pytorch a3c
1.0.0
Это реализация Pytorch Asynchronous Advantage Actor Critic Critic (A3C) из «асинхронных методов для глубокого обучения подкреплению».
Эта реализация вдохновлена стартовым агентом Вселенной. В отличие от стартового агента, он использует оптимизатор с общей статистикой, как в исходной статье.
Пожалуйста, используйте этот Bibtex, если вы хотите привести этот репозиторий в своих публикациях:
@misc{pytorchaaac,
author = {Kostrikov, Ilya},
title = {PyTorch Implementations of Asynchronous Advantage Actor Critic},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/ikostrikov/pytorch-a3c}},
}
Я настоятельно рекомендую проверить сихронную версию и другие алгоритмы: Pytorch-A2C-Ppo-Acttr.
По моему опыту, A2C работает лучше, чем A3C, а ACKTR лучше, чем они обоих. Кроме того, PPO является отличным алгоритмом для непрерывного контроля. Таким образом, я рекомендую сначала попробовать A2C/PPO/ACKTR и использовать A3C только в том случае, если вам это нужно конкретно по некоторым причинам.
Также прочитайте блог Openai для получения дополнительной информации.
Взносы очень приветствуются. Если вы знаете, как сделать этот код лучше, не стесняйтесь отправлять запрос на тягу.
# Works only wih Python 3.
python3 main.py --env-name " PongDeterministic-v4 " --num-processes 16Этот код запускает оценку в отдельном потоке в дополнение к 16 процессам.
С 16 процессами он сходится для Pongdeterministic-V4 за 15 минут. 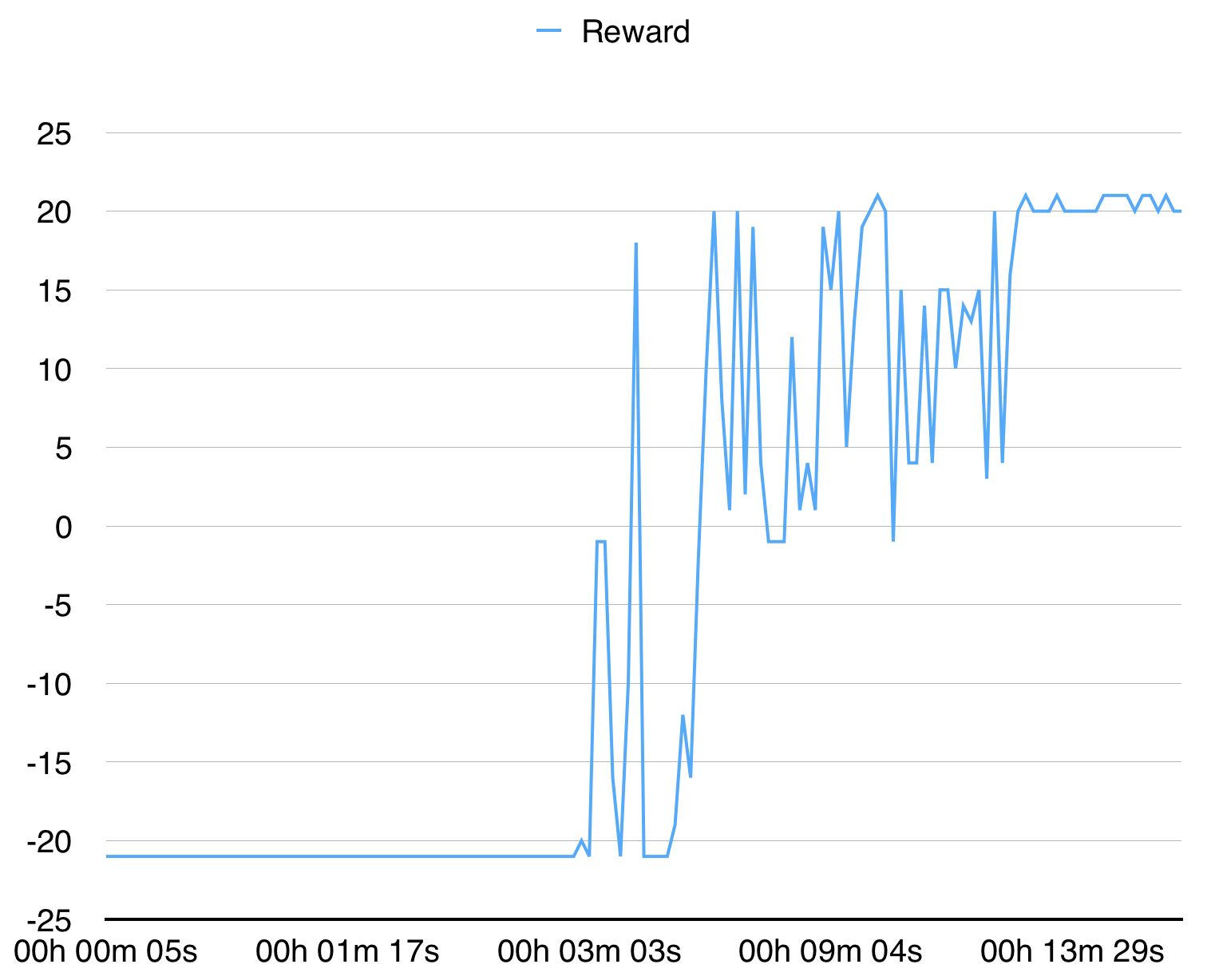
Для BreakoutDeterministic-V4 занимает более нескольких часов.


