distiller
1.0.0
️ Arrêt du projet - Ce projet ne sera plus maintenu par Intel. Ce projet a été identifié comme ayant des évasions de sécurité connues. Intel a cessé le développement et les contributions, y compris, mais sans s'y limiter, la maintenance, les corrections de bogues, les nouvelles versions ou les mises à jour, vers ce projet. Intel n'accepte plus les correctifs de ce projet.

Distiller est un package Python open source pour la recherche de compression de réseaux neuronaux.
La compression du réseau peut réduire l'empreinte mémoire d'un réseau neuronal, augmenter sa vitesse d'inférence et économiser de l'énergie. Distiller fournit un environnement pytorche pour le prototypage et l'analyse des algorithmes de compression, tels que les méthodes induisant la rareté et l'arithmétique à faible précision.
Ces instructions aideront à faire fonctionner Distiller sur votre machine locale.
Clone Le référentiel de code de distillateur de GitHub:
$ git clone https://github.com/IntelLabs/distiller.git
Le reste de la documentation qui suit, suppose que vous avez cloné votre référentiel à un répertoire appelé distiller .
Nous vous recommandons d'utiliser un environnement virtuel Python, mais bien sûr, cela dépend de vous. Il n'y a rien de spécial à utiliser Distiller dans un environnement virtuel, mais nous fournissons quelques instructions, pour l'exhaustivité.
Avant de créer l'environnement virtuel, assurez-vous que vous êtes situé dans Directory distiller . Après avoir créé l'environnement, vous devriez voir un répertoire appelé distiller/env .
Si vous n'avez pas installé VirtualEnv, vous pouvez trouver les instructions d'installation ici.
Pour créer l'environnement, exécutez:
$ python3 -m virtualenv env
Cela crée un sous-répertoire nommé env où l'environnement virtuel Python est stocké et configure le shell actuel pour l'utiliser comme environnement Python par défaut.
Si vous préférez utiliser venv , commencez par l'installer:
$ sudo apt-get install python3-venv
Créez ensuite l'environnement:
$ python3 -m venv env
Comme pour VirtualEnv, cela crée un répertoire appelé distiller/env .
Les commandes d'activation et de désactivation de l'environnement pour venv et virtualenv sont les mêmes.
! Remarque: assurez-vous d'activer l'environnement, avant de procéder à l'installation des packages de dépendance:
$ source env/bin/activate
Enfin, installez le package Distiller et ses dépendances à l'aide de pip3 :
$ cd distiller
$ pip3 install -e .
Cela installe le distillateur dans "Mode de développement", ce qui signifie que toutes les modifications apportées dans le code sont reflétées dans l'environnement sans relancer la commande d'installation (donc pas besoin de réinstaller après avoir tiré les modifications du référentiel GIT).
Notes:
Distiller est testé à l'aide de l'installation par défaut de Pytorch 1.3.1, qui utilise CUDA 10.1. Nous utilisons la version 0.4.2 de TorchVision. Ceux-ci sont inclus dans requirements.txt de Distiller.txt et seront automatiquement installés lors de l'installation du package Distiller comme indiqué ci-dessus.
Si vous n'utilisez pas CUDA 10.1 dans votre environnement, veuillez vous référer au site Web de Pytorch pour installer la construction compatible de Pytorch 1.3.1 et TorchVision 0.4.2.
Distiller est livré avec des exemples d'applications et de tutoriels couvrant une gamme de types de modèles:
| Type de modèle | Rareté | Quantification post-entraînement | Formation consciente de la quantification | Compression automatique (AMC) | Distillation des connaissances |
|---|---|---|---|---|---|
| Classification d'image | ✅ | ✅ | ✅ | ✅ | ✅ |
| Modèle de langue au niveau des mots | ✅ | ✅ | |||
| Traduction (GNMT) | ✅ | ||||
| Système de recommandation (NCF) | ✅ | ||||
| Détection d'objet | ✅ |
Dirigez-vous vers le répertoire des exemples pour plus de détails.
Autres ressources pour se référer, au-delà des exemples:
Voici des exemples simples à l'aide de l'échantillon de classification d'images de Distiller, montrant certaines des capacités de Distiller.
Ce qui suit invoquera la formation uniquement (pas de compression) d'un réseau nommé «Simplenet» sur l'ensemble de données CIFAR10. Ceci est à peu près basé sur l'échantillon d'application de formation ImageNet de TorchVision, il devrait donc sembler familier si vous avez utilisé cette application. Dans cet exemple, nous n'invoquons aucun mécanisme de compression: nous nous entraînons simplement parce que pour un réglage fin après élagage, la formation est une partie essentielle.
Notez que la première fois que vous exécutez cette commande, le code CIFAR10 sera téléchargé sur votre machine, ce qui peut prendre un peu de temps - veuillez laisser le processus de téléchargement passer à l'achèvement.
Le chemin d'accès à l'ensemble de données CIFAR10 est arbitraire, mais dans nos exemples, nous plaçons les ensembles de données dans le même niveau de répertoire que Distiller (c'est-à-dire ../../../data.cifar10 ).
Tout d'abord, passez à l'exemple de répertoire, puis invoquez l'application:
$ cd distiller/examples/classifier_compression
$ python3 compress_classifier.py --arch simplenet_cifar ../../../data.cifar10 -p 30 -j=1 --lr=0.01
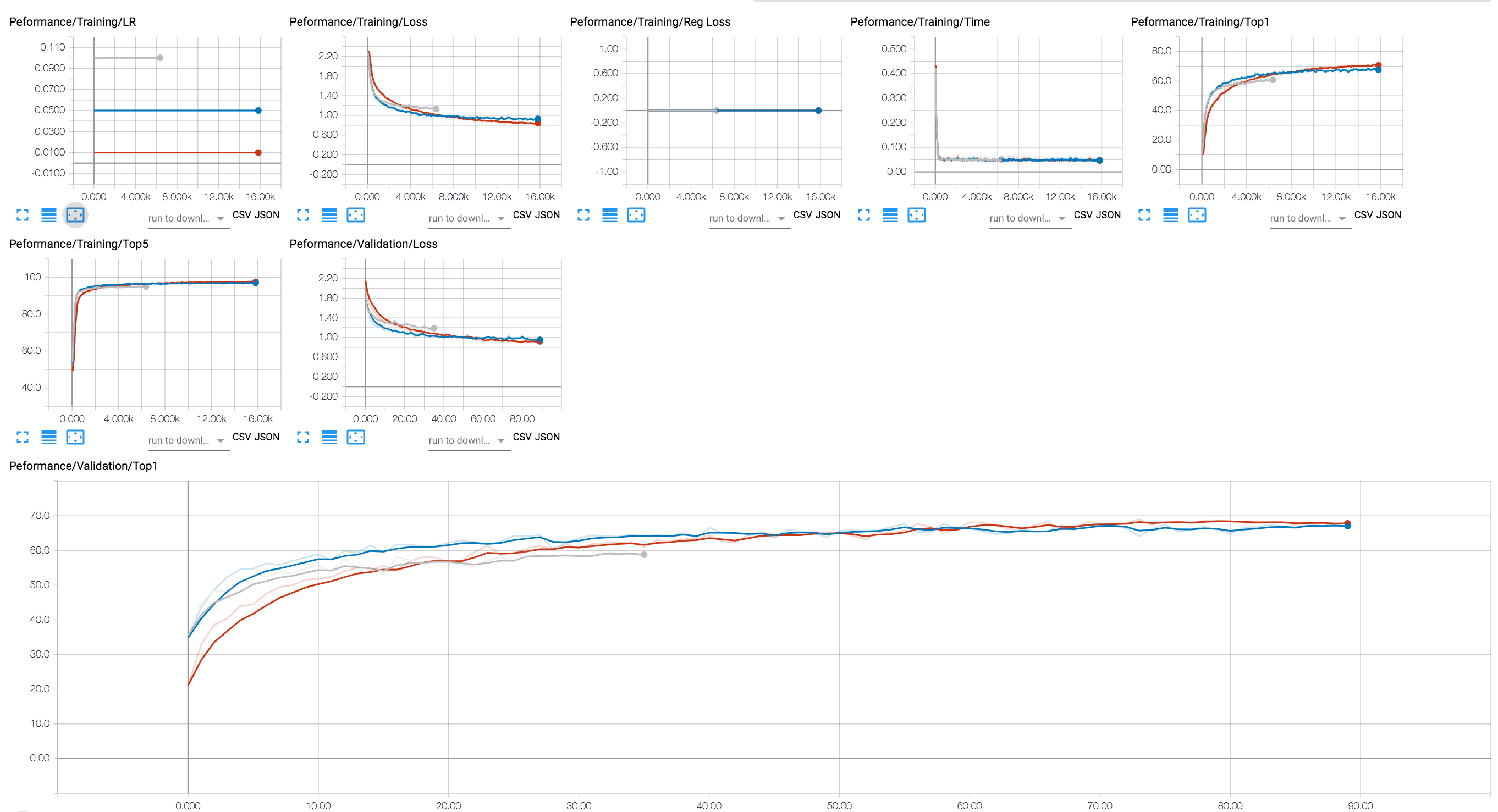
Vous pouvez utiliser un backend Tensorboard pour voir la progression de la formation (dans le diagramme ci-dessous, nous montrons quelques séances de formation avec différentes valeurs LR). Pour les séances de compression, nous avons ajouté le traçage des niveaux d'activation et de rareté des paramètres et la perte de régularisation.
Nous avons inclus dans le référentiel GIT quelques points de contrôle d'un modèle RESNET20 que nous avons formé avec des flotteurs 32 bits. Chargez le point de contrôle d'un modèle que nous avons formé avec la régularisation du groupe Lasso en termes de canal.
Avec les arguments de ligne de commande suivants, l'exemple d'application charge le modèle ( --resume ) et imprime des statistiques sur les poids du modèle ( --summary=sparsity ). Ceci est utile si vous souhaitez charger un modèle précédemment élaqué, pour examiner les statistiques de rareté de poids, par exemple. Notez que lorsque vous reprenez un point de contrôle stocké, vous devez toujours dire à l'application quelle architecture réseau utilise le point de contrôle ( -a=resnet20_cifar ):
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_ch_regularized_dense.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=sparsity
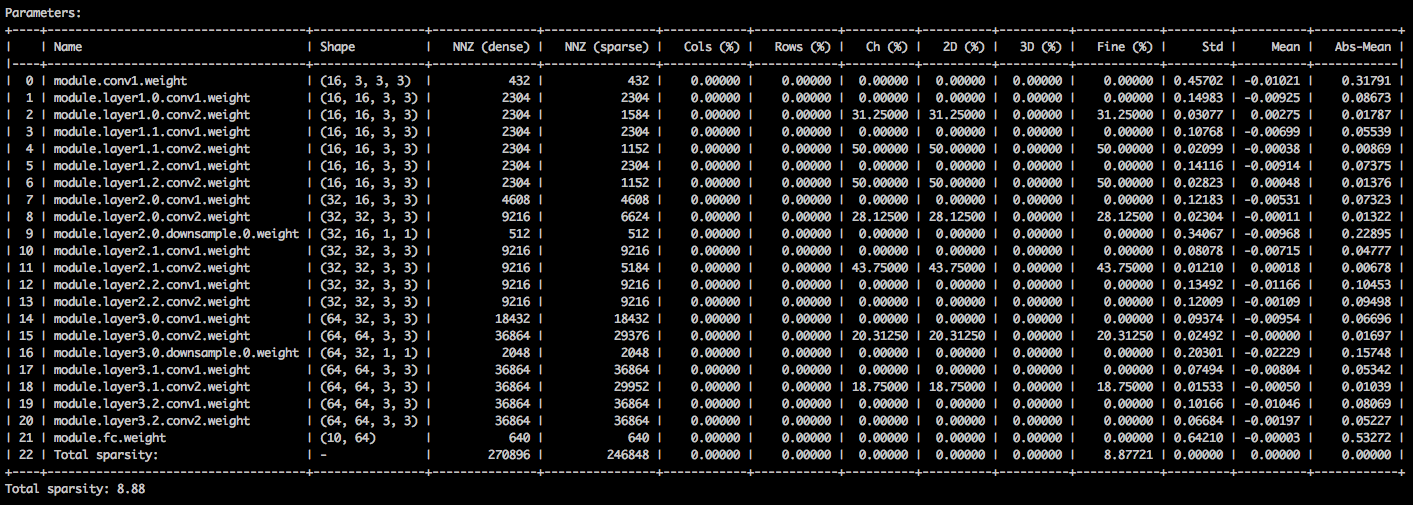
Vous devriez voir un tableau de texte détaillant les différentes sparsités des tenseurs de paramètres. La première colonne est le nom du paramètre, suivi de sa forme, le nombre d'éléments non nuls (NNZ) dans le modèle dense et dans le modèle clairsemé. L'ensemble suivant de colonnes affiche les sparsités de la colonne, au niveau de la ligne, du canal, au niveau du noyau, du filtre et d'élément.
L'enveloppement est la diation standard, la moyenne et la moyenne des valeurs absolues des éléments.
Dans le cahier de compression Insights, nous utilisons Matplotlib pour tracer un graphique à barres de ce résumé, qui montre en effet une compression d'empreinte non impressionnante.
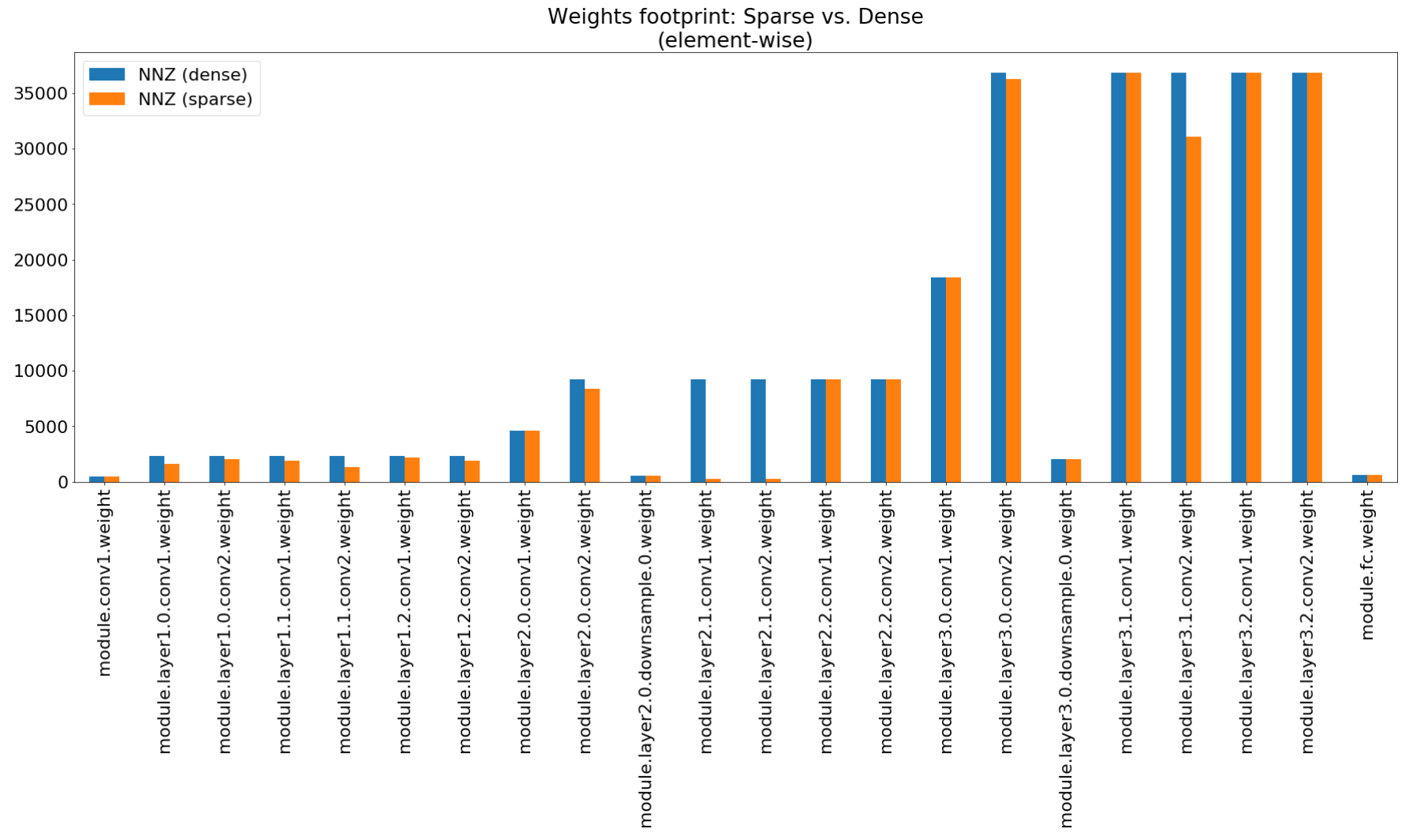
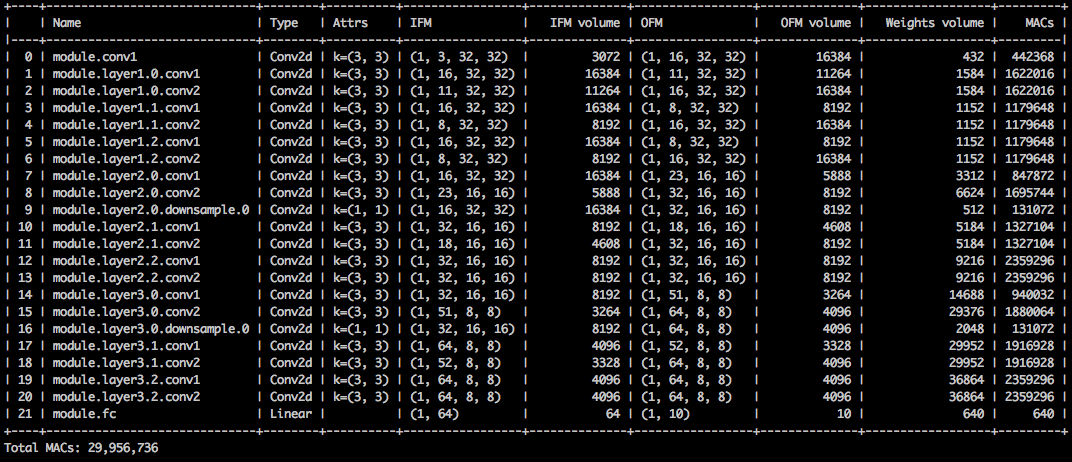
Bien que la compression de l'empreinte mémoire soit très faible, ce modèle économise en fait 26,6% du calcul Mac.
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_channel_regularized_resnet20_finetuned.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=compute
Cet exemple effectue une quantification 8 bits de RESNET20 pour CIFAR10. Nous avons inclus dans le référentiel GIT le point de contrôle d'un modèle RESNET20 que nous avons formé avec des flotteurs 32 bits, nous allons donc prendre ce modèle et le quantifier:
$ python3 compress_classifier.py -a resnet20_cifar ../../../data.cifar10 --resume ../ssl/checkpoints/checkpoint_trained_dense.pth.tar --quantize-eval --evaluate
La ligne de commande ci-dessus enregistrera un point de contrôle nommé quantized_checkpoint.pth.tar contenant les paramètres du modèle quantifié. Voir plus d'exemples ici.
L'ensemble des cahiers accompagnés avec Distiller est décrit ici, qui explique également les étapes pour installer le serveur de notes Jupyter.
Après avoir installé et exécuté le serveur, jetez un œil à l'analyse de sensibilité à l'élagage couvrant.
L'analyse de sensibilité est un long processus et ce ordinateur portable charge les fichiers CSV qui sont la sortie de plusieurs séances d'analyse de sensibilité.
Nous sommes actuellement légers à l'essai et c'est un domaine où les contributions seront très appréciées.
Il existe deux types de tests: les tests système et les tests unitaires. Pour invoquer les tests unitaires:
$ cd distiller/tests
$ pytest
Nous utilisons CIFAR10 pour les tests système, car sa taille rend les tests plus rapides. Pour invoquer les tests système, vous devez fournir un chemin vers l'ensemble de données CIFAR10 que vous avez déjà téléchargé. Alternativement, vous pouvez invoquer full_flow_tests.py sans spécifier l'emplacement de l'ensemble de données CIFAR10 et laisser le test télécharger l'ensemble de données (pour la première invocation uniquement). Notez que --cifar1o-path fait défaut le répertoire actuel.
Les tests système ne sont pas courts et sont encore plus longs si le test doit télécharger l'ensemble de données.
$ cd distiller/tests
$ python full_flow_tests.py --cifar10-path=<some_path>
Le script sort avec le statut 0 si tous les tests sont réussis, ou le statut 1 autrement.
Installez les MKDOC et les packages requis en exécutant:
$ pip3 install -r doc-requirements.txt
Pour construire la documentation du projet:
$ cd distiller/docs-src
$ mkdocs build --clean
Cela créera un dossier nommé «Site» qui contient le site Web de documentation. Ouvrez distiller / docs / site / index.html pour afficher la page d'accueil de la documentation.
Nous utilisons Semver pour le versioning. Pour les versions disponibles, consultez les balises de ce référentiel.
Ce projet est sous licence en vertu de la licence Apache 2.0 - Voir le fichier licence.md pour plus de détails
Modèles élagués degirum - un référentiel contenant des modèles élagués et des informations connexes.
Torchfi - Torchfi est un cadre d'injection de défaut construit au-dessus de Pytorch à des fins de recherche.
HSI-Toolbox - Compression CNN hyperspectrale et sélection de bande
Brunno F. Goldstein, Sudarshan Srinivasan, Dipankar Das, Kunal Banerjee, Leandro Santiago, Victor C. Ferreira, Alexandre S. Nery, Sandip Kundu, Felipe MG Franca.
Évaluation de la fiabilité des modèles d'apprentissage en profondeur compressés ,
Dans IEEE 11th Latin American Symposium on Circuits & Systems (Lascas), San Jose, Costa Rica, 2020, pp. 1-5.
Pascal Bacchus, Robert Stewart, Ekaterina Komendantskaya.
Exactitude, temps de formation et compromis d'efficacité matérielle pour les réseaux de neurones quantifiés sur les FPGA ,
Dans l'informatique reconfigurable appliquée. Architectures, outils et applications. Arc 2020. Notes de cours en informatique, Vol 12083. Springer, Cham
Indranil Chakraborty, Mustafa Fayez Ali, Dong Eun Kim, Aayush Ankit, Kaushik Roy.
Geniex: une approche généralisée de l'émulation de non-idéalité dans les Xbars memristives à l'aide de réseaux de neurones ,
Arxiv: 2003.06902, 2020.
Ahmed T. Elthakeb, Prannoy Pilligundla, Fatemehsadat Mireshghallah, Tarek Elgindi, Charles-Alban Deledalle, Hadi Esmaeilzadeh.
Quantification profonde basée sur le gradient des réseaux de neurones par la régularisation adaptative sinusoïdale ,
Arxiv: 2003.00146, 2020.
Ziqing Yang, Yiming Cui, Zhiceng Chen, Wanxiang Che, Ting Liu, Shijin Wang, Guoping Hu.
TextBrewer: une boîte à outils de distillation de connaissances open source pour le traitement du langage naturel ,
Arxiv: 2002.12620, 2020.
Alexander Kozlov, Ivan Lazarevich, Vasily Shamporov, Nikolay Lyalyushkin, Yury Gorbatchev.
Cadre de compression de réseau neuronal pour l'inférence rapide du modèle ,
Arxiv: 2002.08679, 2020.
Moran Shkolnik, Brian Chmiel, Ron Banner, Gil Shomron, Yuri Nahshan, Alex Bronstein, Uri Weiser.
Quantification robuste: un modèle pour les gouverner tous ,
Arxiv: 2002.07686, 2020.
Muhammad Abdullah Hanif, Muhammad Shafique.
Salvagednn: Salvaging Deep Neural Network Accélérateurs avec des défauts permanents grâce à la cartographie consciente des failles, axée sur la saillance ,
Dans les transactions philosophiques de la Royal Society A: Sciences mathématiques, physiques et géniesVolume 378, numéro 2164, 2019.
https://doi.org/10.1098/rsta.2019.0164
Meiqi Wang, Jianqiao MO, Jun Lin, Zhongfeng Wang, Li du.
Dynexit: une stratégie dynamique en matière d'exit précoce pour les réseaux résiduels profonds ,
Dans IEEE International Workshop on Signal Processing Systems (SIPS), 2019.
Vinu Joseph, Saurav Muralidharan, Animesh Garg, Michael Garland, Ganesh Gopalakrishnan.
Une approche programmable de la compression du modèle,
Arxiv: 1911.02497, 2019
code
Hui Guan, Lin Ning, Zhen Lin, Xipeng Shen, Huiyang Zhou, Seung-Hwan Lim.
Protection de mémoire zéro espace en place pour CNN ,
Dans Conférence sur les systèmes de traitement de l'information neuronaux (INIPS), 2019.
Arxiv: 1910.14479, 2019
code
Hossein Baktash, Emanuele Natale, Laurent Viennot.
Une étude comparative de la compression du réseau neuronal ,
Arxiv: 1910.11144, 2019.
Maxim Zemlyanikin, Alexander Smorkalov, Tatiana Khanova, Anna Petrovicheva, Grigory Serebryakov.
512Kib RAM suffit! Reconnaissance de caméra en direct DNN sur MCU ,
Dans l'IEEE International Conference on Computer Vision (ICCV), 2019.
Ziheng Wang, Jeremy Wohlwend, Tao Lei.
Élagage structuré de grands modèles de langue ,
Arxiv: 1910.04732, 2019.
Soroush Ghodrati, Hardik Sharma, Sean Kinzer, Amir Yazdanbakhsh, Kambiz Samadi, Nam Sung Kim, Doug Burger, Hadi Esmaeilzadeh.
Accélération du domaine des charges mixtes des réseaux de neurones profonds à travers l'arithmétique entrelacée bit-bite ,
Arxiv: 1906.11915, 2019.
Gil Shomron, Tal Horowitz, Uri Weiser.
SMT-SA: Multithreading simultané dans les tableaux systolique ,
Dans IEEE Computer Architecture Letters (CAL), 2019.
Shangqian Gao, Cheng Deng et Heng Huang.
Compression du modèle de domaine croisé par partage de poids structurel,
Dans la conférence IEEE sur la vision par ordinateur et la reconnaissance des modèles (CVPR), 2019, pp. 8973-8982.
Moin Nadeem, Wei Fang, Brian Xu, Mitra Mohtarami, James Glass.
FAKTA: un système automatique de vérification des faits de bout en bout,
Dans le chapitre nord-américain de l'Association for Computational Linguistics (NAACL), 2019.
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh.
Sinreq: régularisation sinusoïdale généralisée pour une formation quantifiée en profondeur à faible qualité,
Arxiv: 1905.01416, 2019. Code
Goncarenko A., Denisov A., Alyamkin S., Terentev E.
Seuils formables pour la quantification du réseau neuronal,
Dans: Rojas I., Joya G., Catala A. (eds) Advances in Computational Intelligence Lecture Notes in Computer Science, vol 11507. Springer, Cham. Conférence internationale sur les réseaux de neurones artificiels (Iwann 2019).
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh.
Diviser et conquérir: tirer parti des représentations de caractéristiques intermédiaires pour la formation quantifiée des réseaux de neurones,
Arxiv: 1906.06033, 2019
Ritchie Zhao, Yuwei Hu, Jordan Dotzel, Christopher de SA, Zhiru Zhang.
Amélioration de la quantification du réseau neuronal sans recyclage en utilisant le fractionnement des canaux aberrants,
Arxiv: 1901.09504, 2019
Code
Angad S. Rekhi, Brian Zimmer, Nikola Nedovic, Ningxi Liu, Rangharajan Venkatesan, Miaorong Wang, Brucek Khailany, William J. Dally, C. Thomas Gray.
Modélisation d'erreur matérielle analogique / mixte pour l'inférence d'apprentissage en profondeur ,
Nvidia Research, 2019.
Norio Nakata.
Développement technique récent de l'intelligence artificielle pour l'imagerie médicale diagnostique ,
Dans Japanese Journal of Radiology, février 2019, volume 37, numéro 2, pp 103–108.
Alexander Goncarenko, Andrey Denisov, Sergey Alyamkin, Evgeny Terenntev.
Seuil réglable rapide pour la quantification uniforme du réseau neuronal ,
Arxiv: 1812.07872, 2018
Si vous avez utilisé Distiller pour votre travail, veuillez utiliser la citation suivante:
@article{nzmora2019distiller,
author = {Neta Zmora and
Guy Jacob and
Lev Zlotnik and
Bar Elharar and
Gal Novik},
title = {Neural Network Distiller: A Python Package For DNN Compression Research},
month = {October},
year = {2019},
url = {https://arxiv.org/abs/1910.12232}
}
Tout travail publié est construit en plus du travail de nombreuses autres personnes, et le crédit appartient à trop de personnes pour énumérer ici.
Distiller est publié sous forme de code de référence à des fins de recherche. Ce n'est pas un produit Intel officiel, et le niveau de qualité et de soutien peut ne pas être comme prévu d'un produit officiel. Des algorithmes et des fonctionnalités supplémentaires sont prévus pour être ajoutés à la bibliothèque. Les commentaires et les contributions des communautés open source et de recherche sont plus que les bienvenus.


