distiller
1.0.0
การหยุดโครงการ - โครงการนี้จะไม่ได้รับการดูแลโดย Intel อีกต่อไป โครงการนี้ได้รับการระบุว่ามีการหลบหนีความปลอดภัยที่รู้จัก Intel หยุดการพัฒนาและการมีส่วนร่วมรวมถึง แต่ไม่ จำกัด เพียงการบำรุงรักษาการแก้ไขข้อบกพร่องการเผยแพร่ใหม่หรือการอัปเดตในโครงการนี้ Intel ไม่ยอมรับแพตช์สำหรับโครงการนี้อีกต่อไป

Distiller เป็นแพ็คเกจ Python โอเพนซอร์ซสำหรับการวิจัยการบีบอัดเครือข่ายประสาท
การบีบอัดเครือข่ายสามารถลดรอยเท้าหน่วยความจำของเครือข่ายประสาทเพิ่มความเร็วการอนุมานและประหยัดพลังงาน Distiller ให้สภาพแวดล้อม pytorch สำหรับการสร้างต้นแบบและการวิเคราะห์อัลกอริธึมการบีบอัดเช่นวิธีการทำให้เกิดความแตกต่างและการคำนวณทางคณิตศาสตร์ที่มีความแม่นยำต่ำ
คำแนะนำเหล่านี้จะช่วยให้กลั่นและทำงานบนเครื่องในพื้นที่ของคุณ
โคลนที่เก็บรหัสกลั่นจาก GitHub:
$ git clone https://github.com/IntelLabs/distiller.git
ส่วนที่เหลือของเอกสารที่ตามมาสันนิษฐานว่าคุณได้โคลนที่เก็บของคุณไปยังไดเรกทอรีที่เรียกว่า distiller
เราแนะนำให้ใช้สภาพแวดล้อมเสมือนจริงของ Python แต่แน่นอนว่าขึ้นอยู่กับคุณ ไม่มีอะไรพิเศษเกี่ยวกับการใช้เครื่องกลั่นในสภาพแวดล้อมเสมือนจริง แต่เราให้คำแนะนำบางอย่างเพื่อความสมบูรณ์
ก่อนที่จะสร้างสภาพแวดล้อมเสมือนจริง distiller ให้แน่ใจว่าคุณอยู่ในไดเรกทอรีกลั่น หลังจากสร้างสภาพแวดล้อมคุณควรเห็นไดเรกทอรีที่เรียกว่า distiller/env
หากคุณไม่ได้ติดตั้ง VirtualEnV คุณสามารถค้นหาคำแนะนำการติดตั้งได้ที่นี่
เพื่อสร้างสภาพแวดล้อมดำเนินการ:
$ python3 -m virtualenv env
สิ่งนี้จะสร้างไดเรกทอรีย่อยที่มีชื่อว่า env ซึ่งมีการจัดเก็บสภาพแวดล้อมเสมือนจริงของ Python และกำหนดค่าเชลล์ปัจจุบันเพื่อใช้เป็นสภาพแวดล้อม Python เริ่มต้น
หากคุณต้องการใช้ venv ให้เริ่มด้วยการติดตั้ง:
$ sudo apt-get install python3-venv
จากนั้นสร้างสภาพแวดล้อม:
$ python3 -m venv env
เช่นเดียวกับ Virtualenv สิ่งนี้สร้างไดเรกทอรีที่เรียกว่า distiller/env
คำสั่งการเปิดใช้งานและการปิดใช้งานสภาพแวดล้อมสำหรับ venv และ virtualenv นั้นเหมือนกัน
! หมายเหตุ: ตรวจสอบให้แน่ใจว่าได้เปิดใช้งานสภาพแวดล้อมก่อนดำเนินการติดตั้งแพ็คเกจการพึ่งพา:
$ source env/bin/activate
ในที่สุดติดตั้งแพ็คเกจกลั่นและการอ้างอิงโดยใช้ pip3 :
$ cd distiller
$ pip3 install -e .
สิ่งนี้ติดตั้งเครื่องกลั่นใน "โหมดการพัฒนา" หมายถึงการเปลี่ยนแปลงใด ๆ ที่เกิดขึ้นในรหัสจะสะท้อนให้เห็นในสภาพแวดล้อมโดยไม่ต้องรันคำสั่งการติดตั้งอีกครั้ง (ดังนั้นไม่จำเป็นต้องติดตั้งอีกครั้งหลังจากดึงการเปลี่ยนแปลงจากที่เก็บ GIT)
หมายเหตุ:
เครื่องกลั่นได้รับการทดสอบโดยใช้การติดตั้งเริ่มต้นของ Pytorch 1.3.1 ซึ่งใช้ CUDA 10.1 เราใช้ Torchvision เวอร์ชัน 0.4.2 สิ่งเหล่านี้รวมอยู่ใน requirements.txt ของ Distiller.txt และจะติดตั้งโดยอัตโนมัติเมื่อติดตั้งแพ็คเกจกลั่นตามที่ระบุไว้ด้านบน
หากคุณไม่ได้ใช้ CUDA 10.1 ในสภาพแวดล้อมของคุณโปรดดูที่เว็บไซต์ Pytorch เพื่อติดตั้ง Build ที่เข้ากันได้ของ Pytorch 1.3.1 และ Torchvision 0.4.2
Distiller มาพร้อมกับแอปพลิเคชันตัวอย่างและแบบฝึกหัดที่ครอบคลุมช่วงของประเภทรุ่น:
| ประเภทรุ่น | ความเบาบาง | การฝึกอบรมหลังการฝึกอบรม | การฝึกอบรมเชิงปริมาณ | การบีบอัดอัตโนมัติ (AMC) | การกลั่นความรู้ |
|---|---|---|---|---|---|
| การจำแนกรูปภาพ | |||||
| รูปแบบภาษาระดับคำ | |||||
| การแปล (GNMT) | |||||
| ระบบแนะนำ (NCF) | |||||
| การตรวจจับวัตถุ |
ตรงไปที่ไดเรกทอรีตัวอย่างสำหรับรายละเอียดเพิ่มเติม
ทรัพยากรอื่น ๆ ที่จะอ้างถึงนอกเหนือจากตัวอย่าง:
ต่อไปนี้เป็นตัวอย่างง่ายๆโดยใช้ตัวอย่างการจำแนกประเภทภาพของ Distiller ซึ่งแสดงความสามารถของกลั่น
ต่อไปนี้จะเรียกใช้การฝึกอบรมอย่างเดียว (ไม่มีการบีบอัด) ของเครือข่ายชื่อ 'Simplenet' บนชุดข้อมูล CIFAR10 สิ่งนี้อยู่บนพื้นฐานของแอปพลิเคชันการฝึกอบรม ImageNet ตัวอย่างของ Torchvision ดังนั้นจึงควรดูคุ้นเคยหากคุณใช้แอปพลิเคชันนั้น ในตัวอย่างนี้เราไม่ได้เรียกใช้กลไกการบีบอัดใด ๆ : เราเพียงแค่ฝึกอบรมเพราะการปรับแต่งหลังจากการตัดแต่งกิ่งการฝึกอบรมเป็นส่วนสำคัญ
โปรดทราบว่าครั้งแรกที่คุณเรียกใช้คำสั่งนี้รหัส CIFAR10 จะถูกดาวน์โหลดไปยังเครื่องของคุณซึ่งอาจใช้เวลาสักครู่ - โปรดให้กระบวนการดาวน์โหลดดำเนินการเสร็จสมบูรณ์
พา ธ ไปยังชุดข้อมูล CIFAR10 นั้นเป็นไปตามอำเภอใจ แต่ในตัวอย่างของเราเราวางชุดข้อมูลในระดับไดเรกทอรีเดียวกับเครื่องกลั่น (เช่น ../../../data.cifar10 )
ก่อนอื่นเปลี่ยนเป็นไดเรกทอรีตัวอย่างจากนั้นเรียกใช้แอปพลิเคชัน:
$ cd distiller/examples/classifier_compression
$ python3 compress_classifier.py --arch simplenet_cifar ../../../data.cifar10 -p 30 -j=1 --lr=0.01
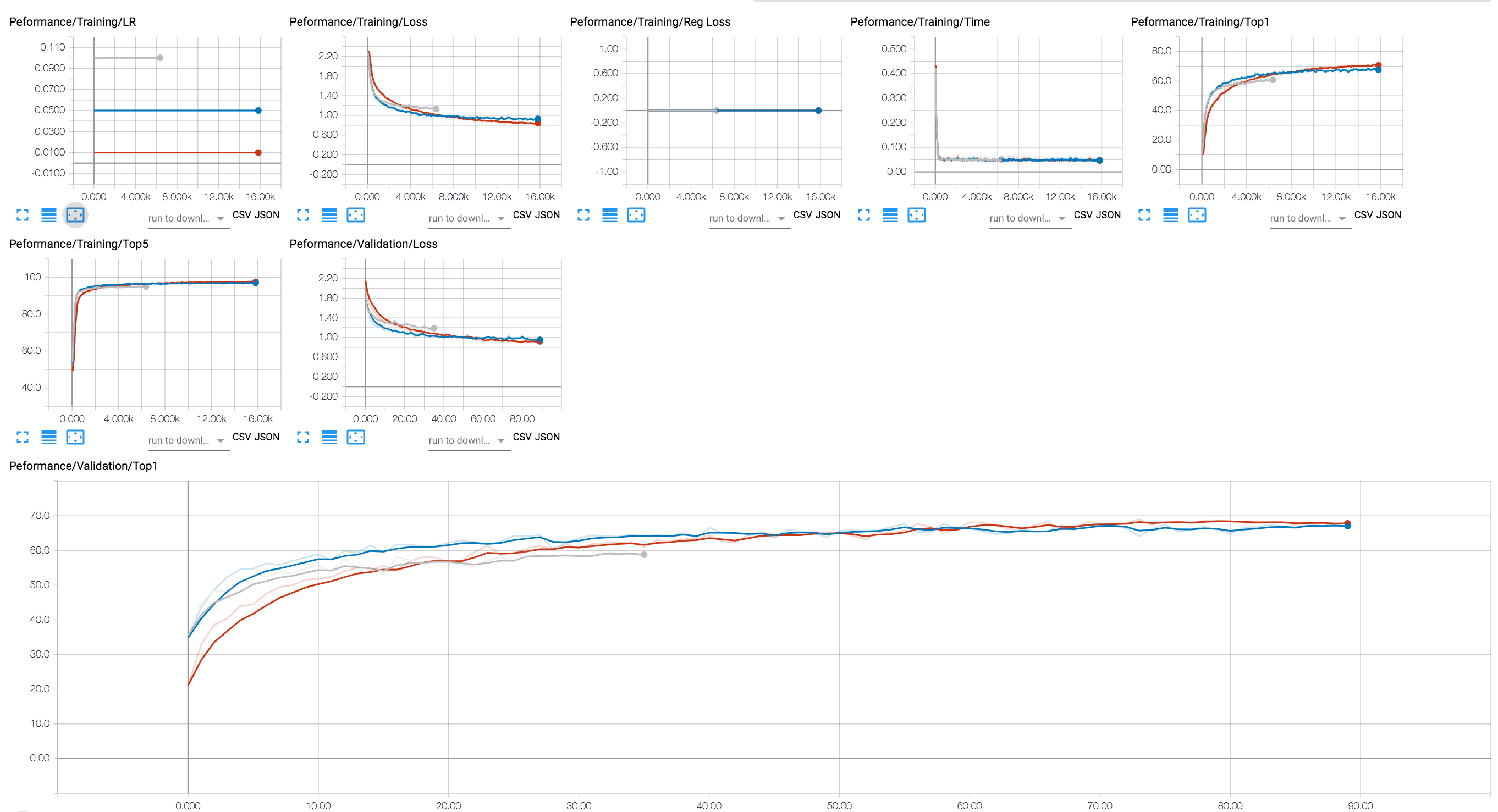
คุณสามารถใช้แบ็กเอนด์ Tensorboard เพื่อดูความคืบหน้าการฝึกอบรม (ในแผนภาพด้านล่างเราแสดงการฝึกอบรมสองครั้งที่มีค่า LR ที่แตกต่างกัน) สำหรับเซสชันการบีบอัดเราได้เพิ่มการติดตามการเปิดใช้งานและระดับพารามิเตอร์ Sparsity และการสูญเสียการทำให้เป็นมาตรฐาน
เราได้รวมอยู่ในที่เก็บ Git จุดตรวจสองสามตัวของรุ่น Resnet20 ที่เราได้รับการฝึกฝนด้วยลอย 32 บิต มาโหลดจุดตรวจสอบของรุ่นที่เราได้รับการฝึกฝนกับการทำให้เป็นมาตรฐานของ Lasso กลุ่มที่ชาญฉลาด
ด้วยอาร์กิวเมนต์บรรทัดคำสั่งต่อไปนี้แอปพลิเคชันตัวอย่างจะโหลดโมเดล ( --resume ) และพิมพ์สถิติเกี่ยวกับน้ำหนักรุ่น ( --summary=sparsity ) สิ่งนี้มีประโยชน์หากคุณต้องการโหลดโมเดลที่ถูกตัดแต่งก่อนหน้านี้เพื่อตรวจสอบสถิติสปาร์ตี้น้ำหนักตัวอย่างเช่น โปรดทราบว่าเมื่อคุณ ดำเนินการตรวจ สอบจุดตรวจสอบที่เก็บไว้คุณยังต้องบอกแอปพลิเคชันว่าสถาปัตยกรรมเครือข่ายที่จุดตรวจสอบใช้ ( -a=resnet20_cifar ):
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_ch_regularized_dense.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=sparsity
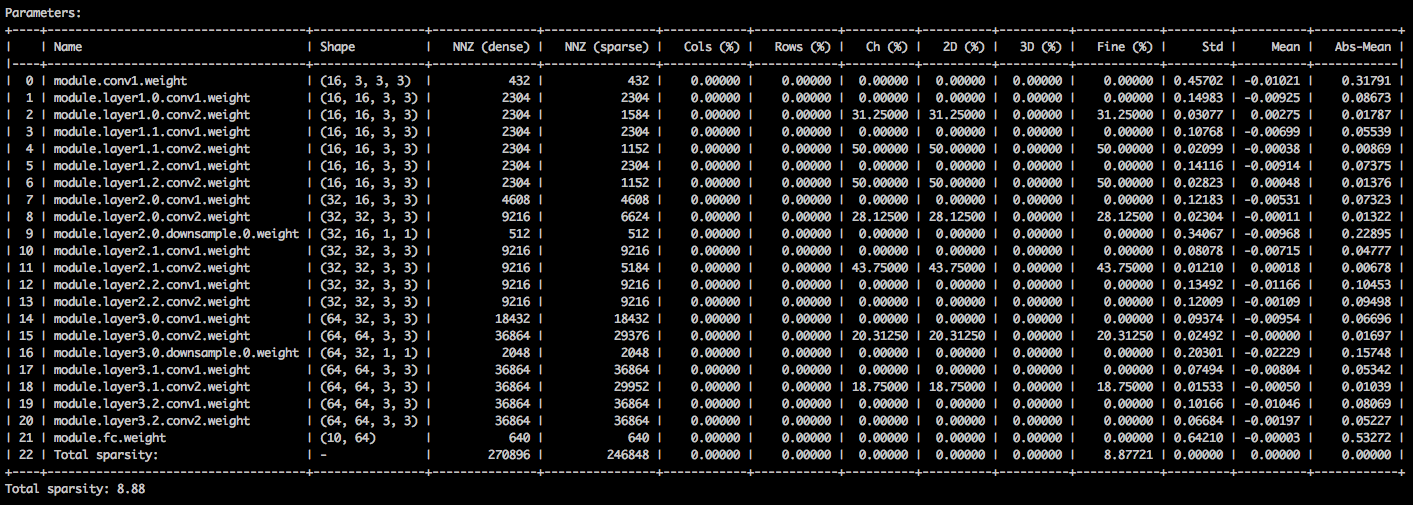
คุณควรเห็นตารางข้อความที่มีรายละเอียดเกี่ยวกับ sparsities ต่าง ๆ ของเทนเซอร์พารามิเตอร์ คอลัมน์แรกคือชื่อพารามิเตอร์ตามด้วยรูปร่างจำนวนองค์ประกอบที่ไม่ใช่ศูนย์ (NNZ) ในแบบจำลองหนาแน่นและในโมเดลกระจัดกระจาย ชุดคอลัมน์ถัดไปแสดงคอลัมน์ที่ชาญฉลาดแถวฉลาดช่องทางที่ชาญฉลาดเคอร์เนลที่ชาญฉลาดฟิลเตอร์ฉลาดและองค์ประกอบที่ชาญฉลาด
การห่อมันคือการจำแนกมาตรฐานค่าเฉลี่ยและค่าเฉลี่ยของค่าสัมบูรณ์ขององค์ประกอบ
ในสมุดบันทึกข้อมูลเชิงลึกการบีบอัดเราใช้ Matplotlib เพื่อพล็อตแผนภูมิแท่งของบทสรุปนี้ซึ่งแสดงการบีบอัดรอยเท้าที่ไม่น่าประทับใจ
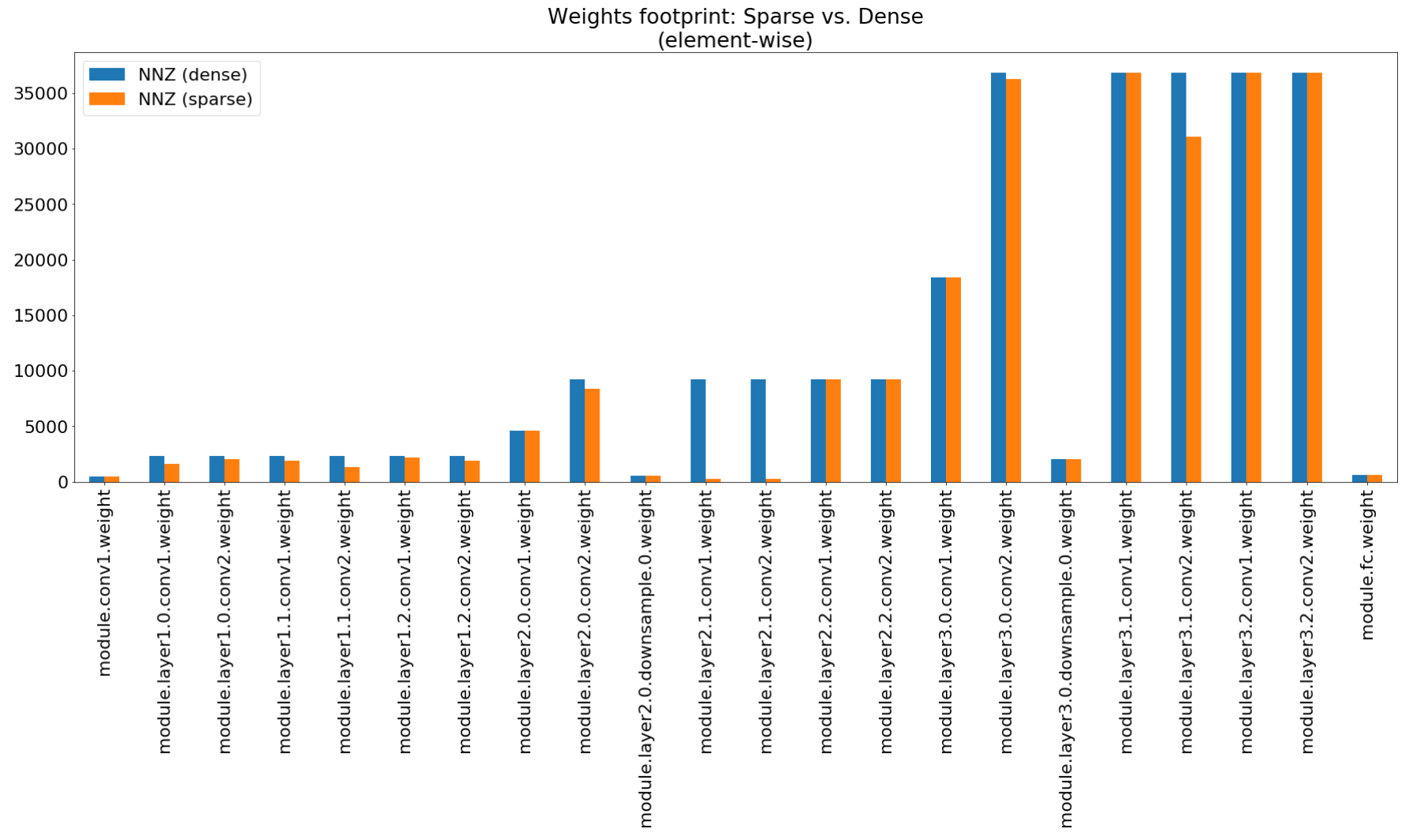
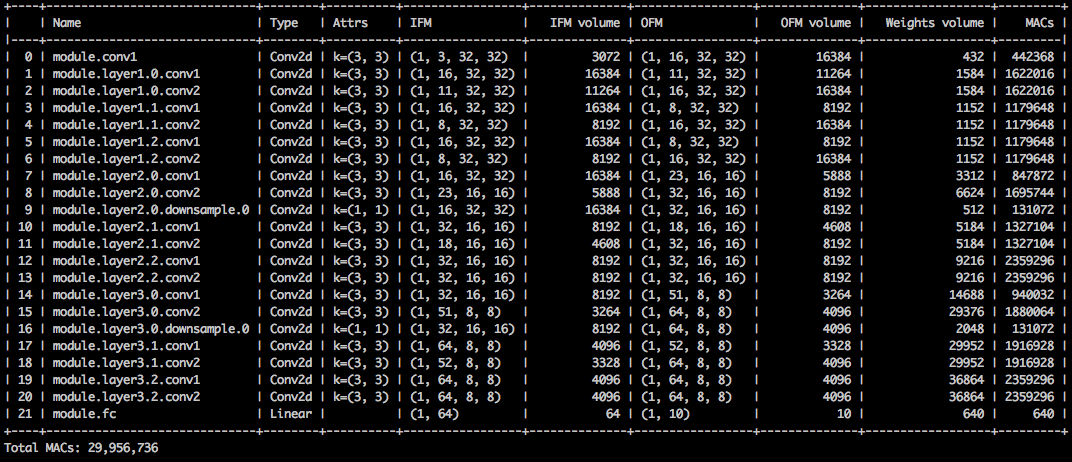
แม้ว่าการบีบอัดรอยเท้าหน่วยความจำจะต่ำมาก แต่รุ่นนี้จะประหยัดได้ 26.6% ของการคำนวณ MACS
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_channel_regularized_resnet20_finetuned.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=compute
ตัวอย่างนี้ดำเนินการเชิงปริมาณ 8 บิตของ RESNET20 สำหรับ CIFAR10 เราได้รวมอยู่ในที่เก็บ Git จุดตรวจสอบของรุ่น Resnet20 ที่เราได้รับการฝึกฝนด้วยลอย 32 บิตดังนั้นเราจะใช้รุ่นนี้และหาปริมาณ:
$ python3 compress_classifier.py -a resnet20_cifar ../../../data.cifar10 --resume ../ssl/checkpoints/checkpoint_trained_dense.pth.tar --quantize-eval --evaluate
บรรทัดคำสั่งด้านบนจะบันทึกจุดตรวจสอบชื่อ quantized_checkpoint.pth.tar ที่มีพารามิเตอร์แบบจำลองเชิงปริมาณ ดูตัวอย่างเพิ่มเติมที่นี่
ชุดโน้ตบุ๊กที่มาพร้อมกับ Distiller อธิบายไว้ที่นี่ซึ่งอธิบายขั้นตอนในการติดตั้งเซิร์ฟเวอร์ Jupyter Notebook
หลังจากติดตั้งและเรียกใช้เซิร์ฟเวอร์ให้ดูที่โน้ตบุ๊กที่ครอบคลุมการวิเคราะห์ความไวของการตัดแต่งกิ่ง
การวิเคราะห์ความไวเป็นกระบวนการที่ยาวนานและโน้ตบุ๊กนี้โหลดไฟล์ CSV ซึ่งเป็นผลลัพธ์ของการวิเคราะห์ความไวหลายครั้ง
ขณะนี้เรามีน้ำหนักเบาในการทดสอบและนี่คือพื้นที่ที่การบริจาคจะได้รับการชื่นชมมาก
การทดสอบมีสองประเภท: การทดสอบระบบและการทดสอบหน่วย เพื่อเรียกใช้การทดสอบหน่วย:
$ cd distiller/tests
$ pytest
เราใช้ CIFAR10 สำหรับการทดสอบระบบเนื่องจากขนาดของมันทำให้การทดสอบเร็วขึ้น ในการเรียกใช้การทดสอบระบบคุณต้องจัดเตรียมเส้นทางไปยังชุดข้อมูล CIFAR10 ที่คุณดาวน์โหลดไปแล้ว หรือคุณอาจเรียกใช้ full_flow_tests.py โดยไม่ระบุตำแหน่งของชุดข้อมูล CIFAR10 และปล่อยให้การทดสอบดาวน์โหลดชุดข้อมูล (สำหรับการเรียกใช้ครั้งแรกเท่านั้น) โปรดทราบว่า --cifar1o-path ค่าเริ่มต้นไปยังไดเรกทอรีปัจจุบัน
การทดสอบระบบไม่สั้นและยิ่งนานกว่านี้หากการทดสอบจำเป็นต้องดาวน์โหลดชุดข้อมูล
$ cd distiller/tests
$ python full_flow_tests.py --cifar10-path=<some_path>
สคริปต์ออกจากสถานะ 0 หากการทดสอบทั้งหมดสำเร็จหรือสถานะ 1 เป็นอย่างอื่น
ติดตั้ง mkdocs และแพ็คเกจที่ต้องการโดยการดำเนินการ:
$ pip3 install -r doc-requirements.txt
เพื่อสร้างเอกสารประกอบโครงการรัน:
$ cd distiller/docs-src
$ mkdocs build --clean
สิ่งนี้จะสร้างโฟลเดอร์ชื่อ 'ไซต์' ซึ่งมีเว็บไซต์เอกสาร เปิดเครื่องกลั่น/เอกสาร/ไซต์/index.html เพื่อดูโฮมเพจเอกสาร
เราใช้ semver สำหรับการกำหนดเวอร์ชัน สำหรับเวอร์ชันที่มีให้ดูที่แท็กในที่เก็บนี้
โครงการนี้ได้รับอนุญาตภายใต้ Apache License 2.0 - ดูไฟล์ License.md สำหรับรายละเอียด
แบบจำลองการตัดแต่ง Degirum - ที่เก็บที่มีโมเดลตัดแต่งและข้อมูลที่เกี่ยวข้อง
Torchfi - Torchfi เป็นกรอบการฉีดข้อผิดพลาดที่สร้างขึ้นบน Pytorch เพื่อวัตถุประสงค์ในการวิจัย
HSI -Toolbox - การบีบอัด CNN Hyperspectral และการเลือกวงดนตรี
Brunno F. Goldstein, Sudarshan Srinivasan, Dipankar Das, Kunal Banerjee, Leandro Santiago, Victor C. Ferreira, Alexandre S. Nery, Sandip Kundu, Felipe MG Franca
การประเมินความน่าเชื่อถือของแบบจำลองการเรียนรู้เชิงลึกที่บีบอัด
ใน IEEE ครั้งที่ 11 Latin American Symposium เกี่ยวกับวงจรและระบบ (LASCAs), San Jose, Costa Rica, 2020, pp. 1-5
Pascal Bacchus, Robert Stewart, Ekaterina Komendantskaya
ความแม่นยำเวลาการฝึกอบรมและประสิทธิภาพของฮาร์ดแวร์การแลกเปลี่ยนสำหรับเครือข่ายประสาทเชิงปริมาณใน FPGAs
ในการคำนวณที่กำหนดค่าใหม่ได้ สถาปัตยกรรมเครื่องมือและแอปพลิเคชัน ARC 2020. หมายเหตุการบรรยายในวิทยาศาสตร์คอมพิวเตอร์, ฉบับที่ 12083. Springer, Cham
Indranil Chakraborty, Mustafa Fayez Ali, Dong Eun Kim, Aayush Ankit, Kaushik Roy
Geniex: วิธีการทั่วไปในการเลียนแบบความไม่ชัดเจนใน XBARs ที่มีความทรงจำโดยใช้เครือข่ายประสาท
Arxiv: 2003.06902, 2020
Ahmed T. Elthakeb, Prannoy Pilligundla, Fatemehsadat Mireshghallah, Tarek Elgindi, Charles-Alban DeLedalle, Hadi Esmaeilzadeh
การเพิ่มปริมาณการไล่ระดับของเครือข่ายประสาทลึกผ่านการปรับตัวแบบไซน์
Arxiv: 2003.00146, 2020
Ziqing Yang, Yiming Cui, Zhipeng Chen, Wanxiang Che, Ting Liu, Shijin Wang, Guoping Hu
TextBrewer: ชุดเครื่องมือกลั่นความรู้โอเพ่นซอร์สสำหรับการประมวลผลภาษาธรรมชาติ
Arxiv: 2002.12620, 2020
Alexander Kozlov, Ivan Lazarevich, Vasily Shamporov, Nikolay Lyalyushkin, Yury Gorbachev
กรอบการบีบอัดของเครือข่ายประสาทสำหรับการอนุมานแบบจำลองอย่างรวดเร็ว
Arxiv: 2002.08679, 2020
Moran Shkolnik, Brian Chmiel, Ron Banner, Gil Shomron, Yuri Nahshan, Alex Bronstein, Uri Weiser
Quantization ที่แข็งแกร่ง: แบบจำลองเดียวที่จะปกครองพวกเขาทั้งหมด
Arxiv: 2002.07686, 2020
Muhammad Abdullah Hanif, Muhammad Shafique
SALVAGENTNN: การช่วยเร่งความเร็วเครือข่ายประสาทลึกที่มีความผิดพลาดถาวรผ่านการทำแผนที่ความผิดพลาดที่ได้รับการช่วยเหลือ
ในการทำธุรกรรมทางปรัชญาของ Royal Society A: คณิตศาสตร์วิทยาศาสตร์กายภาพและวิศวกรรมศาสตร์ 378 ฉบับที่ 2164, 2019
https://doi.org/10.1098/rsta.2019.0164
Meiqi Wang, Jianqiao Mo, Jun Lin, Zhongfeng Wang, Li Du
Dynexit: กลยุทธ์การออกจากช่วงต้นแบบไดนามิกสำหรับเครือข่ายที่เหลืออยู่ลึก
ใน IEEE International Workshop เกี่ยวกับระบบประมวลผลสัญญาณ (SIPS), 2019
Vinu Joseph, Saurav Muralidharan, Animesh Garg, Michael Garland, Ganesh Gopalakrishnan
วิธีการที่ตั้งโปรแกรมได้ในการสร้างแบบจำลองการบีบอัด
Arxiv: 1911.02497, 2019
รหัส
Hui Guan, Lin Ning, Zhen Lin, Xipeng Shen, Huiyang Zhou, Seung-Hwan Lim
การป้องกันหน่วยความจำในพื้นที่ศูนย์ในสถานที่สำหรับ CNN
ในการประชุมเกี่ยวกับระบบประมวลผลข้อมูลระบบประสาท (Neurips), 2019
Arxiv: 1910.14479, 2019
รหัส
Hossein Baktash, Emanuele Natale, Laurent Viennot
การศึกษาเปรียบเทียบการบีบอัดเครือข่ายประสาท
Arxiv: 1910.11144, 2019
Maxim Zemlyanikin, Alexander Smorkalov, Tatiana Khanova, Anna Petrovicheva, Grigory Serebryakov
512kib Ram ก็เพียงพอแล้ว! การจดจำใบหน้ากล้องถ่ายทอดสด DNN บน MCU
ใน IEEE International Conference on Computer Vision (ICCV), 2019
Ziheng Wang, Jeremy Wohlwend, Tao Lei
การตัดแต่งกิ่งที่มีโครงสร้างของแบบจำลองภาษาขนาดใหญ่
Arxiv: 1910.04732, 2019
Soroush Ghodrati, Hardik Sharma, Sean Kinzer, Amir Yazdanbakhsh, Kambiz Samadi, Nam Sung Kim, Doug Burger, Hadi Esmaeilzadeh
การเร่งความเร็วของโดเมนประจุสัญญาณผสมของเครือข่ายประสาทลึกผ่านเลขคณิตบิตแบบพาร์ติชันแบบ interleaved
Arxiv: 1906.11915, 2019
Gil Shomron, Tal Horowitz, Uri Weiser
SMT-SA: มัลติเธรดพร้อมกันในอาร์เรย์ systolic
ในจดหมายสถาปัตยกรรมคอมพิวเตอร์ IEEE (CAL), 2019
Shangqian Gao, Cheng Deng และ Heng Huang
การบีบอัดแบบจำลองโดเมนข้ามโดยการแบ่งปันน้ำหนักโครงสร้าง
ในการประชุม IEEE เกี่ยวกับการมองเห็นและการจดจำรูปแบบคอมพิวเตอร์ (CVPR), 2019, pp. 8973-8982
Moin Nadeem, Wei Fang, Brian Xu, Mitra Mohtarami, James Glass
FAKTA: ระบบตรวจสอบข้อเท็จจริงแบบ end-to-end อัตโนมัติ
ในบทอเมริกาเหนือของสมาคมเพื่อการคำนวณภาษาศาสตร์ (NAACL), 2019
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh
SINREQ: การทำให้เป็นปกติแบบไซน์ทั่วไปสำหรับการฝึกอบรมเชิงปริมาณที่ลึกลงไปในระดับต่ำ
arxiv: 1905.01416, 2019. รหัส
Goncharenko A. , Denisov A. , Alyamkin S. , Terentev E.
เกณฑ์ที่สามารถฝึกอบรมได้สำหรับการหาปริมาณเครือข่ายประสาท
ใน: Rojas I. , Joya G. , Catala A. (eds) ความก้าวหน้าในการบรรยายการบรรยายข่าวกรองการคำนวณในวิทยาศาสตร์คอมพิวเตอร์, ฉบับที่ 11507 Springer, Cham. การประชุมระหว่างประเทศเกี่ยวกับเครือข่ายประสาทเทียม (Iwann 2019)
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh
หารและพิชิต: การใช้ประโยชน์จากการเป็นตัวแทนคุณลักษณะระดับกลางสำหรับการฝึกอบรมเชิงปริมาณของเครือข่ายประสาท
Arxiv: 1906.06033, 2019
Ritchie Zhao, Yuwei Hu, Jordan Dotzel, Christopher de Sa, Zhiru Zhang
การปรับปรุงปริมาณเครือข่ายประสาทโดยไม่ต้องฝึกอบรมการแยกช่องทางนอก
Arxiv: 1901.09504, 2019
รหัส
Angad S. Rekhi, Brian Zimmer, Nikola Nedovic, Ningxi Liu, Rangharajan Venkatesan, Miaorong Wang, Brucek Khailany, William J. Dally, C. Thomas Gray
การสร้างแบบจำลองข้อผิดพลาดของฮาร์ดแวร์แบบอะนาล็อก/สัญญาณผสมสำหรับการอนุมานการเรียนรู้อย่างลึกซึ้ง
Nvidia Research, 2019
Norio Nakata
การพัฒนาทางเทคนิคล่าสุดของปัญญาประดิษฐ์สำหรับการถ่ายภาพทางการแพทย์วินิจฉัย
ในวารสารรังสีวิทยาญี่ปุ่นกุมภาพันธ์ 2019 เล่มที่ 37 ฉบับที่ 2, หน้า 103–108
Alexander Goncharenko, Andrey Denisov, Sergey Alyamkin, Evgeny Terentev
เกณฑ์ที่ปรับได้อย่างรวดเร็วสำหรับการหาปริมาณเครือข่ายประสาทสม่ำเสมอ
Arxiv: 1812.07872, 2018
หากคุณใช้เครื่องกลั่นสำหรับงานของคุณโปรดใช้การอ้างอิงต่อไปนี้:
@article{nzmora2019distiller,
author = {Neta Zmora and
Guy Jacob and
Lev Zlotnik and
Bar Elharar and
Gal Novik},
title = {Neural Network Distiller: A Python Package For DNN Compression Research},
month = {October},
year = {2019},
url = {https://arxiv.org/abs/1910.12232}
}
งานที่ตีพิมพ์ใด ๆ ถูกสร้างขึ้นบนผลงานของคนอื่น ๆ อีกมากมายและเครดิตเป็นของคนจำนวนมากเกินไปที่จะแสดงรายการที่นี่
Distiller ได้รับการปล่อยตัวเป็นรหัสอ้างอิงเพื่อวัตถุประสงค์ในการวิจัย ไม่ใช่ผลิตภัณฑ์ Intel อย่างเป็นทางการและระดับคุณภาพและการสนับสนุนอาจไม่เป็นไปตามที่คาดหวังจากผลิตภัณฑ์อย่างเป็นทางการ อัลกอริทึมและคุณสมบัติเพิ่มเติมมีการวางแผนที่จะเพิ่มเข้าไปในห้องสมุด ข้อเสนอแนะและการมีส่วนร่วมจากชุมชนโอเพ่นซอร์สและชุมชนการวิจัยได้รับการต้อนรับมากกว่า


