distiller
1.0.0
켈 프로젝트 중단 - 이 프로젝트는 더 이상 인텔에 의해 유지되지 않습니다. 이 프로젝트는 보안 탈출을 알고있는 것으로 확인되었습니다. 인텔은이 프로젝트에 대한 유지 보수, 버그 수정, 새로운 릴리스 또는 업데이트를 포함하여 개발 및 기여를 중단했습니다. 인텔은 더 이상이 프로젝트에 패치를 받아들이지 않습니다.

Distiller는 신경망 압축 연구를위한 오픈 소스 파이썬 패키지입니다.
네트워크 압축은 신경망의 메모리 발자국을 줄이고 추론 속도를 높이고 에너지를 절약 할 수 있습니다. Distiller는 Sparsity-inducing 방법 및 저렴한 산술과 같은 압축 알고리즘 프로토 타이핑 및 분석을위한 Pytorch 환경을 제공합니다.
이 지침은 로컬 컴퓨터에서 증류기를 설치하고 실행하는 데 도움이됩니다.
Github에서 증류기 코드 저장소를 복제하십시오.
$ git clone https://github.com/IntelLabs/distiller.git
다음 문서의 나머지 부분은 리포지토리를 distiller 라는 디렉토리로 복제했다고 가정합니다.
파이썬 가상 환경을 사용하는 것이 좋습니다. 그러나 물론 그렇습니다. 가상 환경에서 증류기를 사용하는 데 특별한 것은 없지만 완전성을 위해 몇 가지 지침을 제공합니다.
가상 환경을 만들기 전에 디렉토리 distiller 에 있는지 확인하십시오. 환경을 조성한 후에는 distiller/env 라는 디렉토리가 표시됩니다.
VirtualEnV가 설치되어 있지 않은 경우 여기에서 설치 지침을 찾을 수 있습니다.
환경을 만들려면 실행 :
$ python3 -m virtualenv env
이렇게하면 파이썬 가상 환경이 저장되는 env 라는 서브 디렉토리를 생성하고 현재 쉘을 기본 파이썬 환경으로 사용하도록 구성합니다.
venv 사용하는 것을 선호하는 경우 설치로 시작하십시오.
$ sudo apt-get install python3-venv
그런 다음 환경을 만듭니다.
$ python3 -m venv env
VirtualEnv와 마찬가지로 이것은 distiller/env 라는 디렉토리를 만듭니다.
venv 및 virtualenv 의 환경 활성화 및 비활성화 명령은 동일합니다.
! 참고 : 종속성 패키지를 설치하기 전에 환경을 활성화하십시오.
$ source env/bin/activate
마지막으로 pip3 사용하여 증류기 패키지 및 해당 종속성을 설치하십시오.
$ cd distiller
$ pip3 install -e .
이로 인해 "개발 모드"에 증류기가 설치됩니다. 즉, 코드의 변경 사항은 설치 명령을 다시 실행하지 않고 환경에 반영됩니다 (따라서 GIT 저장소에서 변경을당한 후 다시 설치할 필요가 없습니다).
참고 :
Distiller는 CUDA 10.1을 사용하는 Pytorch 1.3.1의 기본 설치를 사용하여 테스트됩니다. 우리는 Torchvision 버전 0.4.2를 사용합니다. 이들은 Distiller의 requirements.txt 에 포함되어 있으며 위에 나열된 증류기 패키지를 설치할 때 자동으로 설치됩니다.
귀하의 환경에서 Cuda 10.1을 사용하지 않으면 Pytorch 웹 사이트를 참조하여 Pytorch 1.3.1 및 Torchvision 0.4.2의 호환 빌드를 설치하십시오.
Distiller는 다양한 모델 유형을 다루는 샘플 응용 프로그램 및 튜토리얼과 함께 제공됩니다.
| 모델 유형 | 희소성 | 훈련 후 양자화 | 양자 인식 훈련 | 자동 압축 (AMC) | 지식 증류 |
|---|---|---|---|---|---|
| 이미지 분류 | ✅ | ✅ | ✅ | ✅ | ✅ |
| 단어 수준 언어 모델 | ✅ | ✅ | |||
| 번역 (GNMT) | ✅ | ||||
| 추천 시스템 (NCF) | ✅ | ||||
| 물체 감지 | ✅ |
자세한 내용은 예제 디렉토리로 이동하십시오.
예제를 넘어서 언급 할 기타 리소스 :
다음은 증류기의 이미지 분류 샘플을 사용한 간단한 예입니다.
다음은 CIFAR10 데이터 세트에서 'Simplenet'이라는 네트워크의 교육 전용 (압축 없음)을 호출합니다. 이것은 대략 Torchvision의 샘플 Imagenet Training 응용 프로그램을 기반으로하므로 해당 응용 프로그램을 사용한 경우 익숙해 보일 것입니다. 이 예에서 우리는 압축 메커니즘을 호출하지 않습니다. 우리는 가지 치기 후 미세 조정하기 위해 훈련이 필수적인 부분이기 때문에 훈련합니다.
이 명령을 처음 실행하면 CIFAR10 코드가 컴퓨터로 다운로드되며 시간이 걸릴 수 있습니다. 다운로드 프로세스가 완료되도록하십시오.
CIFAR10 데이터 세트의 경로는 임의적이지만, 예제에서는 데이터 세트를 디렉토리 레벨과 동일한 디렉토리 레벨에 배치합니다 (예 : ../../../data.cifar10 ).
먼저 샘플 디렉토리로 변경 한 다음 응용 프로그램을 호출합니다.
$ cd distiller/examples/classifier_compression
$ python3 compress_classifier.py --arch simplenet_cifar ../../../data.cifar10 -p 30 -j=1 --lr=0.01
Tensorboard 백엔드를 사용하여 교육 진행 상황을 볼 수 있습니다 (아래 다이어그램에서는 다른 LR 값을 가진 몇 가지 교육 세션이 표시됩니다). 압축 세션의 경우 활성화 및 파라미터 sparsity 수준의 추적 및 정규화 손실을 추가했습니다.
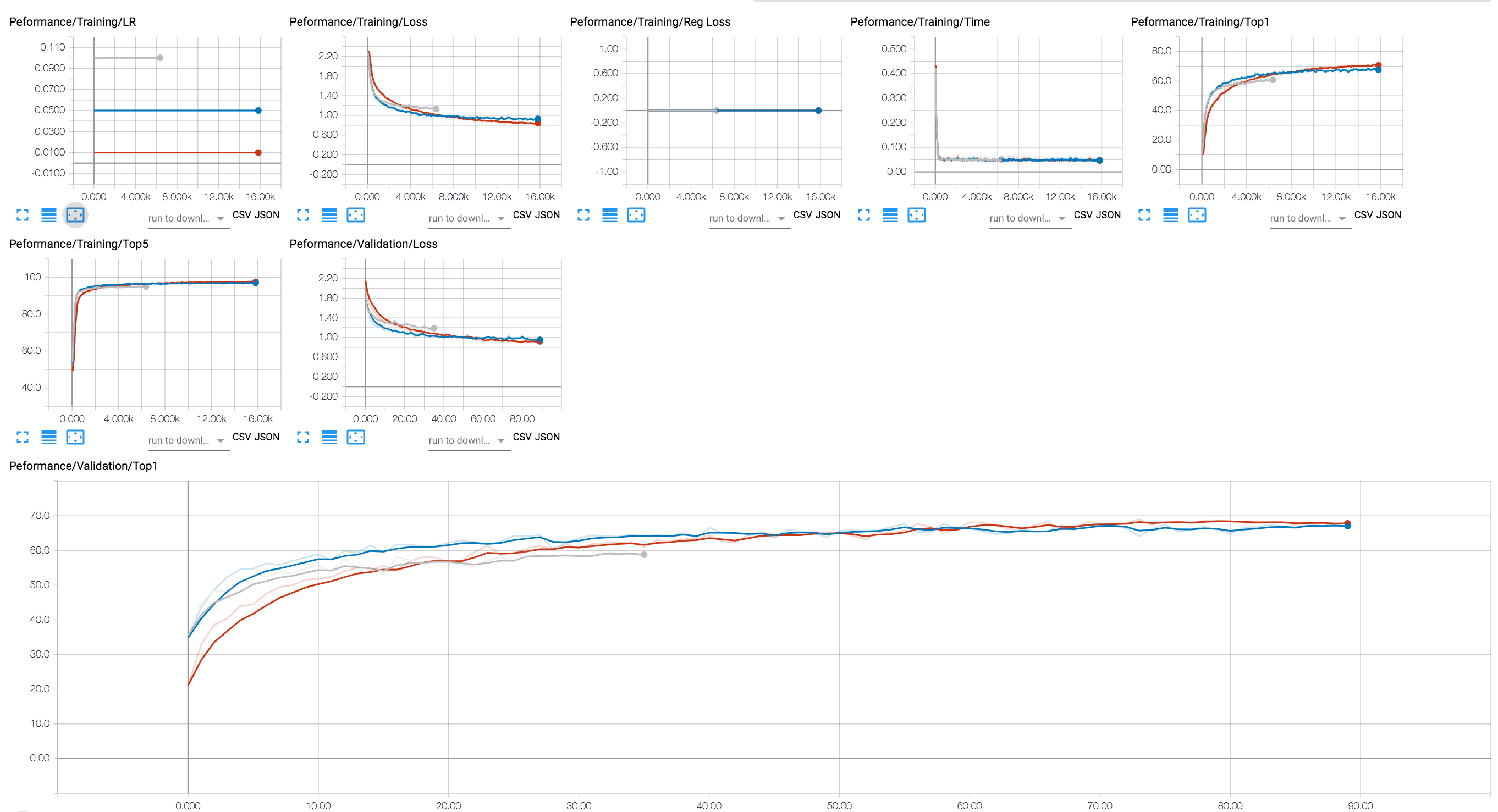
우리는 Git 저장소에 32 비트 플로트로 훈련 한 RESNET20 모델의 몇 가지 검문소를 포함 시켰습니다. 채널 별 그룹 Lasso 정규화로 훈련 한 모델의 체크 포인트를로드합시다.
다음 명령 줄 인수를 사용하면 샘플 응용 프로그램이 모델 ( --resume )을로드하고 모델 가중치 ( --summary=sparsity )에 대한 통계를 인쇄합니다. 이것은 예를 들어 가중치 스파트 통계를 검사하기 위해 이전에 가지 치기 모델을로드하려는 경우 유용합니다. 저장된 체크 포인트를 재개 할 때 여전히 체크 포인트가 사용하는 네트워크 아키텍처 ( -a=resnet20_cifar )를 알려야합니다.
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_ch_regularized_dense.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=sparsity
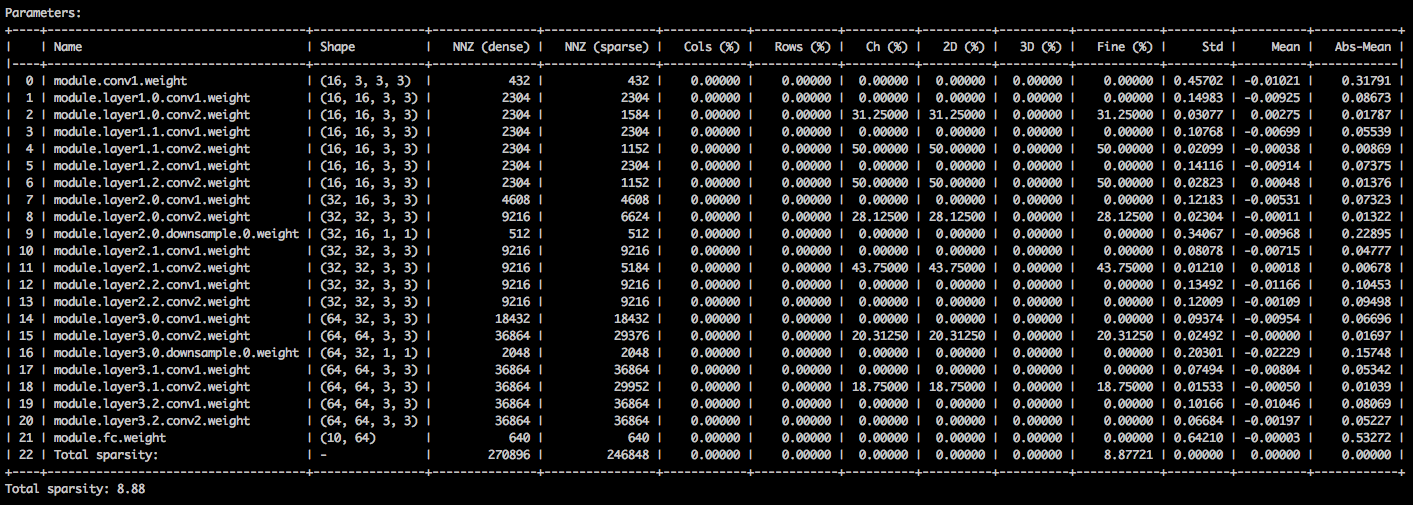
매개 변수 텐서의 다양한 희소성을 자세히 설명하는 텍스트 테이블이 표시됩니다. 첫 번째 열은 매개 변수 이름이며, 그 다음의 모양, 고밀도 모델에서 0이 아닌 요소 (NNZ) 및 스파 스 모델의 모양이 뒤 따릅니다. 다음 열의 세트는 열별, 행, 채널 별, 커널별, 필터 별 및 요소 별 희소성을 보여줍니다.
그것을 마무리하는 것은 요소의 표준 퇴직, 평균 및 평균 및 절대 값의 평균입니다.
압축 통찰력 노트에서 우리는 Matplotlib를 사용 하여이 요약의 막대 차트를 플로팅하여 실제로 인상적인 발자국 압축을 보여줍니다.
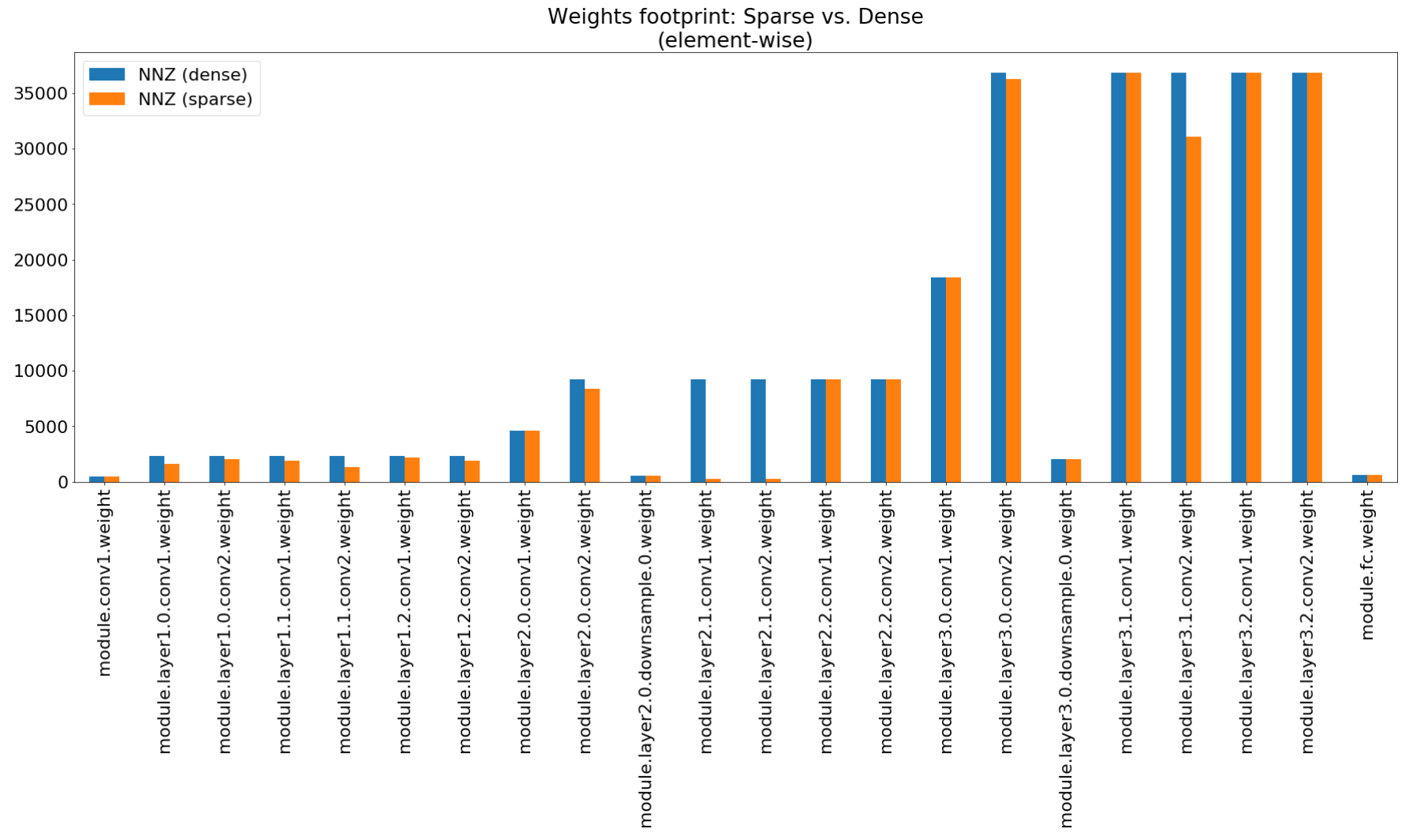
메모리 풋 프린트 압축은 매우 낮지만이 모델은 실제로 MACS 컴퓨팅의 26.6%를 절약합니다.
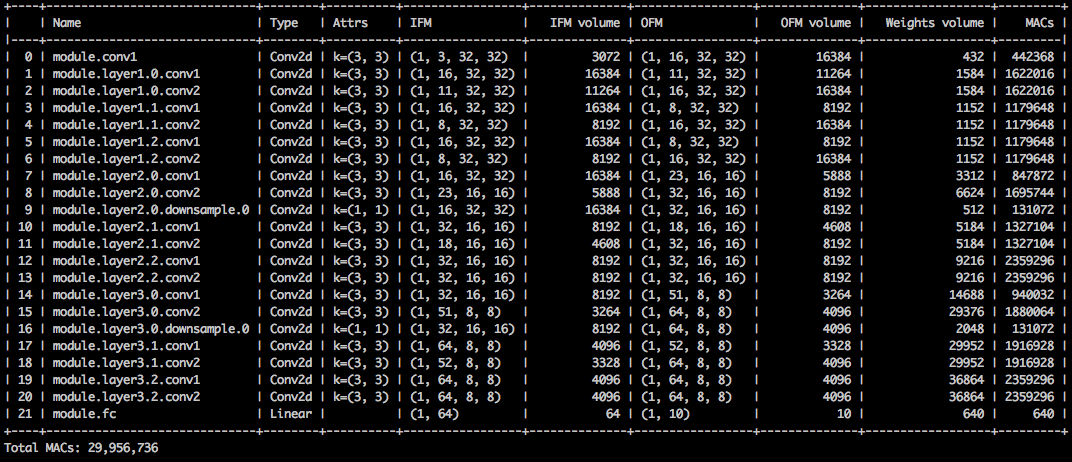
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_channel_regularized_resnet20_finetuned.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=compute
이 예제는 CIFAR10에 대해 RESNET20의 8 비트 양자화를 수행합니다. 우리는 Git 저장소에 32 비트 플로트로 교육을받은 RESNET20 모델의 체크 포인트를 포함 시켰 으므로이 모델을 가져 와서 정량화 할 것입니다.
$ python3 compress_classifier.py -a resnet20_cifar ../../../data.cifar10 --resume ../ssl/checkpoints/checkpoint_trained_dense.pth.tar --quantize-eval --evaluate
위의 명령 줄은 quantized_checkpoint.pth.tar 라는 Quantized_checkpoint.pth.tar라는 체크 포인트를 저장합니다. 여기에서 더 많은 예를보십시오.
증류기와 함께 제공되는 노트북 세트는 여기에 설명되어 있으며 Jupyter 노트북 서버를 설치하는 단계도 설명합니다.
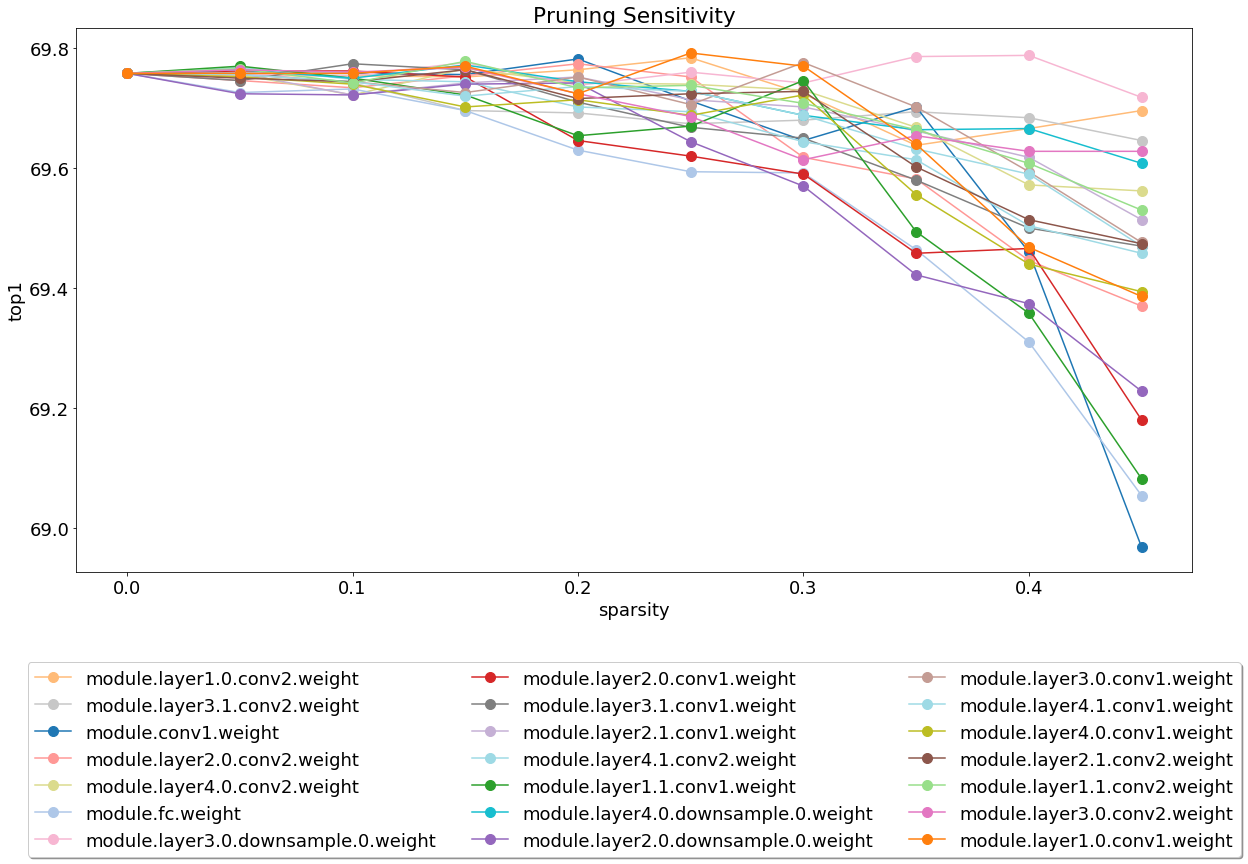
서버를 설치하고 실행 한 후에는 가지 치기 민감도 분석을 다루는 노트북을 살펴보십시오.
민감도 분석은 긴 프로세스 이며이 노트북은 민감도 분석의 여러 세션의 출력 인 CSV 파일을로드합니다.
우리는 현재 테스트에 대한 가벼운 중량이며 이것은 기부금이 크게 높이 평가되는 영역입니다.
테스트에는 시스템 테스트와 단위 테스트의 두 가지 유형이 있습니다. 단위 테스트를 호출하려면 :
$ cd distiller/tests
$ pytest
시스템 테스트에는 CIFAR10을 사용합니다. 크기는 더 빠른 테스트를 위해 만들기 때문입니다. 시스템 테스트를 호출하려면 이미 다운로드 한 CIFAR10 데이터 세트에 대한 경로를 제공해야합니다. 또는 CIFAR10 데이터 세트의 위치를 지정하지 않고 full_flow_tests.py 호출하고 테스트에 데이터 세트를 다운로드하도록하십시오 (첫 번째 호출 만). --cifar1o-path 현재 디렉토리로 기본값을 얻습니다.
시스템 테스트는 짧지 않으며 테스트가 데이터 세트를 다운로드 해야하는 경우 더 길다.
$ cd distiller/tests
$ python full_flow_tests.py --cifar10-path=<some_path>
스크립트는 모든 테스트가 성공한 경우 상태 0으로 종료되거나 그렇지 않으면 상태 1입니다.
실행하여 MKDOC 및 필요한 패키지를 설치하십시오.
$ pip3 install -r doc-requirements.txt
프로젝트 문서를 구축하려면 실행 :
$ cd distiller/docs-src
$ mkdocs build --clean
이렇게하면 문서 웹 사이트가 포함 된 '사이트'라는 폴더가 생성됩니다. Distiller/Docs/Site/Index.html을 열어 문서 홈페이지를보십시오.
우리는 버전 관리에 Semver를 사용합니다. 사용 가능한 버전은이 저장소의 태그를 참조하십시오.
이 프로젝트는 Apache License 2.0에 따라 라이센스가 부여됩니다. 자세한 내용은 License.md 파일을 참조하십시오.
Degirum 치기 모델 - 가지 치기 모델 및 관련 정보를 포함하는 저장소.
Torchfi -Torchfi는 연구 목적으로 Pytorch 위에있는 결함 주입 프레임 워크입니다.
HSI -TOOLBOX- 과자석 CNN 압축 및 밴드 선택
Brunno F. Goldstein, Sudarshan Srinivasan, Dipankar Das, Kunal Banerjee, Leandro Santiago, Victor C. Ferreira, Alexandre S. Nery, Sandip Kundu, Felipe Mg Franca.
압축 딥 러닝 모델의 신뢰성 평가 ,
IEEE 11 번째 라틴 아메리카 심포지엄 회로 및 시스템 (LASCAS), San Jose, Costa Rica, 2020, pp. 1-5.
Pascal Bacchus, Robert Stewart, Ekaterina Komendantskaya.
FPGA의 양자화 된 신경 네트워크에 대한 정확성, 교육 시간 및 하드웨어 효율성 트레이드 오프,
적용된 재구성 가능한 컴퓨팅. 아키텍처, 도구 및 응용 프로그램. ARC 2020. 컴퓨터 과학 강의 노트, Vol 12083. Springer, Cham
Indranil Chakraborty, Mustafa Fayez Ali, Dong Eun Kim, Aayush Ankit, Kaushik Roy.
GENIEX : 신경망을 사용하여 밈적 XBAR의 비 불질화를 모방하는 일반화 된 접근법 ,
ARXIV : 2003.06902, 2020.
Ahmed T. Elthakeb, Prannoy Pilligundla, Fatemehsadat Mireshghallah, Tarek Elgindi, Charles-Alban Deledalle, Hadi Esmaeilzadeh.
정현파 적응 정규화를 통한 신경망의 구배 기반 깊은 양자화 ,
Arxiv : 2003.00146, 2020.
Ziqing Yang, Yiming Cui, Zhipeng Chen, Wanxiang Che, Ting Liu, Shijin Wang, Guoping Hu.
TextBrewer : 자연어 처리를위한 오픈 소스 지식 증류 툴킷 ,
Arxiv : 2002.12620, 2020.
Alexander Kozlov, Ivan Lazarevich, Vasily Shamporov, Nikolay Lyalyushkin, Yury Gorbachev.
빠른 모델 추론을위한 신경망 압축 프레임 워크 ,
ARXIV : 2002.08679, 2020.
Moran Shkolnik, Brian Chmiel, Ron Banner, Gil Shomron, Yuri Nahshan, Alex Bronstein, Uri Weiser.
강력한 양자화 : 그들 모두를 지배하는 하나의 모델 ,
ARXIV : 2002.07686, 2020.
무하마드 압둘라 하니프, 무하마드 샤프.
Salvagednn : 성실한 결함 인식 매핑을 통해 영구적 인 결함을 가진 깊은 신경 네트워크 가속기 구제 ,
Royal Society A의 철학적 거래에서 : 수학적, 물리 및 공학 과학 Volume 378, Issue 2164, 2019.
https://doi.org/10.1098/rsta.2019.0164
Meiqi Wang, Jianqiao MO, Jun Lin, Zhongfeng Wang, Li du.
dynexit : 깊은 잔류 네트워크를위한 역동적 인 초기 전략 ,
SIPS (Signal Processing Systems)의 IEEE 국제 워크숍에서 2019 년.
Vinu Joseph, Saurav Muralidharan, Animesh Garg, Michael Garland, Ganesh Gopalakrishnan.
모델 압축에 대한 프로그래밍 가능한 접근 방식,
ARXIV : 1911.02497, 2019
암호
Hui Guan, Lin Ning, Zhen Lin, Xipeng Shen, Huiyang Zhou, Seung-wan Lim.
CNN을위한 내장 제로 공간 메모리 보호 ,
신경 정보 처리 시스템 (NEURIPS) 회의, 2019.
ARXIV : 1910.14479, 2019
암호
Hossein Baktash, Emanuele Natale, Laurent Viennot.
신경망 압축에 대한 비교 연구 ,
ARXIV : 1910.11144, 2019.
Maxim Zemlyanikin, Alexander Smorkalov, Tatiana Khanova, Anna Petrovicheva, Grigory Serebryakov.
512kib 램이 충분합니다! MCU의 라이브 카메라 얼굴 인식 DNN ,
2019 년 IEEE 국제 컴퓨터 비전 (ICCV)에서.
Ziheng Wang, Jeremy Wohlwend, Tao Lei.
큰 언어 모델의 구조화 된 가지 치기 ,
ARXIV : 1910.04732, 2019.
Soroush Ghodrati, Hardik Sharma, Sean Kinzer, Amir Yazdanbakhsh, Kambiz Samadi, Nam Sung Kim, Doug Burger, Hadi Esmaeilzadeh.
인터리브 비트 파티션 된 산술을 통한 심층 신경망의 혼합 신호 전하 도메인 가속 ,
ARXIV : 1906.11915, 2019.
Gil Shomron, Tal Horowitz, Uri Weiser.
SMT-SA : 수축기 어레이의 동시 멀티 스레딩 ,
IEEE 컴퓨터 아키텍처 편지 (CAL), 2019.
Shangqian Gao, Cheng Deng 및 Heng Huang.
구조적으로 무게 공유에 의한 교차 도메인 모델 압축,
컴퓨터 비전 및 패턴 인식에 관한 IEEE 회의 (CVPR), 2019, pp. 8973-8982.
Moin Nadeem, Wei Fang, Brian Xu, Mitra Mohtarami, James Glass.
Fakta : 자동 엔드 투 엔드 팩트 점검 시스템,
2019 년 NAACL (Computational Linguististics) 협회 (NAACL)의 북미 지부.
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh.
SINREQ : 낮은 비율 깊은 양자 훈련을위한 일반화 된 정현파 정규화,
ARXIV : 1905.01416, 2019. 코드
Goncharenko A., Denisov A., Alyamkin S., Terentev E.
신경망 양자화를위한 훈련 가능한 임계 값,
에서 : Rojas I., Joya G., Catala A. (eds) 컴퓨터 과학의 전산 정보 강의 노트, Vol 11507. Springer, Cham. 인공 신경망에 대한 국제 업무 회의 (IWANN 2019).
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh.
나누기 및 정복 : 신경망의 양자화 된 훈련을위한 중간 특징 표현을 활용,
ARXIV : 1906.06033, 2019
Ritchie Zhao, Yuwei Hu, Jordan Dotzel, Christopher de SA, Zhiru Zhang.
특이 적 채널 분할을 사용하여 재교육하지 않고 신경망 양자화 개선,
ARXIV : 1901.09504, 2019
암호
Angad S. Rekhi, Brian Zimmer, Nikola Nedovic, Ningxi Liu, Rangharajan Venkatesan, Miaorong Wang, Brucek Khailany, William J. Dally, C. Thomas Grey.
딥 러닝 추론을위한 아날로그/혼합 신호 하드웨어 오류 모델링 ,
Nvidia Research, 2019.
Norio Nakata.
진단 의료 영상을위한 인공 지능의 최근 기술 개발 ,
일본의 방사선학 저널, 2019 년 2 월, 37 권, 문제 2, pp 103–108.
Alexander Goncharenko, Andrey Denisov, Sergey Alyamkin, Evgeny Terentev.
균일 한 신경망 양자화를위한 빠른 조정 가능한 임계 값 ,
ARXIV : 1812.07872, 2018
작업에 증류기를 사용한 경우 다음 인용을 사용하십시오.
@article{nzmora2019distiller,
author = {Neta Zmora and
Guy Jacob and
Lev Zlotnik and
Bar Elharar and
Gal Novik},
title = {Neural Network Distiller: A Python Package For DNN Compression Research},
month = {October},
year = {2019},
url = {https://arxiv.org/abs/1910.12232}
}
출판 된 작품은 다른 많은 사람들의 작품 위에 구축되며, 크레딧은 여기에 너무 많은 사람들에게 속합니다.
증류기는 연구 목적으로 참조 코드로 출시됩니다. 공식 인텔 제품이 아니며 공식 제품에서 예상되는 품질과 지원 수준이 예상되지 않을 수 있습니다. 추가 알고리즘 및 기능은 라이브러리에 추가 될 계획입니다. 오픈 소스 및 연구 커뮤니티의 피드백과 기여는 환영받는 것 이상입니다.


