distiller
1.0.0
️ Descontinuación del proyecto : este proyecto ya no será mantenido por Intel. Se ha identificado que este proyecto tiene escapes de seguridad conocidos. Intel ha dejado de desarrollo y contribuciones que incluyen, entre otros, mantenimiento, correcciones de errores, nuevas versiones o actualizaciones, a este proyecto. Intel ya no acepta parches a este proyecto.

Distiller es un paquete Python de código abierto para la investigación de compresión de redes neuronales.
La compresión de la red puede reducir la huella de memoria de una red neuronal, aumentar su velocidad de inferencia y ahorrar energía. Distiller proporciona un entorno de Pytorch para crear prototipos y analizar algoritmos de compresión, como métodos inductores de escasez y aritmética de baja precisión.
Estas instrucciones ayudarán a que el destilador esté en funcionamiento en su máquina local.
Clone El repositorio de código de destilador de GitHub:
$ git clone https://github.com/IntelLabs/distiller.git
El resto de la documentación que sigue, supone que ha clonado su repositorio a un directorio llamado distiller .
Recomendamos usar un entorno virtual de Python, pero eso, por supuesto, depende de usted. No hay nada especial en el uso de Distiller en un entorno virtual, pero proporcionamos algunas instrucciones, para completar.
Antes de crear el entorno virtual, asegúrese de estar ubicado en distiller de directorio. Después de crear el entorno, debe ver un directorio llamado distiller/env .
Si no tiene VirtualEnv instalado, puede encontrar las instrucciones de instalación aquí.
Para crear el entorno, ejecute:
$ python3 -m virtualenv env
Esto crea un subdirectorio llamado env donde se almacena el entorno virtual de Python y configura el shell actual para usarlo como el entorno Python predeterminado.
Si prefiere usar venv , comience por instalarlo:
$ sudo apt-get install python3-venv
Luego crea el entorno:
$ python3 -m venv env
Al igual que con VirtualEnv, esto crea un directorio llamado distiller/env .
Los comandos de activación y desactivación del medio ambiente para venv y virtualenv son los mismos.
! Nota: asegúrese de activar el entorno, antes de continuar con la instalación de los paquetes de dependencia:
$ source env/bin/activate
Finalmente, instale el paquete Distiller y sus dependencias usando pip3 :
$ cd distiller
$ pip3 install -e .
Esto instala el destilador en "modo de desarrollo", lo que significa que cualquier cambio realizado en el código se refleja en el entorno sin volver a ejecutar el comando de instalación (por lo que no es necesario volver a instalar después de extraer cambios del repositorio de Git).
Notas:
El destilador se prueba utilizando la instalación predeterminada de Pytorch 1.3.1, que usa CUDA 10.1. Utilizamos TorchVision versión 0.4.2. Estos se incluyen en requirements.txt de Distiller.txt y se instalarán automáticamente al instalar el paquete Distiller como se menciona anteriormente.
Si no usa CUDA 10.1 en su entorno, consulte el sitio web de Pytorch para instalar la compatibilidad compatible de Pytorch 1.3.1 y TorchVision 0.4.2.
Distiller viene con aplicaciones de muestra y tutoriales que cubren una gama de tipos de modelos:
| Tipo de modelo | Escasez | Cuantificación posterior al entrenamiento | Capacitación consciente de cuantización | Compresión automática (AMC) | Destilación de conocimiento |
|---|---|---|---|---|---|
| Clasificación de imágenes | ✅ | ✅ | ✅ | ✅ | ✅ |
| Modelo de idioma a nivel de palabras | ✅ | ✅ | |||
| Traducción (GNMT) | ✅ | ||||
| Sistema de recomendación (NCF) | ✅ | ||||
| Detección de objetos | ✅ |
Dirígete al directorio de ejemplos para obtener más detalles.
Otros recursos para referirse, más allá de los ejemplos:
Los siguientes son ejemplos simples que utilizan la muestra de clasificación de imagen de Distiller, que muestran algunas de las capacidades del destilador.
Lo siguiente invocará solo capacitación (sin compresión) de una red llamada 'Simplenet' en el conjunto de datos CIFAR10. Esto se basa aproximadamente en la aplicación de entrenamiento de Imagenet de muestra de TorchVision, por lo que debería parecer familiar si ha usado esa aplicación. En este ejemplo, no invocamos ningún mecanismo de compresión: solo entrenamos porque para el ajuste después de la poda, el entrenamiento es una parte esencial.
Tenga en cuenta que la primera vez que ejecuta este comando, el código CIFAR10 se descargará a su máquina, que puede llevar un poco de tiempo; deje que el proceso de descarga proceda a completar.
La ruta al conjunto de datos CIFAR10 es arbitraria, pero en nuestros ejemplos colocamos los conjuntos de datos en el mismo nivel de directorio que Distiller (es decir, ../../../data.cifar10 data.cifar10).
Primero, cambie al directorio de muestra, luego invoque la aplicación:
$ cd distiller/examples/classifier_compression
$ python3 compress_classifier.py --arch simplenet_cifar ../../../data.cifar10 -p 30 -j=1 --lr=0.01
Puede usar un backend de Tensorboard para ver el progreso de la capacitación (en el diagrama a continuación mostramos un par de sesiones de entrenamiento con diferentes valores LR). Para las sesiones de compresión, hemos agregado el rastreo de los niveles de activación y escasez de parámetros, y pérdida de regularización.
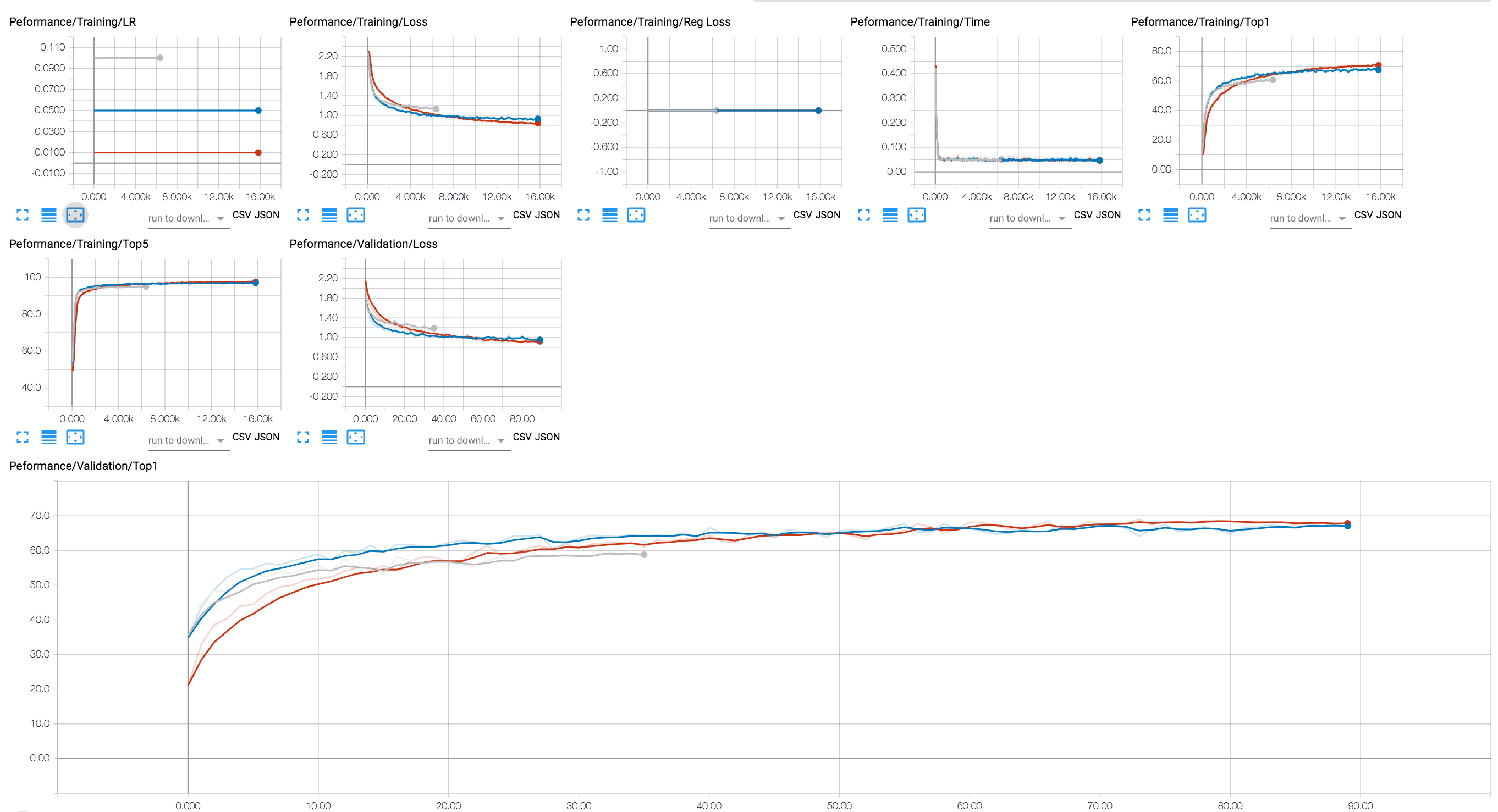
Hemos incluido en el repositorio de Git algunos puntos de control de un modelo ResNet20 que hemos entrenado con flotadores de 32 bits. Cargamos el punto de control de un modelo que hemos entrenado con la regularización de lazos de grupo de canal.
Con los siguientes argumentos de línea de comandos, la aplicación de muestra carga el modelo ( --resume ) e imprime estadísticas sobre los pesos del modelo ( --summary=sparsity ). Esto es útil si desea cargar un modelo previamente podado, para examinar las estadísticas de escasez de pesos, por ejemplo. Tenga en cuenta que cuando reanude un punto de control almacenado, aún debe decirle a la aplicación qué arquitectura de red utiliza el punto de control ( -a=resnet20_cifar ):
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_ch_regularized_dense.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=sparsity
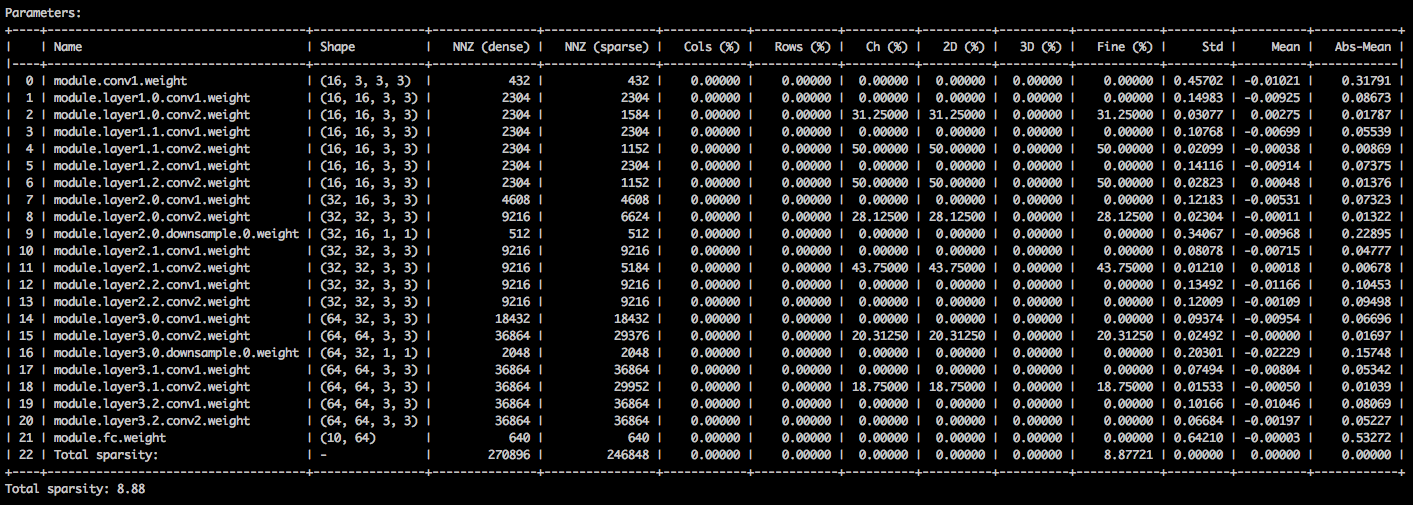
Debería ver una tabla de texto que detalla las diversas escasez de los tensores de parámetros. La primera columna es el nombre del parámetro, seguido de su forma, el número de elementos distintos de cero (NNZ) en el modelo denso y en el modelo disperso. El siguiente conjunto de columnas muestra las dispersión en cuanto a columna, en cuanto a la fila, en cuanto al canal, en cuanto al núcleo, en cuanto a filtraciones y a los elementos.
Envolviéndolo son la deviación estándar, la media y la media de los valores absolutos de los elementos.
En el cuaderno de Insights de compresión usamos matplotlib para trazar un gráfico de barras de este resumen, que de hecho muestran compresión de huella no impresionante.
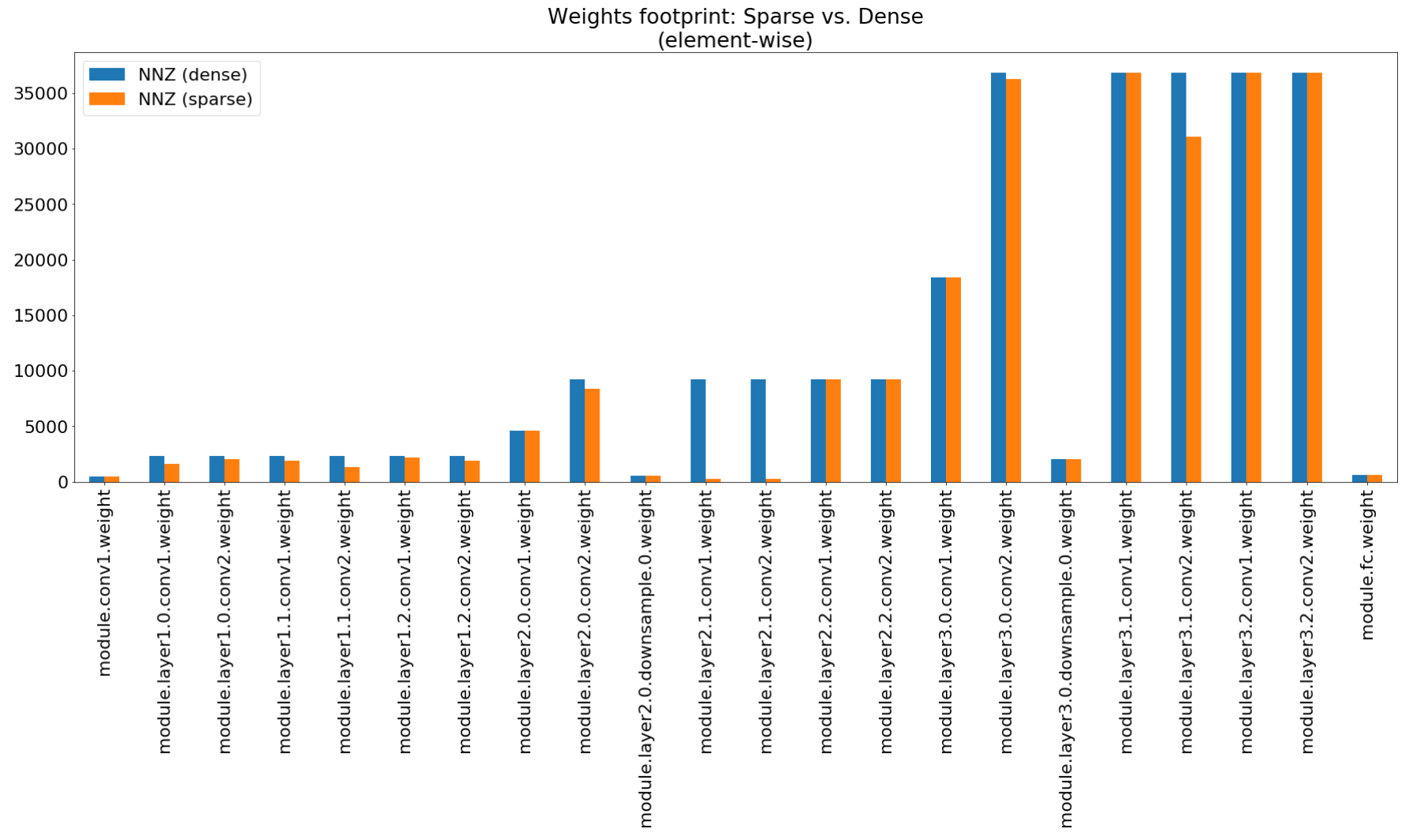
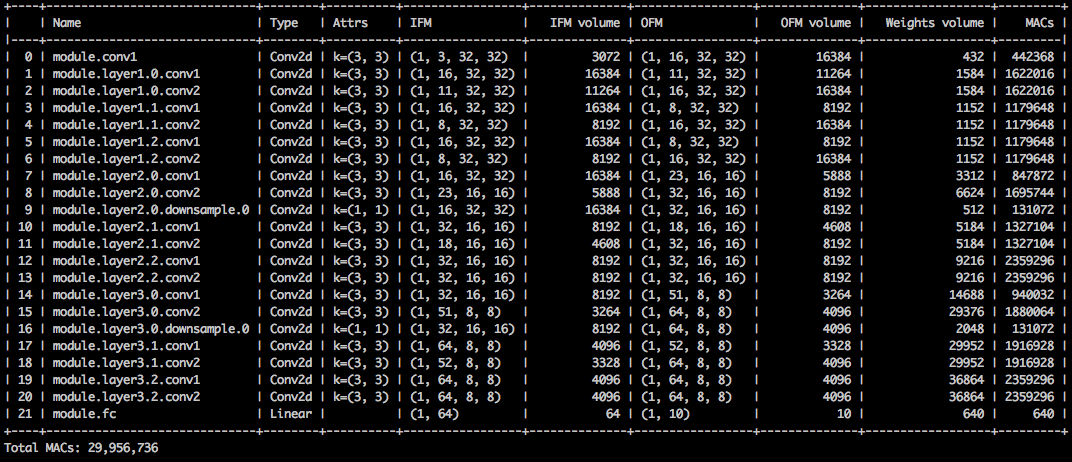
Aunque la compresión de la huella de memoria es muy baja, este modelo realmente ahorra el 26.6% del cómputo MACS.
$ python3 compress_classifier.py --resume=../ssl/checkpoints/checkpoint_trained_channel_regularized_resnet20_finetuned.pth.tar -a=resnet20_cifar ../../../data.cifar10 --summary=compute
Este ejemplo realiza una cuantización de 8 bits de ResNet20 para CIFAR10. Hemos incluido en el repositorio de Git el punto de control de un modelo ResNet20 que hemos entrenado con flotadores de 32 bits, por lo que tomaremos este modelo y lo cuantificaremos:
$ python3 compress_classifier.py -a resnet20_cifar ../../../data.cifar10 --resume ../ssl/checkpoints/checkpoint_trained_dense.pth.tar --quantize-eval --evaluate
La línea de comando anterior guardará un punto de control llamado quantized_checkpoint.pth.tar que contiene los parámetros del modelo cuantificados. Vea más ejemplos aquí.
El conjunto de cuadernos que vienen con Distiller se describe aquí, lo que también explica los pasos para instalar el servidor de cuaderno Jupyter.
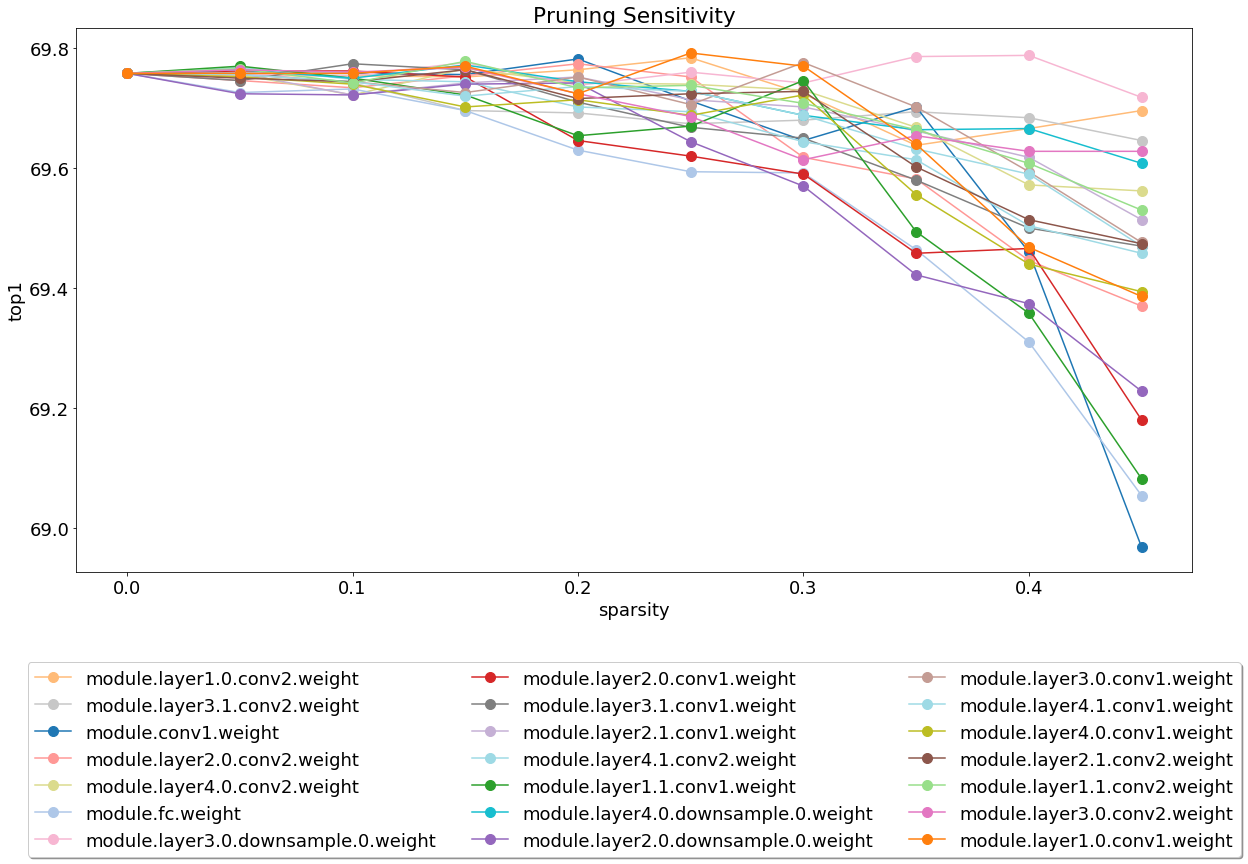
Después de instalar y ejecutar el servidor, eche un vistazo al análisis de sensibilidad de la poda que cubre el cuaderno.
El análisis de sensibilidad es un proceso largo y este cuaderno carga archivos CSV que son la salida de varias sesiones de análisis de sensibilidad.
Actualmente tenemos un peso ligero en la prueba y esta es un área donde las contribuciones serán muy apreciadas.
Hay dos tipos de pruebas: pruebas de sistema y pruebas unitarias. Para invocar las pruebas unitarias:
$ cd distiller/tests
$ pytest
Usamos CIFAR10 para las pruebas del sistema, porque su tamaño hace que las pruebas más rápidas. Para invocar las pruebas del sistema, debe proporcionar una ruta al conjunto de datos CIFAR10 que ya ha descargado. Alternativamente, puede invocar full_flow_tests.py sin especificar la ubicación del conjunto de datos CIFAR10 y dejar que la prueba descargue el conjunto de datos (solo para la primera invocación). Tenga en cuenta que --cifar1o-path predeterminado al directorio actual.
Las pruebas del sistema no son cortas y son aún más largas si la prueba necesita descargar el conjunto de datos.
$ cd distiller/tests
$ python full_flow_tests.py --cifar10-path=<some_path>
El script sale con el estado 0 si todas las pruebas tienen éxito, o el estado 1 de lo contrario.
Instale MKDOC y los paquetes requeridos ejecutando:
$ pip3 install -r doc-requirements.txt
Para crear la ejecución de la documentación del proyecto:
$ cd distiller/docs-src
$ mkdocs build --clean
Esto creará una carpeta llamada 'Sitio' que contiene el sitio web de documentación. Abra Distiller/Docs/Site/Index.html para ver la página de inicio de la documentación.
Usamos Semver para versiones. Para las versiones disponibles, consulte las etiquetas en este repositorio.
Este proyecto tiene licencia bajo la licencia APACHE 2.0 - consulte el archivo License.md para más detalles
Modelos podados de Degirum: un repositorio que contiene modelos podados e información relacionada.
Torchfi - Torchfi es un marco de inyección de fallas construido sobre Pytorch para fines de investigación.
HSI -Toolbox - compresión hiperespectral CNN y selección de banda
Brunno F. Goldstein, Sudarshan Srinivasan, Dipankar Das, Kunal Banerjee, Leandro Santiago, Victor C. Ferreira, Alexandre S. Nery, Sandip Kundu, Felipe Mg Franca.
Evaluación de confiabilidad de modelos comprimidos de aprendizaje profundo ,
En IEEE 11th Latin American Symposium on Circuits & Systems (Lasascas), San José, Costa Rica, 2020, pp. 1-5.
Pascal Bacchus, Robert Stewart, Ekaterina Komendantskaya.
Precisión, tiempo de entrenamiento y compensaciones de eficiencia de hardware para redes neuronales cuantificadas en FPGA ,
En computación reconfigurable aplicada. Arquitecturas, herramientas y aplicaciones. ARC 2020. Notas de conferencia en informática, Vol 12083. Springer, Cham
Indranil Chakraborty, Mustafa Fayez Ali, Dong Eun Kim, Aayush Ankit, Kaushik Roy.
Geniex: un enfoque generalizado para emular la no idealidad en Xbars Memristive utilizando redes neuronales ,
ARXIV: 2003.06902, 2020.
Ahmed T. Elthakeb, Prannoy Pilligundla, Fatemehsadat Mireshghallah, Tarek Elgindi, Charles-Alban Deledalle, Hadi Esmaeilzadeh.
Cuantización profunda basada en gradiente de redes neuronales a través de la regularización adaptativa sinusoidal ,
ARXIV: 2003.00146, 2020.
Ziqing Yang, Yiming Cui, Zhipeng Chen, Wanxiang Che, Ting Liu, Shijin Wang, Guoping Hu.
TextBrewer: un conjunto de herramientas de destilación de conocimiento de código abierto para el procesamiento del lenguaje natural ,
ARXIV: 2002.12620, 2020.
Alexander Kozlov, Ivan Lazarevich, Vasily Shamporov, Nikolay Lyalyushkin, Yury Gorbachev.
Marco de compresión de redes neuronales para la inferencia rápida del modelo ,
ARXIV: 2002.08679, 2020.
Moran Shkolnik, Brian Chmiel, Ron Banner, Gil Shomron, Yuri Nahshan, Alex Bronstein, Uri Weiser.
Cuantización robusta: un modelo para gobernarlos a todos ,
ARXIV: 2002.07686, 2020.
Muhammad Abdullah Hanif, Muhammad Shafique.
Salvagednn: Salvando a los aceleradores de redes neuronales profundas con fallas permanentes a través del mapeo de fallas con el consumo de fallas ,
En las transacciones filosóficas de la Royal Society A: Ciencias Matemáticas, Físicas y de Ingeniería Volumen 378, Número 2164, 2019.
https://doi.org/10.1098/rsta.2019.0164
Meiqi Wang, Jianqiao MO, Jun Lin, Zhongfeng Wang, Li Du.
Dynexit: una estrategia dinámica de ejecución temprana para redes residuales profundas ,
En IEEE International Workshop on Signal Processing Systems (SIPS), 2019.
Vinu Joseph, Saurav Muralidharan, Animesh Garg, Michael Garland, Ganesh Gopalakrishnan.
Un enfoque programable para la compresión del modelo,
ARXIV: 1911.02497, 2019
código
Hui Guan, Lin Ning, Zhen Lin, Xipeng Shen, Huiyang Zhou, Seung-Hwan Lim.
Protección de memoria de espacio cero en el lugar para CNN ,
En Conferencia sobre Sistemas de Procesamiento de Información Neural (Neurips), 2019.
ARXIV: 1910.14479, 2019
código
Hossein Baktash, Emanuele Natale, Laurent Viennot.
Un estudio comparativo de la compresión de la red neuronal ,
ARXIV: 1910.11144, 2019.
Maxim Zemlyanikin, Alexander Smorkalov, Tatiana Khanova, Anna Petrovicheva, Grigory Serebryakov.
512kib ram es suficiente! Reconocimiento de la cara de la cámara en vivo DNN en MCU ,
En IEEE International Conference on Computer Vision (ICCV), 2019.
Ziheng Wang, Jeremy Wohlwend, Tao Lei.
Poda estructurada de modelos de idiomas grandes ,
ARXIV: 1910.04732, 2019.
Soroush Ghodrati, Hardik Sharma, Sean Kinzer, Amir Yazdanbakhsh, Kambiz Samadi, Nam Sung Kim, Doug Burger, Hadi Esmaeilzadeh.
Aceleración de dominio de carga de señal mixta de redes neuronales profundas a través de aritmética intercalada de bits ,
ARXIV: 1906.11915, 2019.
Gil Shomron, Tal Horowitz, Uri Weiser.
SMT-SA: Múltiple simultáneo en matrices sistólicas ,
En IEEE Computer Architecture Letters (Cal), 2019.
Shangqian Gao, Cheng Deng y Heng Huang.
Compresión del modelo de dominio cruzado por intercambio de peso estructural,
En la conferencia IEEE sobre visión por computadora y reconocimiento de patrones (CVPR), 2019, pp. 8973-8982.
Moin Nadeem, Wei Fang, Brian Xu, Mitra Mohtarami, James Glass.
FAKTA: un sistema automático de verificación de hechos de extremo a extremo,
En el Capítulo de América del Norte de la Asociación de Lingüística Computacional (NAACL), 2019.
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh.
Sinreq: regularización sinusoidal generalizada para el entrenamiento cuantificado de bajo ancho de bits,
ARXIV: 1905.01416, 2019. Código
Goncharenko A., Denisov A., Alyamkin S., Terentev E.
Umbrales capacitables para cuantización de redes neuronales,
En: Rojas I., Joya G., Catala A. (eds) Avances en las Notas de Lectura de Inteligencia Computacional en Ciencias de la Computación, Vol 11507. Springer, Cham. Conferencia de trabajo internacional en redes neuronales artificiales (Iwann 2019).
Ahmed T. Elthakeb, Prannoy Pilligundla, Hadi Esmaeilzadeh.
Divide y conquistar: aprovechando representaciones de características intermedias para la capacitación cuantificada de redes neuronales,
ARXIV: 1906.06033, 2019
Ritchie Zhao, Yuwei Hu, Jordan Dotzel, Christopher de SA, Zhiru Zhang.
Mejora de la cuantización de la red neuronal sin reentrenarse utilizando la división de canales atípicos,
ARXIV: 1901.09504, 2019
Código
Angad S. Rekhi, Brian Zimmer, Nikola Nedovic, Ningxi Liu, Rangharajan Venkatesan, Miaorong Wang, Brucek Khailany, William J. Dally, C. Thomas Gray.
Modelado de error de hardware analógico/de señal mixta para inferencia de aprendizaje profundo ,
Nvidia Research, 2019.
Norio nakata.
Desarrollo técnico reciente de inteligencia artificial para imágenes médicas de diagnóstico ,
En Japanese Journal of Radiology, febrero de 2019, Volumen 37, Número 2, pp 103-108.
Alexander Goncharenko, Andrey Denisov, Sergey Alyamkin, Evgeny Terentev.
Umbral de ajuste rápido para cuantización de red neuronal uniforme ,
ARXIV: 1812.07872, 2018
Si usó Distiller para su trabajo, utilice la siguiente cita:
@article{nzmora2019distiller,
author = {Neta Zmora and
Guy Jacob and
Lev Zlotnik and
Bar Elharar and
Gal Novik},
title = {Neural Network Distiller: A Python Package For DNN Compression Research},
month = {October},
year = {2019},
url = {https://arxiv.org/abs/1910.12232}
}
Cualquier trabajo publicado se basa en el trabajo de muchas otras personas, y el crédito pertenece a demasiadas personas para enumerar aquí.
Distiller se publica como código de referencia para fines de investigación. No es un producto Intel oficial, y el nivel de calidad y soporte puede no ser el esperado de un producto oficial. Se planea agregar algoritmos y características adicionales a la biblioteca. Los comentarios y las contribuciones de las comunidades de código abierto y de investigación son más que bienvenidos.


