distiller
1.0.0
️ Descontinuação do projeto - Este projeto não será mais mantido pela Intel. Este projeto foi identificado como tendo escapadas de segurança conhecidas. A Intel cessou o desenvolvimento e as contribuições, incluindo, entre outros, manutenção, correções de bugs, novos lançamentos ou atualizações para este projeto. A Intel não aceita mais patches para este projeto.

O destilador é um pacote Python de código aberto para pesquisa de compressão de rede neural.
A compactação de rede pode reduzir a pegada de memória de uma rede neural, aumentar sua velocidade de inferência e economizar energia. O destilador fornece um ambiente de pytorch para prototipagem e análise de algoritmos de compressão, como métodos indutores de escassez e aritmética de baixa precisão.
Essas instruções ajudarão a colocar o destilador em funcionamento em sua máquina local.
Clone o repositório de código do destilador do Github:
$ git clone https://github.com/IntelLabs/distiller.git
O restante da documentação a seguir, pressupõe que você tenha clonado seu repositório para um diretório chamado distiller .
Recomendamos o uso de um ambiente virtual do Python, mas isso é claro, depende de você. Não há nada de especial no uso do destilador em um ambiente virtual, mas fornecemos algumas instruções para a completude.
Antes de criar o ambiente virtual, verifique se você está localizado no Directory distiller . Depois de criar o ambiente, você deve ver um diretório chamado distiller/env .
Se você não possui o VirtualEnv instalado, pode encontrar as instruções de instalação aqui.
Para criar o ambiente, execute:
$ python3 -m virtualenv env
Isso cria um subdiretório chamado env , onde o ambiente virtual do Python é armazenado e configura o shell atual para usá -lo como o ambiente Python padrão.
Se você preferir usar venv , comece a instalar:
$ sudo apt-get install python3-venv
Em seguida, crie o ambiente:
$ python3 -m venv env
Como no VirtualEnv, isso cria um diretório chamado distiller/env .
Os comandos de ativação e desativação do ambiente para venv e virtualenv são os mesmos.
NOTA: Certifique -se de ativar o ambiente, antes de prosseguir com a instalação dos pacotes de dependência:
$ source env/bin/activate
Por fim, instale o pacote destilador e suas dependências usando pip3 :
$ cd distiller
$ pip3 install -e .
Isso instala o destilador no "modo de desenvolvimento", o que significa que quaisquer alterações feitas no código são refletidas no ambiente sem executar o comando de instalação (para que não seja necessário reinstalar após a retirada do repositório Git).
Notas:
O destilador é testado usando a instalação padrão do Pytorch 1.3.1, que usa o CUDA 10.1. Usamos a versão 0.4.2 da Torchvision. Estes estão incluídos nos requirements.txt do destilador.txt e serão instalados automaticamente ao instalar o pacote destilador, conforme listado acima.
Se você não usar o CUDA 10.1 em seu ambiente, consulte o site da Pytorch para instalar a construção compatível do Pytorch 1.3.1 e a Torchvision 0.4.2.
O destilador vem com aplicativos de amostra e tutoriais que cobrem uma variedade de tipos de modelos:
| Tipo de modelo | Esparsidade | Quantização pós-treinamento | Treinamento com reconhecimento de quantização | Compressão automática (AMC) | Destilação do conhecimento |
|---|---|---|---|---|---|
| Classificação da imagem | ✅ | ✅ | ✅ | ✅ | ✅ |
| Modelo de linguagem no nível da palavra | ✅ | ✅ | |||
| Tradução (GNMT) | ✅ | ||||
| Sistema de recomendação (NCF) | ✅ | ||||
| Detecção de objetos | ✅ |
Vá para o diretório exemplos para obter mais detalhes.
Outros recursos a se referir, além dos exemplos:
A seguir, são apresentados exemplos simples usando a amostra de classificação da imagem do destilador, mostrando alguns dos recursos do destilador.
A seguir, invocará apenas o treinamento (sem compactação) de uma rede chamada 'Simplenet' no conjunto de dados CIFAR10. Isso é baseado aproximadamente no aplicativo de treinamento do ImageNet da TorchVision, para que pareça familiar se você usou esse aplicativo. Neste exemplo, não invocamos nenhum mecanismos de compressão: apenas treinamos porque, para ajuste fino após a poda, o treinamento é uma parte essencial.
Observe que, na primeira vez em que você executar este comando, o código CIFAR10 será baixado para sua máquina, o que pode levar um pouco de tempo - deixe o processo de download prosseguir até a conclusão.
O caminho para o conjunto de dados CIFAR10 é arbitrário, mas em nossos exemplos colocamos os conjuntos de dados no mesmo nível de diretório que o destilador (ou seja, ../../../data.cifar10 ).
Primeiro, mude para o diretório de amostra e invoca o aplicativo:
$ cd distiller/examples/classifier_compression
$ python3 compress_classifier.py --arch simplenet_cifar ../../../data.cifar10 -p 30 -j=1 --lr=0.01
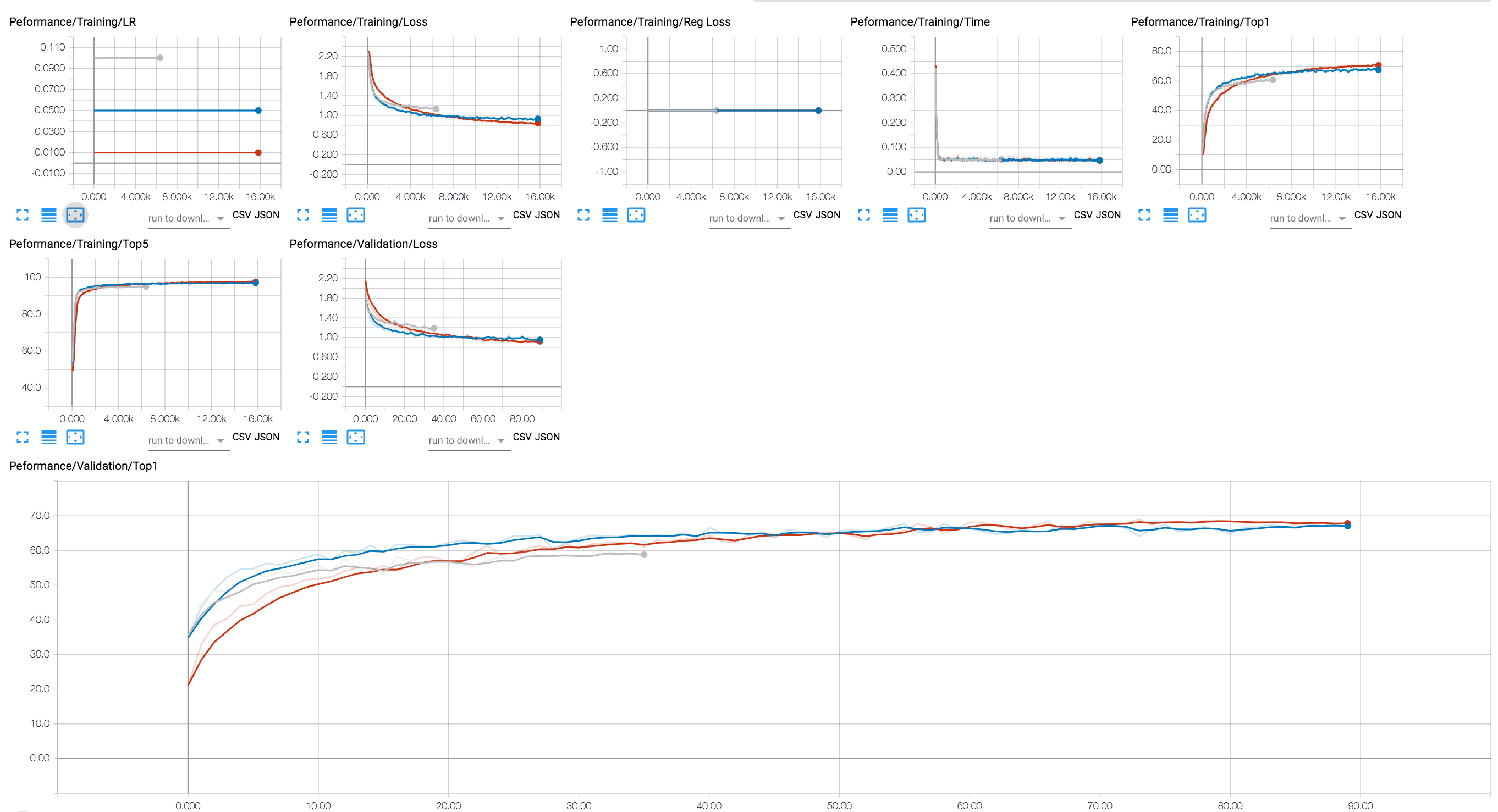
Você pode usar um back -end do Tensorboard para visualizar o progresso do treinamento (no diagrama abaixo, mostramos algumas sessões de treinamento com diferentes valores de LR). Para sessões de compressão, adicionamos o rastreamento dos níveis de ativação e esparsidade de parâmetros e perda de regularização.
Incluímos no repositório Git alguns pontos de verificação de um modelo RESNET20 que treinamos com carros alegóricos de 32 bits. Vamos carregar o ponto de verificação de um modelo que treinamos com a regularização do Lasso em grupo no canal.
Com os seguintes argumentos da linha de comando, o aplicativo de amostra carrega o modelo ( --resume ) e imprime as estatísticas sobre os pesos do modelo ( --summary=sparsity ). Isso é útil se você deseja carregar um modelo de poda anteriormente, para examinar as estatísticas de escassez de pesos, por exemplo. Observe que quando você retomar um ponto de verificação armazenado, você ainda precisa informar ao aplicativo qual arquitetura de rede o ponto de verificação usa ( -a=resnet20_cifar ):
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_ch_regularized_dense.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=sparsity
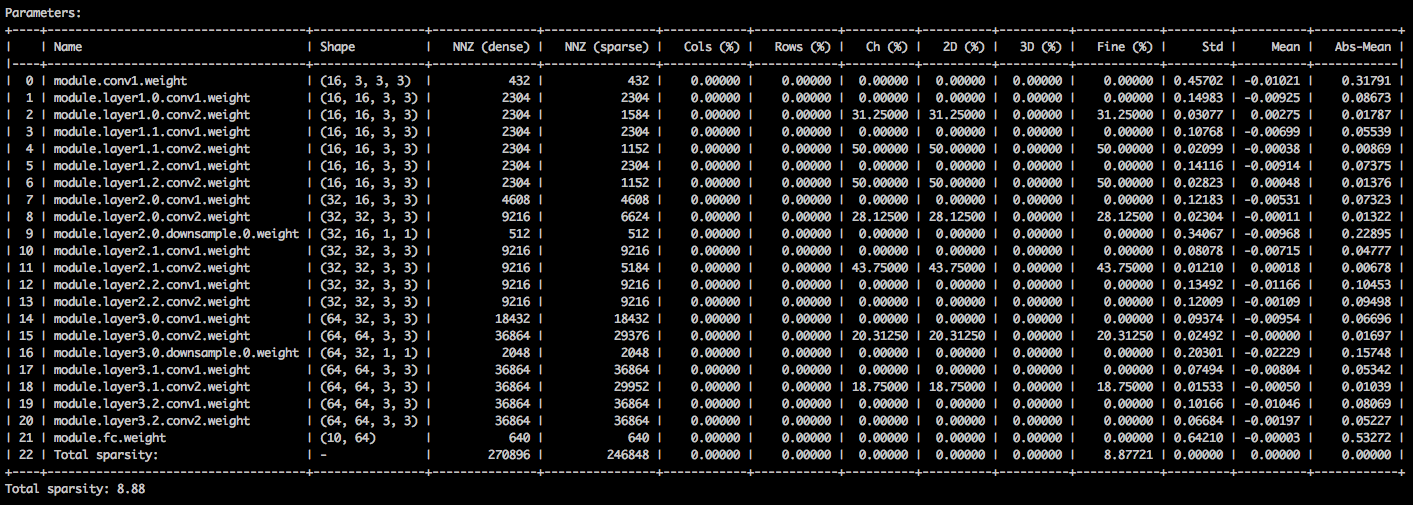
Você deve ver uma tabela de texto detalhando as várias esparsidades dos tensores de parâmetros. A primeira coluna é o nome do parâmetro, seguido por sua forma, o número de elementos diferentes de zero (NNZ) no modelo denso e no modelo esparso. O próximo conjunto de colunas mostra as escalas, em termos de coluna, emoções, em termos de canal, em termos de kernel, em termos de filtro e em termos de elementos.
Enganchá-lo são a devista padrão, a média e a média dos valores absolutos dos elementos.
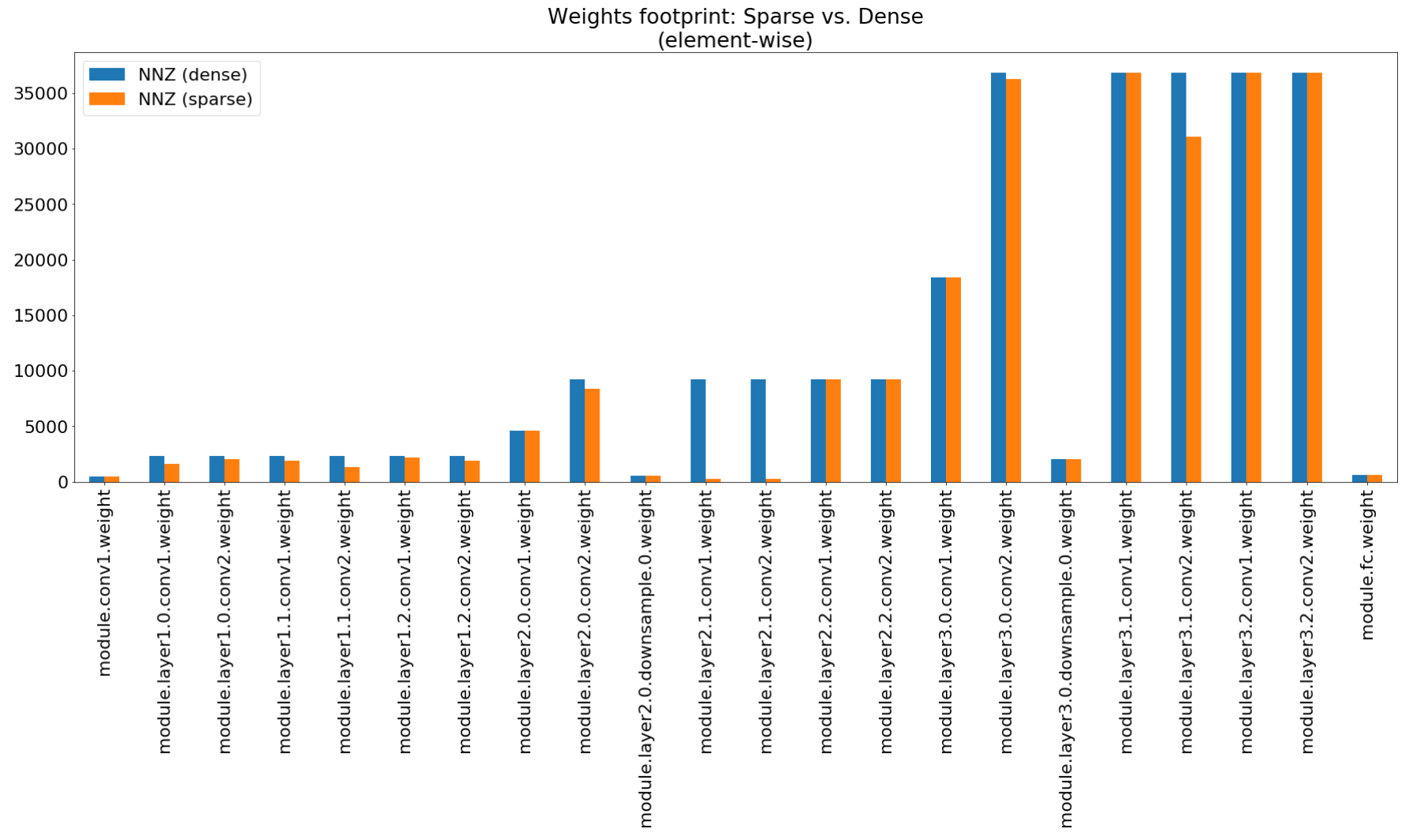
No notebook de insights de compactação, usamos o matplotlib para plotar um gráfico de barras deste resumo, que realmente mostra compactação de pegada não pressionada.
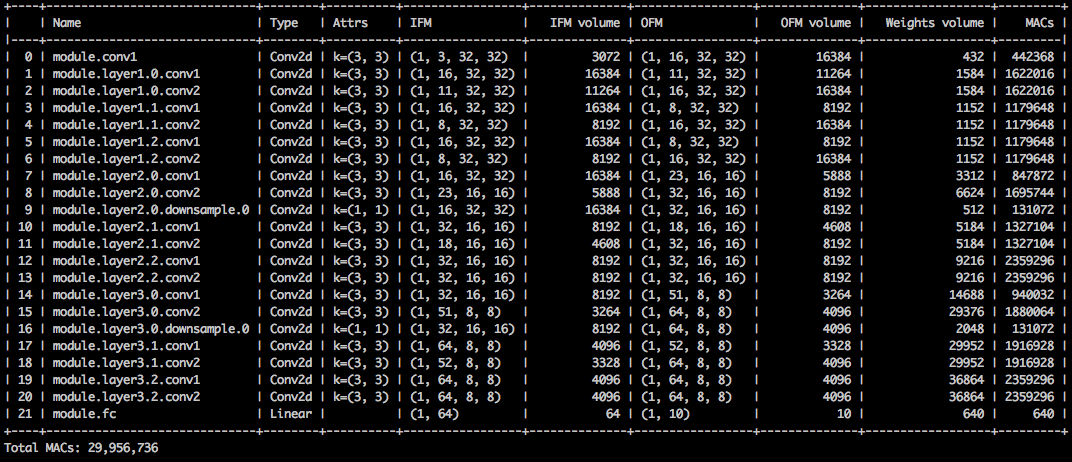
Embora a compactação de pegada de memória seja muito baixa, esse modelo realmente economiza 26,6% da computação do MACS.
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_channel_regularized_resnet20_finetuned.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=compute
Este exemplo executa quantização de 8 bits de resNet20 para CIFAR10. Incluímos no repositório Git o ponto de verificação de um modelo RESNET20 que treinamos com carros alegóricos de 32 bits, então pegaremos esse modelo e quantizamos:
$ python3 compress_classifier.py -a resnet20_cifar ../../../data.cifar10 --resume ../ssl/checkpoints/checkpoint_trained_dense.pth.tar --quantize-eval --evaluate
A linha de comando acima salvará um ponto de verificação chamado quantized_checkpoint.pth.tar contendo os parâmetros quantizados do modelo. Veja mais exemplos aqui.
O conjunto de notebooks que vêm com o destilador é descrito aqui, o que também explica as etapas para instalar o servidor Jupyter Notebook.
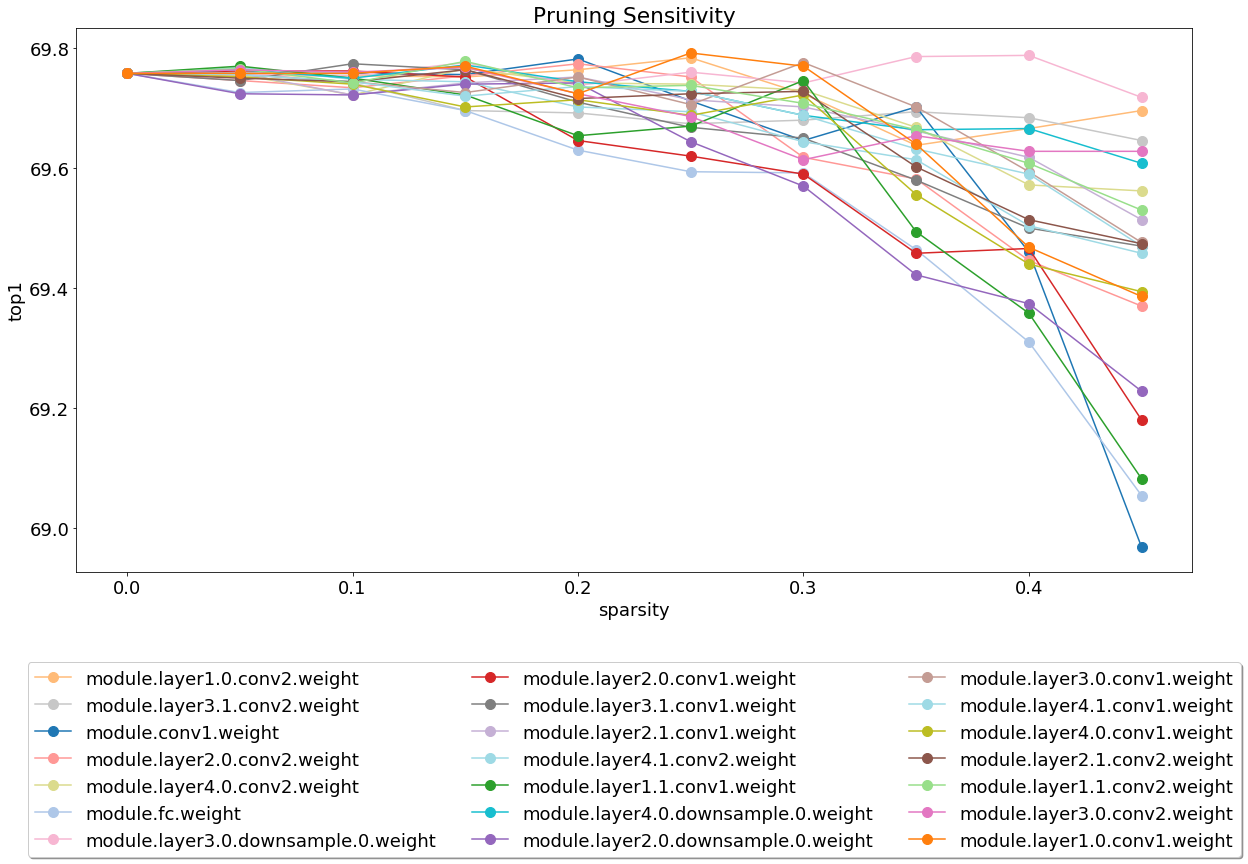
Depois de instalar e executar o servidor, dê uma olhada no notebook que cobre a análise de sensibilidade da poda.
A análise de sensibilidade é um processo longo e este notebook carrega arquivos CSV que são a saída de várias sessões da análise de sensibilidade.
Atualmente, somos leves no teste e esta é uma área em que as contribuições serão muito apreciadas.
Existem dois tipos de testes: testes do sistema e testes de unidade. Para invocar os testes de unidade:
$ cd distiller/tests
$ pytest
Usamos o CIFAR10 para os testes do sistema, porque seu tamanho contribui para testes mais rápidos. Para invocar os testes do sistema, você precisa fornecer um caminho para o conjunto de dados CIFAR10 que você já baixou. Como alternativa, você pode invocar full_flow_tests.py sem especificar a localização do conjunto de dados CIFAR10 e deixar o teste baixar o conjunto de dados (apenas para a primeira invocação). Observe que --cifar1o-path Padrões no diretório atual.
Os testes do sistema não são curtos e são ainda mais longos se o teste precisar baixar o conjunto de dados.
$ cd distiller/tests
$ python full_flow_tests.py --cifar10-path=<some_path>
O script sai com o status 0 se todos os testes forem bem -sucedidos ou o status 1 de outra forma.
Instale os MKDOCs e os pacotes necessários executando:
$ pip3 install -r doc-requirements.txt
Para construir a documentação do projeto:
$ cd distiller/docs-src
$ mkdocs build --clean
Isso criará uma pasta chamada 'site' que contém o site de documentação. Open Distiller/Docs/Site/Index.html para visualizar a página inicial da documentação.
Usamos o Semver para versões. Para as versões disponíveis, consulte as tags neste repositório.
Este projeto está licenciado sob a licença Apache 2.0 - consulte o arquivo License.md para obter detalhes
Modelos podados degirum - um repositório contendo modelos podados e informações relacionadas.
Torchfi - Torchfi é uma estrutura de injeção de falha construída sobre o Pytorch para fins de pesquisa.
HSI -Toolbox - Compressão da CNN hiperespectral e seleção de banda
Brunno F. Goldstein, Sudarshan Srinivasan, Dipankar Das, Kunal Banerjee, Leandro Santiago, Victor C. Ferreira, Alexandre S. Nery, Sandip Kundu, Felipe Mg Franca.
Avaliação de confiabilidade de modelos de aprendizado profundo comprimido ,
No 11º Simpósio Latino-Americano do IEEE sobre Circuitos e Sistemas (LASCAS), San Jose, Costa Rica, 2020, pp. 1-5.
Pascal Baco, Robert Stewart, Ekaterina Komendantskaya.
Precisão, tempo de treinamento e troca de eficiência de hardware para redes neurais quantizadas em FPGAs ,
Na computação reconfigurável aplicada. Arquiteturas, ferramentas e aplicações. ARC 2020. Notas de aula em Ciência da Computação, Vol.
Indranil Chakraborty, Mustafa Fayez Ali, Dong Eun Kim, Aayush Ankit, Kaushik Roy.
Geniex: Uma abordagem generalizada para imitar a não idealidade em XBARs memristivos usando redes neurais ,
ARXIV: 2003.06902, 2020.
Ahmed T. Elthakeb, Prannoy Pilligundla, Fatemehsadat Mireshghallah, Tarek Elgindi, Charles-Alban Deledalle, Hadi Esmaeilzadeh.
Quantização profunda baseada em gradiente de redes neurais através da regularização adaptativa sinusoidal ,
ARXIV: 2003.00146, 2020.
Ziqing Yang, Yiming Cui, Zhipeng Chen, Wanxiang Che, Ting Liu, Shijin Wang, Guoping Hu.
TEXTBREWER: Um kit de ferramentas de destilação de conhecimento de código aberto para processamento de linguagem natural ,
ARXIV: 2002.12620, 2020.
Alexander Kozlov, Ivan Lazarevich, Vasily Shamporov, Nikolay Lyalyushkin, Yury Gorbachev.
Estrutura de compactação de rede neural para inferência de modelo rápido ,
ARXIV: 2002.08679, 2020.
Moran Shkolnik, Brian Chmiel, Ron Banner, Gil Shomron, Yuri Nahshan, Alex Bronstein, Uri Weiser.
Quantização robusta: um modelo para governar todos eles ,
ARXIV: 2002.07686, 2020.
Muhammad Abdullah Hanif, Muhammad Shafique.
SalvagedNN: Recunda os aceleradores de rede neural profunda com falhas permanentes por meio do mapeamento com consciência de falhas orientadas por saliência ,
Nas transações filosóficas da Royal Society A: Matemática, Física e Engenharia SciencesVolume 378, Edição 2164, 2019.
https://doi.org/10.1098/rsta.2019.0164
Meiqi Wang, Jianqiao MO, Jun Lin, Zhongfeng Wang, Li Du.
Dynexit: uma estratégia dinâmica de expedição para redes residuais profundas ,
No IEEE International Workshop sobre Signal Processing Systems (SIPS), 2019.
Vinu Joseph, Saurav Muralidharan, Animesh Garg, Michael Garland, Ganesh Gopalakrishnan.
Uma abordagem programável para modelar a compactação,
ARXIV: 1911.02497, 2019
código
Hui Guan, Lin Ning, Zhen Lin, Xipeng Shen, Huiyang Zhou, Seung-Hwan Lim.
Proteção de memória de espaço zero no local para CNN ,
Em conferência sobre sistemas de processamento de informações neurais (Neurips), 2019.
ARXIV: 1910.14479, 2019
código
Hossein Baktash, Emanuele Natale, Laurent Viennot.
Um estudo comparativo da compressão da rede neural ,
ARXIV: 1910.11144, 2019.
Maxim Zemlyanikin, Alexander Smorkalov, Tatiana Khanova, Anna Petrovicheva, Grigory Serebryakov.
512kib RAM é suficiente! Reconhecimento de rosto de câmera ao vivo DNN no MCU ,
Na Conferência Internacional do IEEE (ICCV), 2019.
Ziheng Wang, Jeremy Wohlwend, Tao Lei.
Poda estruturada de grandes modelos de linguagem ,
ARXIV: 1910.04732, 2019.
Soroush Ghodrati, Hardik Sharma, Sean Kinzer, Amir Yazdanbakhsh, Kambiz Samadi, Nam Sung Kim, Doug Burger, Hadi Esmaeilzadeh.
Aceleração do domínio de carga do sinal misto de redes neurais profundas por meio de aritmética intercalada de bits-bits ,
ARXIV: 1906.11915, 2019.
Gil Shomron, Tal Horowitz, Uri Weiser.
SMT-SA: multithreading simultâneo em matrizes sistólicas ,
Em IEEE Computer Architecture Letters (Cal), 2019.
Shangqian Gao, Cheng Deng e Heng Huang.
Compressão do modelo de domínio cruzado por compartilhamento estruturalmente de peso,
Na conferência IEEE sobre visão computacional e reconhecimento de padrões (CVPR), 2019, pp. 8973-8982.
Moin Nadeem, Wei Fang, Brian Xu, Mitra Mohtarami, James Glass.
Fakta: um sistema de verificação de fatos de ponta a ponta automática,
No capítulo norte -americano da Associação de Linguística Computacional (NAACL), 2019.
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh.
Sinreq: regularização sinusoidal generalizada para treinamento quantizado profundo de baixa largura de bits,
ARXIV: 1905.01416, 2019. Código
Gincharenko A., Denisov A., Alyamkin S., Terentev E.
Limiares treináveis para quantização da rede neural,
In: Rojas I., Joya G., Catala A. (eds) Avanços em Notas da Palestra de Inteligência Computacional em Ciência da Computação, Vol 11507. Springer, Cham. Conferência internacional de trabalho em redes neurais artificiais (Iwann 2019).
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh.
Divida e conquista: alavancando representações de recursos intermediários para treinamento quantizado de redes neurais,
ARXIV: 1906.06033, 2019
Ritchie Zhao, Yuwei Hu, Jordan Dotzel, Christopher de SA, Zhiru Zhang.
Melhorando a quantização da rede neural sem reciclagem usando a divisão de canais externos,
ARXIV: 1901.09504, 2019
Código
Angad S. Rekhi, Brian Zimmer, Nikola Nedovic, Ningxi Liu, Rangharajan Venkatesan, Miaorong Wang, Brucek Khailany, William J. Dally, C. Thomas Gray.
Modelagem de erros de hardware analógica/signo misto para inferência de aprendizado profundo ,
Nvidia Research, 2019.
Norio Nakata.
Desenvolvimento técnico recente da inteligência artificial para diagnóstico de imagens médicas ,
No Japanese Journal of Radiology, fevereiro de 2019, volume 37, edição 2, pp 103-108.
Alexander Goncharenko, Andrey Denisov, Sergey Alyamkin, Evgeny Terentev.
Limiar ajustável rápido para quantização uniforme de rede neural ,
ARXIV: 1812.07872, 2018
Se você usou o destilador para o seu trabalho, use a seguinte citação:
@article{nzmora2019distiller,
author = {Neta Zmora and
Guy Jacob and
Lev Zlotnik and
Bar Elharar and
Gal Novik},
title = {Neural Network Distiller: A Python Package For DNN Compression Research},
month = {October},
year = {2019},
url = {https://arxiv.org/abs/1910.12232}
}
Qualquer trabalho publicado é construído sobre o trabalho de muitas outras pessoas, e o crédito pertence a muitas pessoas para listar aqui.
O destilador é liberado como um código de referência para fins de pesquisa. Não é um produto oficial da Intel, e o nível de qualidade e suporte pode não ser o esperado de um produto oficial. Algoritmos e recursos adicionais estão planejados para serem adicionados à biblioteca. O feedback e as contribuições das comunidades de código aberto e pesquisa são mais do que bem -vindas.


