pytorch a3c
1.0.0
هذا هو تنفيذ Pytorch من الناقد غير المتزامن للممثل (A3C) من "الأساليب غير المتزامنة للتعلم التعزيز العميق".
هذا التنفيذ مستوحى من وكيل بداية الكون. على عكس وكيل المبتدئين ، فإنه يستخدم مُحسّنًا مع إحصائيات مشتركة كما في الورقة الأصلية.
يرجى استخدام هذا bibtex إذا كنت تريد الاستشهاد بهذا المستودع في منشوراتك:
@misc{pytorchaaac,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Asynchronous Advantage Actor Critic},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a3c}},
}
أوصي بشدة بالتحقق من نسخة مخطوطة وخوارزميات أخرى: Pytorch-A2C-PPO-acktr.
في تجربتي ، يعمل A2C بشكل أفضل من A3C و Acktr أفضل من كلاهما. علاوة على ذلك ، PPO هي خوارزمية رائعة للتحكم المستمر. وبالتالي ، أوصي بتجربة A2C/PPO/ACKTR أولاً واستخدام A3C فقط إذا كنت في حاجة إليها على وجه التحديد لبعض الأسباب.
اقرأ أيضًا مدونة Openai لمزيد من المعلومات.
المساهمات مرحب بها للغاية. إذا كنت تعرف كيفية جعل هذا الرمز أفضل ، فلا تتردد في إرسال طلب سحب.
# Works only wih Python 3.
python3 main.py --env-name " PongDeterministic-v4 " --num-processes 16يقوم هذا الرمز بتشغيل التقييم في مؤشر ترابط منفصل بالإضافة إلى 16 عملية.
مع 16 عملية تتقارب مع Pongdeterministic-V4 في 15 دقيقة. 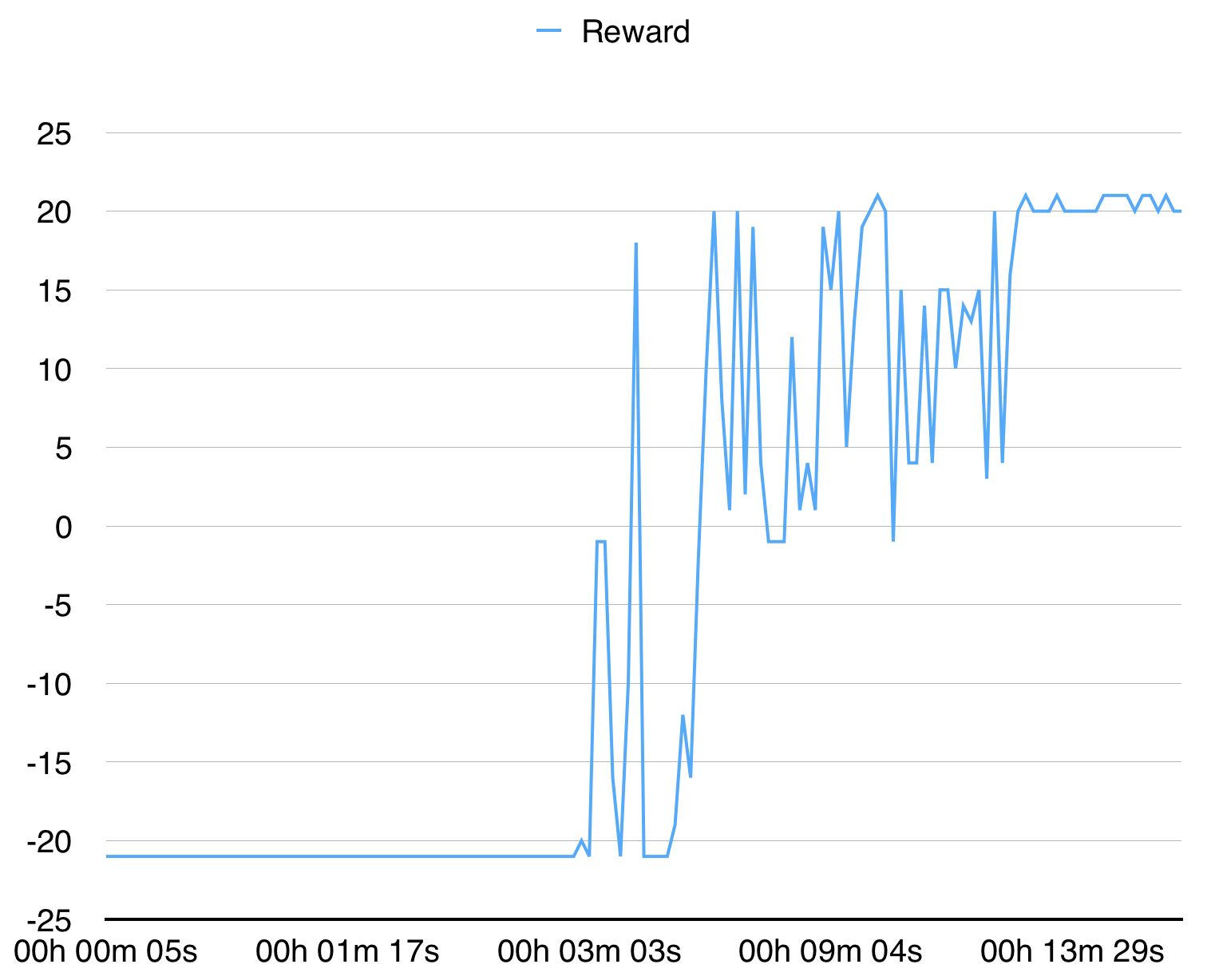
بالنسبة لـ BreakoutDeterministic-V4 ، يستغرق الأمر أكثر من عدة ساعات.


