GPT4Vis
1.0.0
Wenhao Wu 1,2 , Huanjin Yao 2,3 , Mengxi Zhang 2,4 , Yuxin Song 2 , Wanli Ouyang 5 , Jingdong Wang 2
1 มหาวิทยาลัยซิดนีย์, 2 Baidu, 3 มหาวิทยาลัย Tsinghua, 4 มหาวิทยาลัยเทียนจิน, 5 มหาวิทยาลัยจีนแห่งฮ่องกง
งานนี้นำเสนอพื้นฐานที่จำเป็น แต่ต้องรู้พื้นฐานในแง่ของความก้าวหน้าล่าสุดในการกำเนิดปัญญาประดิษฐ์ (Genai): การใช้ประโยชน์จาก GPT-4 เพื่อความเข้าใจด้วยสายตา เรามุ่งเน้นไปที่การประเมินความสามารถด้านภาษาศาสตร์และภาพของ GPT-4 ในงานการจดจำภาพที่ไม่มีการยิง เพื่อให้แน่ใจว่ามีการประเมินที่ครอบคลุมเราได้ทำการทดลองในสามรังสี - ภาพวิดีโอและเมฆจุด - รวมถึงมาตรฐานการศึกษาที่ได้รับความนิยมทั้งหมด 16 ครั้ง
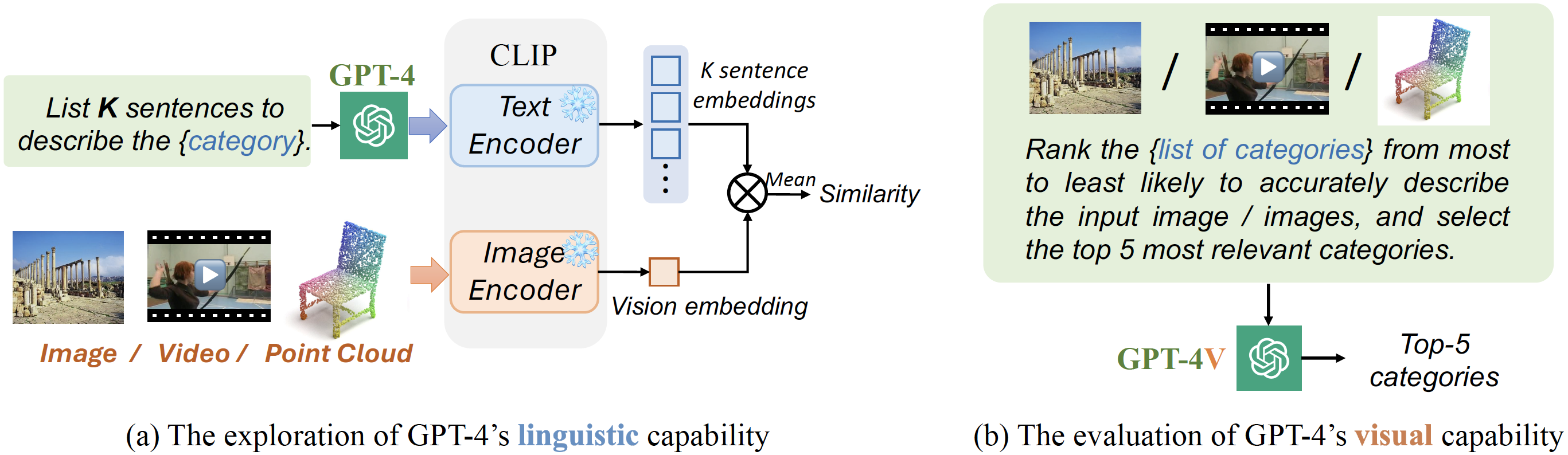
Revisiting ตัวแยกประเภท: การถ่ายโอนโมเดล Vision-Language สำหรับการจดจำวิดีโอ
Wenhao Wu, Zhun Sun, Wanli Ouyang
การสำรวจความรู้ข้ามรูปแบบสองทิศทางสำหรับการจดจำวิดีโอด้วยแบบจำลองภาษาวิสัยทัศน์ที่ผ่านการฝึกอบรมมาก่อน
Wenhao Wu, Xiaohan Wang, Haipeng Luo, Jingdong Wang, Yi Yang, Wanli Ouyang
CAP4VIDEO: คำบรรยายเสริมช่วยทำอะไรสำหรับการดึงข้อความวิดีโอ?
Wenhao Wu, Haipeng Luo, Bo Fang, Jingdong Wang, Wanli Ouyang
ยอมรับโดย CVPR 2023 AS? ไฮไลต์? -
การจดจำภาพศูนย์-ช็อตใช้ประโยชน์จากความสามารถทางภาษาและภาพของ GPT-4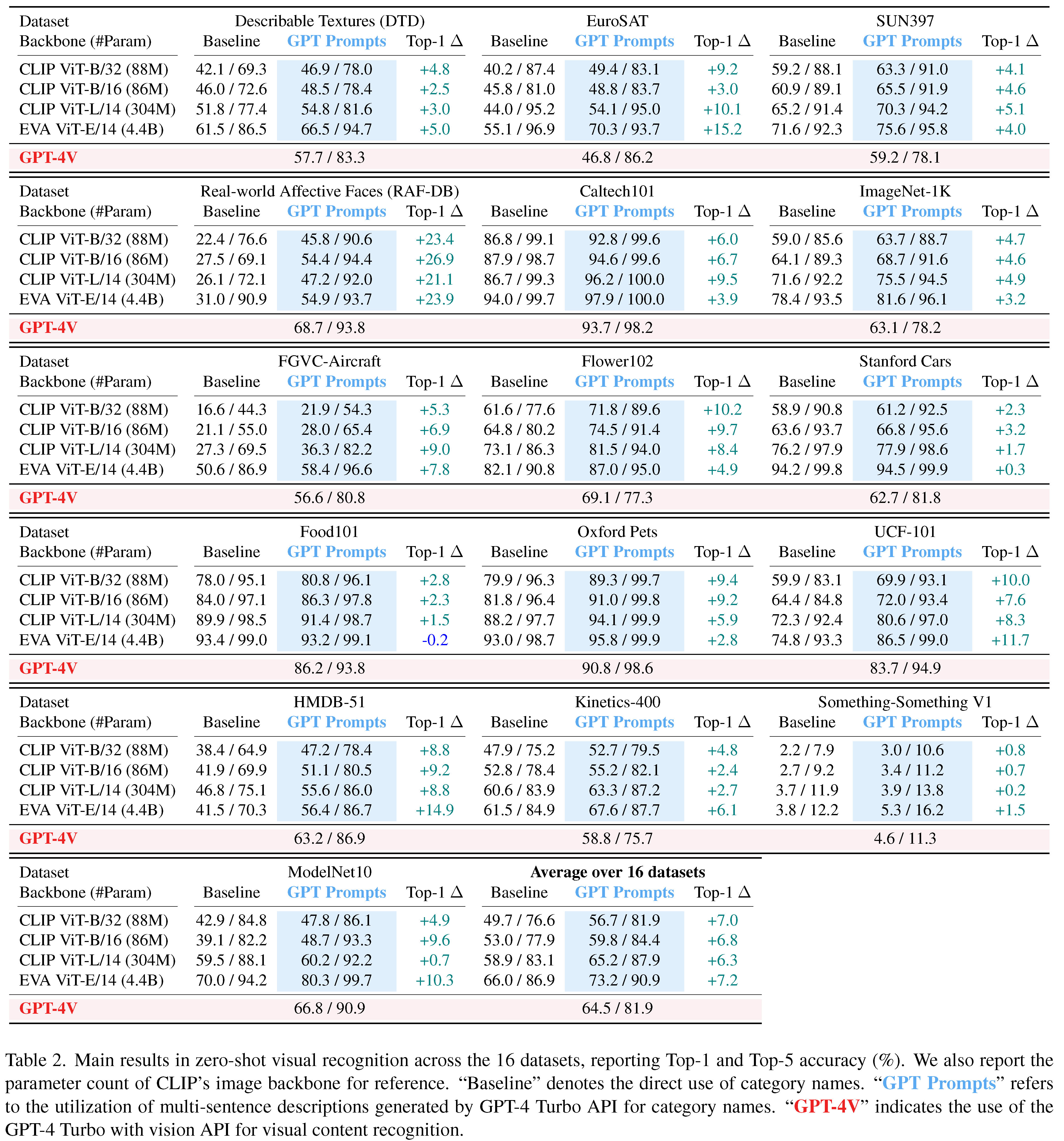

เรามีประโยคเชิงพรรณนาที่สร้างไว้ล่วงหน้าสำหรับหมวดหมู่ทั้งหมดในชุดข้อมูลซึ่งคุณสามารถค้นหาได้ในโฟลเดอร์ GPT_GENERATED_PROMPTS สนุกกับการสำรวจ!
นอกจากนี้เรายังได้จัดเตรียมสคริปต์ตัวอย่างเพื่อช่วยคุณสร้างคำอธิบายโดยใช้ GPT-4 สำหรับคำแนะนำเกี่ยวกับเรื่องนี้โปรดดูไฟล์ generate_prompt.py การเข้ารหัสมีความสุข! โปรดดูโฟลเดอร์ Config สำหรับข้อมูลโดยละเอียดเกี่ยวกับชุดข้อมูลทั้งหมดที่ใช้ในโครงการของเรา
ดำเนินการคำสั่งต่อไปนี้เพื่อสร้างคำอธิบายด้วย GPT-4
# To run the script for specific dataset, simply update the following line with the name of the dataset you're working with:
# dataset_name = ["Dataset Name Here"] # e.g., dtd
python generate_prompt.py
เราแบ่งปันสคริปต์ตัวอย่างที่แสดงวิธีใช้ GPT-4V API สำหรับการทำนายแบบไม่มีการยิงในชุดข้อมูล DTD โปรดดูไฟล์ gpt4v_zs.py สำหรับคู่มือทีละขั้นตอนในการใช้งานนี้ เราหวังว่ามันจะช่วยให้คุณเริ่มต้นได้อย่างง่ายดาย!
# GPT4V zero-shot recognition script.
# dataset_name = ["Dataset Name Here"] # e.g., dtd
python GPT4V_ZS.pyผลลัพธ์ทั้งหมดมีอยู่ในโฟลเดอร์ GPT4V_ZS_RESULTS ! นอกจากนี้เราได้ให้ ลิงก์ชุดข้อมูล พร้อมกับความจริงพื้นฐานที่สอดคล้องกัน (โฟลเดอร์ คำอธิบายประกอบ ) เพื่อช่วยผู้อ่านในการจำลองผลลัพธ์ หมายเหตุ: สำหรับชุดข้อมูลบางชุดเราอาจลบคำนำหน้าออกจาก ID ตัวอย่าง ตัวอย่างเช่นในกรณีของ Imagenet "ILSVRC2012_VAL_00031094.JPEG" ได้รับการแก้ไขเป็น "00031094.JPEG"
| DTD | เงินยูโร | SUN397 | RAF-DB | Caltech101 | Imagenet-1k | FGVC-Aircraft | ดอกไม้ 102 |
|---|---|---|---|---|---|---|---|
| 57.7 | 46.8 | 59.2 | 68.7 | 93.7 | 63.1 | 56.6 | 69.1 |
| ฉลาก | ฉลาก | ฉลาก | ฉลาก | ฉลาก | ฉลาก | ฉลาก | ฉลาก |
| รถสแตนฟอร์ด | Food101 | สัตว์เลี้ยงออกซ์ฟอร์ด | UCF-101 | HMDB-51 | จลนพลศาสตร์ -400 | ModelNet-10 |
|---|---|---|---|---|---|---|
| 62.7 | 86.2 | 90.8 | 83.7 | 58.8 | 58.8 | 66.9 |
| ฉลาก | ฉลาก | ฉลาก | ฉลาก | ฉลาก | ฉลาก | ฉลาก |
ด้วยไฟล์การทำนายและคำอธิบายประกอบที่ให้มาคุณสามารถทำซ้ำผลลัพธ์ความแม่นยำ TOP-1/TOP-5 ของเราด้วยสคริปต์ calculate_acc.py
# pred_json_path = 'GPT4V_ZS_Results/imagenet.json'
# gt_json_path = 'annotations/imagenet_gt.json'
python calculate_acc.pyสำหรับคำแนะนำเกี่ยวกับการตั้งค่าและเรียกใช้ GPT-4 API เราขอแนะนำให้ตรวจสอบเอกสาร OpenAI QuickStart อย่างเป็นทางการที่มีอยู่ที่: OpenAI QuickStart Guide
หากคุณใช้รหัสของเราในการวิจัยของคุณหรือต้องการอ้างถึงผลลัพธ์โปรดแสดงดาว? repo นี้และใช้ bibtex ต่อไปนี้? รายการ.
@article { GPT4Vis ,
title = { GPT4Vis: What Can GPT-4 Do for Zero-shot Visual Recognition? } ,
author = { Wu, Wenhao and Yao, Huanjin and Zhang, Mengxi and Song, Yuxin and Ouyang, Wanli and Wang, Jingdong } ,
booktitle = { arXiv preprint arXiv:2311.15732 } ,
year = { 2023 }
}การประเมินนี้สร้างขึ้นจากผลงานที่ยอดเยี่ยม:
เราขยายความกตัญญูอย่างจริงใจให้กับผู้มีส่วนร่วมเหล่านี้
สำหรับคำถามใด ๆ โปรดอย่าลังเลที่จะยื่นปัญหา


