lisez également le blog Openai pour plus d'informations.
Les contributions sont les bienvenues. Si vous savez comment améliorer ce code, n'hésitez pas à envoyer une demande de traction.
# Works only wih Python 3.
python3 main.py --env-name " PongDeterministic-v4 " --num-processes 16Ce code exécute l'évaluation dans un thread séparé en plus de 16 processus.
Avec 16 processus, il converge pour le pongdeterministe-V4 en 15 minutes. 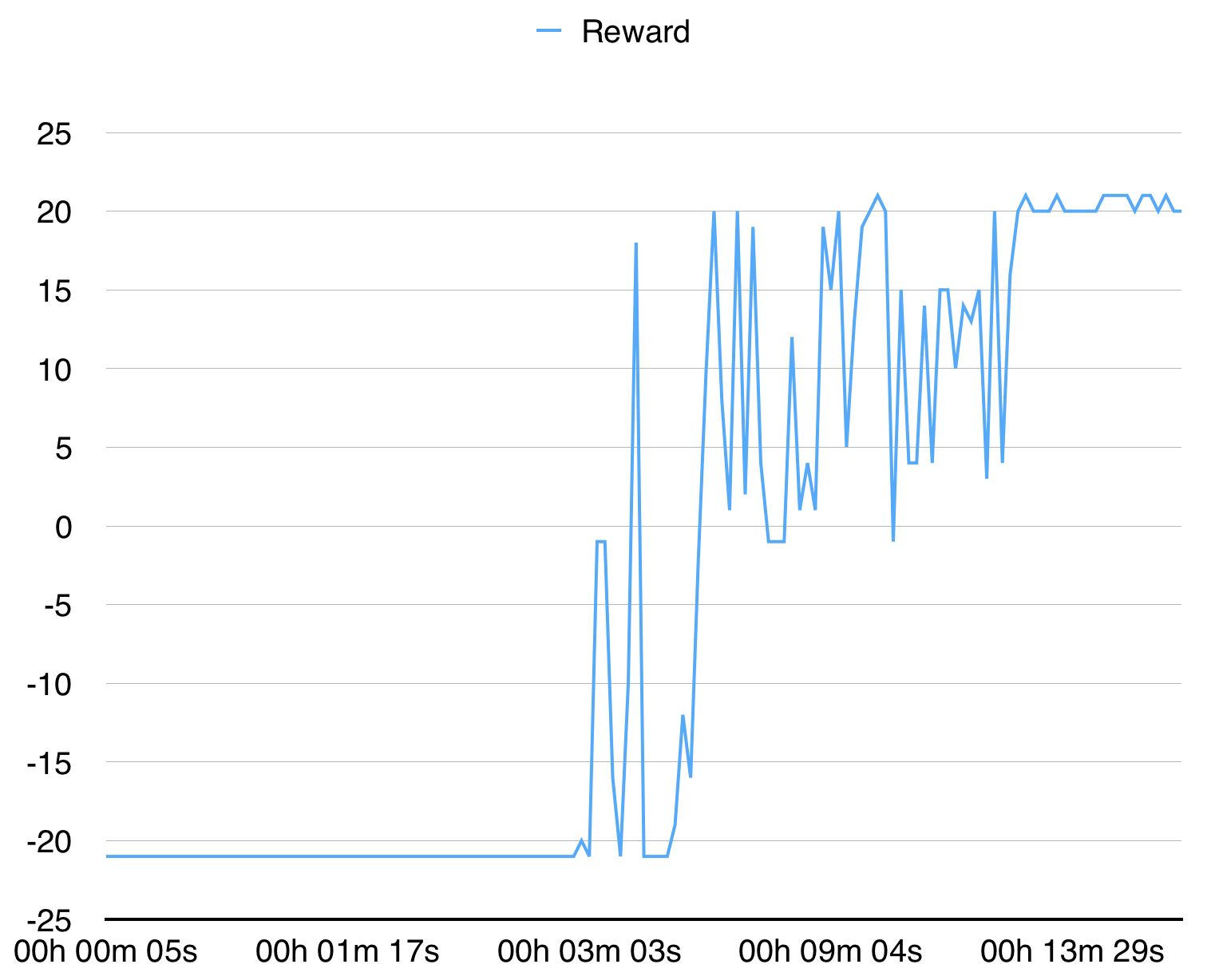
Pour Breakoutdeterministic-V4, il faut plus de plusieurs heures.


