ChatData
1.0.0
Мы постоянно совершенствуем самостоятельный ретривер Лэнгчейна. Некоторые из функций еще не объединены.

Еще одно приложение в чате с документами, но поддержка запроса на миллионы файлов с помощью MyScale и Langchain.
Чатдата-это надежное приложение в чате с документами, предназначенное для извлечения информации и предоставления ответов, запрашивая бесплатную базу знаний MyScale или загруженные документы.
Основанная на рамках извлеченного добыченного поколения (RAG), Chatdata использует миллионы страниц Википедии и арксивские документы в качестве своей внешней базы знаний, с MyScale управлять всеми задачами по размещению данных. Просто введите свои вопросы на естественном языке, и Чатдата заботится о создании SQL, запросе данных и представлении результатов.
Улучшение вашего чата, Чатдата представляет три ключевых функции. Давайте подробно расскажем о каждом из них.
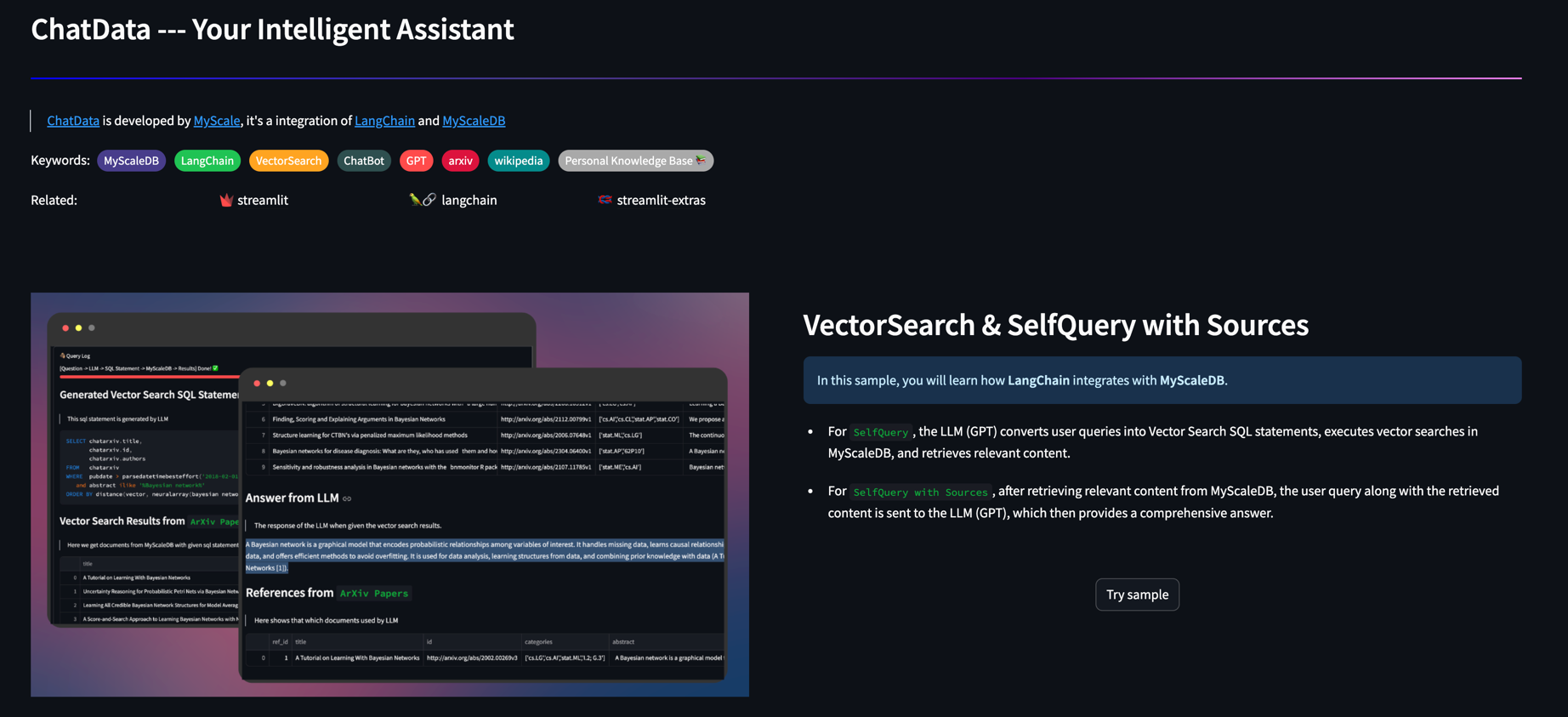
MyScale тесно сотрудничает с Langchain, обеспечивая самый простой интерфейс для создания сложных запросов с LLM.
Самооценка ретривера: MyScale Aucmented Langchain's Self-retriever, где LLM может использовать больше типов данных, например, метки времени и массивы строк, для создания фильтров для запроса.
VectorsQL: SQL является мощным и может использоваться для построения сложных поисковых запросов. Векторный структурированный язык запросов (Vector SQL) предназначен для обучения LLMS, как запросить SQL Vector Databases. Помимо общих типов и функций данных, VectorsQL содержит дополнительные функции, такие как расстояние (столбец, Query_vector) и NeuralArray (Entity), с помощью которых мы можем расширить стандартный SQL для поиска вектора.
Чтобы улучшить ваш опыт и плавно продолжать взаимодействие с существующими сессиями, Chatdata представила функцию управления сеансом. Вы можете легко настроить свой идентификатор сеанса и изменить свою подсказку для руководства ChatData при обращении к вашим запросам. С всего лишь нескольких кликов вы можете наслаждаться плавными и персонализированными сеансами взаимодействия.
В дополнение к тому, чтобы использовать внешнюю базу знаний Чатдаты, основанную на MyScale для ответов, у вас также есть возможность загружать свои собственные файлы и установить персонализированную базу знаний. Для этой цели мы реализовали неструктурированный API, гарантируя, что хранятся только обработанные тексты из ваших документов, определяя приоритеты вашей конфиденциальности данных.
В заключение, с Chatdata вы можете без особых усилий перемещаться по огромным объему данных, легко добравшись точно так, как вам нужно. Являетесь ли вы исследователем, студентом или энтузиастом знаний, Chatdata дает вам возможность изучить академические документы и исследовательские документы, как никогда раньше. Разблокируйте истинный потенциал поиска информации с Чатдатой и откройте для себя мир знаний.
➡ Погрузитесь и испытайте Чатдату на обнимании лица?
Учетные данные базы данных:
MYSCALE_HOST = " msc-950b9f1f.us-east-1.aws.myscale.com "
MYSCALE_PORT = 443
MYSCALE_USER = " chatdata "
MYSCALE_PASSWORD = " myscale_rocks " wiki.WikipediaЧатдата также предоставляет вам доступ к Википедии, большой базе знаний, которая содержит около 36 миллионов абзацев до 5 миллионов страниц вики. База знаний-это снимок в 2022-12.
Вы можете запросить из этой таблицы с публичным аккаунтом здесь.
CREATE TABLE wiki .Wikipedia (
-- Record ID
` id ` String,
-- Page title to this paragraph
` title ` String,
-- Paragraph text
` text ` String,
-- Page URL
` url ` String,
-- Wiki page ID
` wiki_id ` UInt64,
-- View statistics
` views ` Float32,
-- Paragraph ID
` paragraph_id ` UInt64,
-- Language ID
` langs ` UInt32,
-- Feature vector to this paragraph
` emb ` Array(Float32),
-- Vector Index
VECTOR INDEX emb_idx emb TYPE MSTG( ' metric_type=Cosine ' ),
CONSTRAINT emb_len CHECK length(emb) = 768 )
ENGINE = ReplacingMergeTree ORDER BY id SETTINGS index_granularity = 8192 default.ChatArXivЧатдата приносит миллионы бумаг в вашу базу знаний. Мы импортировали 2,2 миллиона документов с информацией о метаданных, которая содержит:
id : идентификатор бумаги Arxivabstract : Тезисы Paper, используемые в качестве критерия ранжирования (с инструктом)vector : столбец, который содержит векторный массив в Array(Float32)metadata : совместимые с лангхайной вектором столбцыmetadata.authors : авторы Paper в списке строкmetadata.abstract .metadata.titles : названия газетmetadata.categories .metadata.pubdate : дата публикации бумаги в ISO 8601 Формированные строкиmetadata.primary_categorymetadata.comment : некоторые дополнительные комментарии к газетеСтолбцы ниже являются собственными столбцами в MyScale и могут использоваться только в качестве SQLDATABASE
authors : авторы Paper в списке строкtitles : Названия газетcategories : категории бумаги в списке строк , таких как ["cs.cv"]pubdate : дата публикации бумаги в Date32 Тип данных (быстрее)primary_category : основная категория Paper в строках , определенная Arxivcomment : некоторые дополнительные комментарии к газетеИ для общей схемы таблицы, пожалуйста, обратитесь к разделу создания таблицы в Docs/Self-Query.md.
Если вы хотите использовать эту базу данных с помощью langchain.chains.sql_database.base.SQLDatabaseChain или langchain.retrievers.SQLDatabaseRetriever , следуйте руководствам по разделу подготовки данных и разделу креации цепи в Docs/vector-sql.md
Из паркетных файлов на S3
Или напрямую используйте базу данных MyScale в качестве службы ... бесплатно
import clickhouse_connect
client = clickhouse_connect . get_client (
host = 'msc-950b9f1f.us-east-1.aws.myscale.com' ,
port = 443 ,
username = 'chatdata' ,
password = 'myscale_rocks'
)app/ cd app/python3 -m venv venv
source venv/bin/activatepython3 -m pip install -r requirements.txt # fill you OpenAI key in .streamlit/secrets.toml
cp . streamlit / secrets . example . toml . streamlit / secrets . toml
# start the app
python3 - m streamlit run app . pyПрочитайте полную статью
Прочитайте полную статью


