ChatData
1.0.0
เรากำลังปรับปรุง Retriever ด้วยตนเองของ Langchain อย่างต่อเนื่อง คุณสมบัติบางอย่างยังไม่ได้รวมเข้าด้วยกัน

ยังมีแอพแชทกับเอกสารอื่น แต่สนับสนุนการสืบค้นมากกว่าหลายล้านไฟล์ด้วย MyScale และ Langchain
Chatdata เป็นแอปพลิเคชั่นแชทที่มีประสิทธิภาพที่ออกแบบมาเพื่อดึงข้อมูลและให้คำตอบโดยการสอบถามฐานความรู้ฟรี MyScale หรือเอกสารที่คุณอัปโหลด
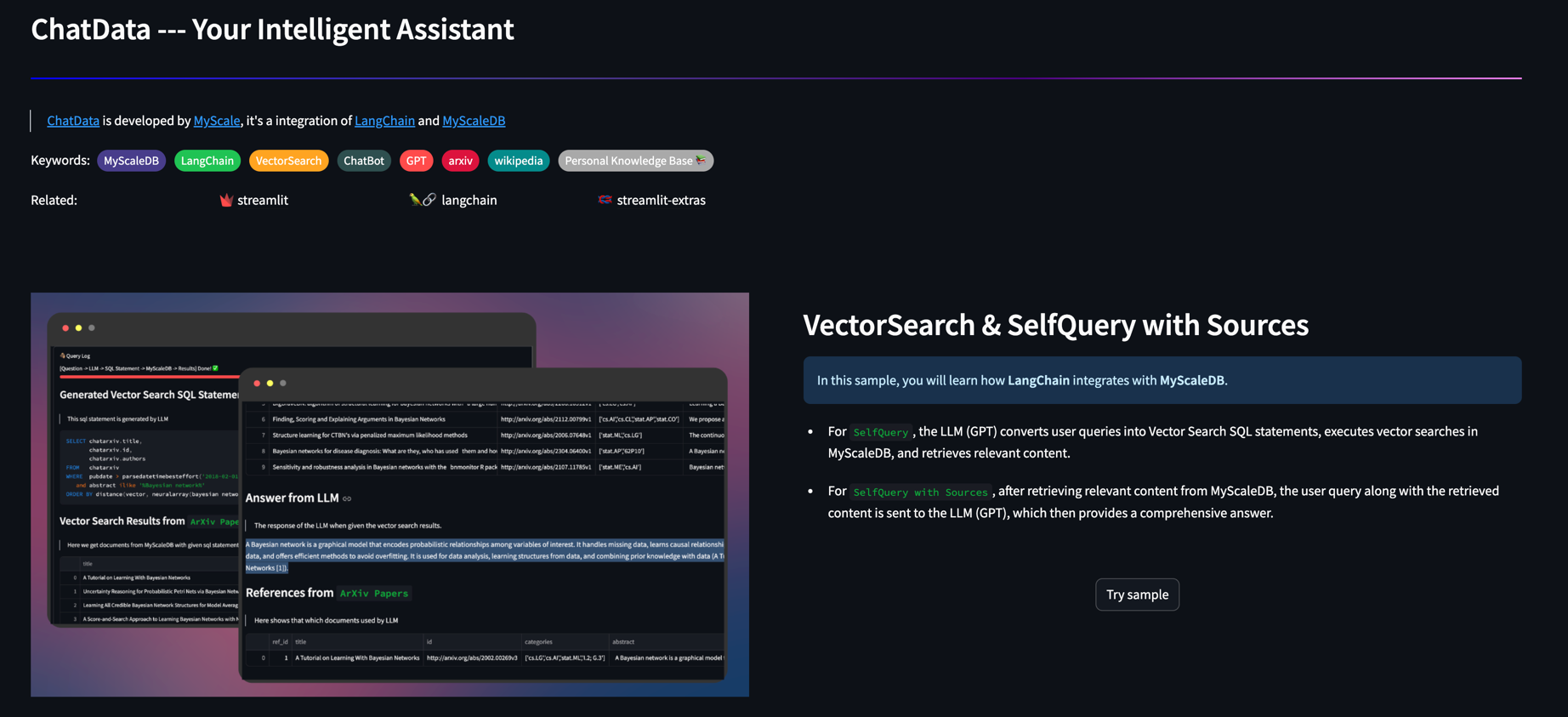
ขับเคลื่อนโดยเฟรมเวิร์ก Augmented Generation (RAG) Retrieval, Chatdata ใช้ประโยชน์จากหน้า Wikipedia หลายล้านหน้าและเอกสารอาร์กซ์เป็นฐานความรู้ภายนอกโดยมี MyScale จัดการงานโฮสต์ข้อมูลทั้งหมด เพียงแค่ป้อนคำถามของคุณในภาษาธรรมชาติและ Chatdata ดูแลการสร้าง SQL สอบถามข้อมูลและนำเสนอผลลัพธ์
เพิ่มประสบการณ์การแชทของคุณ Chatdata แนะนำคุณสมบัติที่สำคัญสามประการ ลองเจาะลึกลงไปในรายละเอียด
MyScale ทำงานอย่างใกล้ชิดกับ Langchain ซึ่งเป็นอินเทอร์เฟซที่ง่ายที่สุดในการสร้างแบบสอบถามที่ซับซ้อนด้วย LLM
Retriever แบบมีข้อสงสัยด้วยตนเอง: MyScale Augmented Self Querying Retriever ของ MyScale ซึ่ง LLM สามารถใช้ประเภทข้อมูลเพิ่มเติมเช่นการประทับเวลาและสตริงอาร์เรย์เพื่อสร้างตัวกรองสำหรับการสืบค้น
VectorsQL: SQL มีประสิทธิภาพและสามารถใช้ในการสร้างคำค้นหาที่ซับซ้อน Vector Structured Query Language (Vector SQL) ได้รับการออกแบบมาเพื่อสอน LLM วิธีการสอบถามฐานข้อมูลเวกเตอร์ SQL นอกจากประเภทข้อมูลและฟังก์ชั่นทั่วไปแล้ว VectorsQL ยังมีฟังก์ชั่นพิเศษเช่นระยะทาง (คอลัมน์, query_vector) และ NeuralArray (เอนทิตี) ซึ่งเราสามารถขยาย SQL มาตรฐานสำหรับการค้นหาเวกเตอร์
เพื่อปรับปรุงประสบการณ์ของคุณและการโต้ตอบกับเซสชันที่มีอยู่อย่างต่อเนื่อง Chatdata ได้แนะนำคุณสมบัติการจัดการเซสชัน คุณสามารถปรับแต่งรหัสเซสชันของคุณได้อย่างง่ายดายและแก้ไขพรอมต์ของคุณเพื่อแนะนำ Chatdata ในการสอบถามข้อมูลของคุณ ด้วยการคลิกเพียงไม่กี่ครั้งคุณสามารถเพลิดเพลินไปกับการโต้ตอบกับเซสชันที่ราบรื่นและเป็นส่วนตัว
นอกเหนือจากการแตะที่ฐานความรู้ภายนอกของ Chatdata ขับเคลื่อนโดย MyScale สำหรับคำตอบคุณยังมีตัวเลือกในการอัปโหลดไฟล์ของคุณเองและสร้างฐานความรู้ส่วนตัว เราได้ใช้ API ที่ไม่มีโครงสร้างเพื่อจุดประสงค์นี้เพื่อให้มั่นใจว่ามีการจัดเก็บข้อความจากเอกสารของคุณเท่านั้นที่จัดลำดับความสำคัญของข้อมูลความเป็นส่วนตัวของคุณ
โดยสรุปด้วย Chatdata คุณสามารถนำทางผ่านข้อมูลจำนวนมากได้อย่างง่ายดายเข้าถึงสิ่งที่คุณต้องการได้อย่างแม่นยำ ไม่ว่าคุณจะเป็นนักวิจัยนักเรียนหรือผู้ที่ชื่นชอบความรู้ Chatdata จะช่วยให้คุณสำรวจเอกสารทางวิชาการและเอกสารการวิจัยอย่างที่ไม่เคยมีมาก่อน ปลดล็อกศักยภาพที่แท้จริงของการดึงข้อมูลด้วย Chatdata และค้นพบโลกแห่งความรู้ที่ปลายนิ้วของคุณ
➡ดำน้ำและสัมผัสกับ Chatdata เมื่อกอดหน้า?
ข้อมูลรับรองฐานข้อมูล:
MYSCALE_HOST = " msc-950b9f1f.us-east-1.aws.myscale.com "
MYSCALE_PORT = 443
MYSCALE_USER = " chatdata "
MYSCALE_PASSWORD = " myscale_rocks " wiki.WikipediaChatdata ยังให้คุณเข้าถึง Wikipedia ซึ่งเป็นฐานความรู้ขนาดใหญ่ที่มีประมาณ 36 ล้านวรรคภายใต้ 5 ล้านหน้าวิกิ ฐานความรู้คือภาพรวมในปี 2022-12
คุณสามารถสอบถามได้จากตารางนี้ด้วยบัญชีสาธารณะที่นี่
CREATE TABLE wiki .Wikipedia (
-- Record ID
` id ` String,
-- Page title to this paragraph
` title ` String,
-- Paragraph text
` text ` String,
-- Page URL
` url ` String,
-- Wiki page ID
` wiki_id ` UInt64,
-- View statistics
` views ` Float32,
-- Paragraph ID
` paragraph_id ` UInt64,
-- Language ID
` langs ` UInt32,
-- Feature vector to this paragraph
` emb ` Array(Float32),
-- Vector Index
VECTOR INDEX emb_idx emb TYPE MSTG( ' metric_type=Cosine ' ),
CONSTRAINT emb_len CHECK length(emb) = 768 )
ENGINE = ReplacingMergeTree ORDER BY id SETTINGS index_granularity = 8192 default.ChatArXivChatdata นำเอกสารนับล้านเข้ามาในฐานความรู้ของคุณ เรานำเข้าเอกสาร 2.2 ล้านฉบับพร้อมข้อมูลข้อมูลเมตาซึ่งมี:
id : arxiv id ของกระดาษabstract : บทคัดย่อของกระดาษใช้เป็นเกณฑ์การจัดอันดับ (พร้อม contractxl)vector : คอลัมน์ที่มีเวกเตอร์อาร์เรย์ใน Array(Float32)metadata : คอลัมน์ที่เข้ากันได้ของ Langchain Vectorstoremetadata.authors : ผู้เขียนกระดาษใน รายการสตริงmetadata.abstract : บทคัดย่อของกระดาษใช้เป็นเกณฑ์การจัดอันดับ (พร้อม contractxl)metadata.titles : ชื่อของเอกสารmetadata.categories : หมวดหมู่ของกระดาษใน รายการสตริง เช่น ["CS.CV"]metadata.pubdate : วันที่ตีพิมพ์ของกระดาษใน iso 8601 strings ที่จัดตั้งขึ้นmetadata.primary_category : หมวดหมู่หลักของ Paper ใน สตริง ที่กำหนดโดย arxivmetadata.comment : ความคิดเห็นเพิ่มเติมบางอย่างกับกระดาษคอลัมน์ด้านล่างเป็นคอลัมน์ดั้งเดิมใน myscale และสามารถใช้เป็น sqldatabase เท่านั้น
authors : ผู้เขียนกระดาษใน รายการสตริงtitles : ชื่อของเอกสารcategories : หมวดหมู่ของกระดาษใน รายการสตริง เช่น ["CS.CV"]pubdate : วันที่ตีพิมพ์ของกระดาษใน ประเภทข้อมูลวันที่ 32 (เร็วขึ้น)primary_category : หมวดหมู่หลักของกระดาษใน สตริง ที่กำหนดโดย arxivcomment : ความคิดเห็นเพิ่มเติมบางอย่างกับกระดาษและสำหรับสคีมาตารางโดยรวมโปรดดูส่วนการสร้างตารางในเอกสาร/query.md
หากคุณต้องการใช้ฐานข้อมูลนี้กับ langchain.chains.sql_database.base.SQLDatabaseChain หรือ langchain.retrievers.SQLDatabaseRetriever โปรดติดตามคำแนะนำเกี่ยวกับส่วนการเตรียมข้อมูลและส่วนการสร้างโซ่ในเอกสาร/vector-sql.md
จากไฟล์ Parquet บน S3
หรือใช้ฐานข้อมูล myscale โดยตรงเป็นบริการ ... ฟรี
import clickhouse_connect
client = clickhouse_connect . get_client (
host = 'msc-950b9f1f.us-east-1.aws.myscale.com' ,
port = 443 ,
username = 'chatdata' ,
password = 'myscale_rocks'
)app/ cd app/python3 -m venv venv
source venv/bin/activatepython3 -m pip install -r requirements.txt # fill you OpenAI key in .streamlit/secrets.toml
cp . streamlit / secrets . example . toml . streamlit / secrets . toml
# start the app
python3 - m streamlit run app . pyอ่านบทความฉบับเต็ม
อ่านบทความฉบับเต็ม


