ChatData
1.0.0
Wir verbessern ständig Langchains Selbstadretriever. Einige der Funktionen werden noch nicht verschmolzen.

Noch eine Chat-mit-Dokumenten-App, aber die Abfrage über Millionen von Dateien mit MyScale und Langchain unterstützt.
ChatData ist eine robuste Chat-mit-Dokumente, mit der Informationen extrahiert und Antworten geliefert werden, indem die kostenlose Wissensbasis von MyScale oder Ihre hochgeladenen Dokumente abfragt.
Chatdata wird durch den Rahmen von RAGED -Rahmen für Augmented Generation (RAG) angetrieben und nutzt Millionen von Wikipedia -Seiten und Arxiv -Papieren als externe Wissensbasis, wobei MyScale alle Daten zur Hosting -Aufgaben verwaltet. Geben Sie einfach Ihre Fragen in die natürliche Sprache ein, und Chatdata kümmert sich um das Generieren von SQL, die Abfragetation der Daten und die Präsentation der Ergebnisse.
Chatdata verbessert Ihr Chat -Erlebnis und führt drei wichtige Funktionen ein. Lassen Sie uns ausführlich in sie eintauchen.
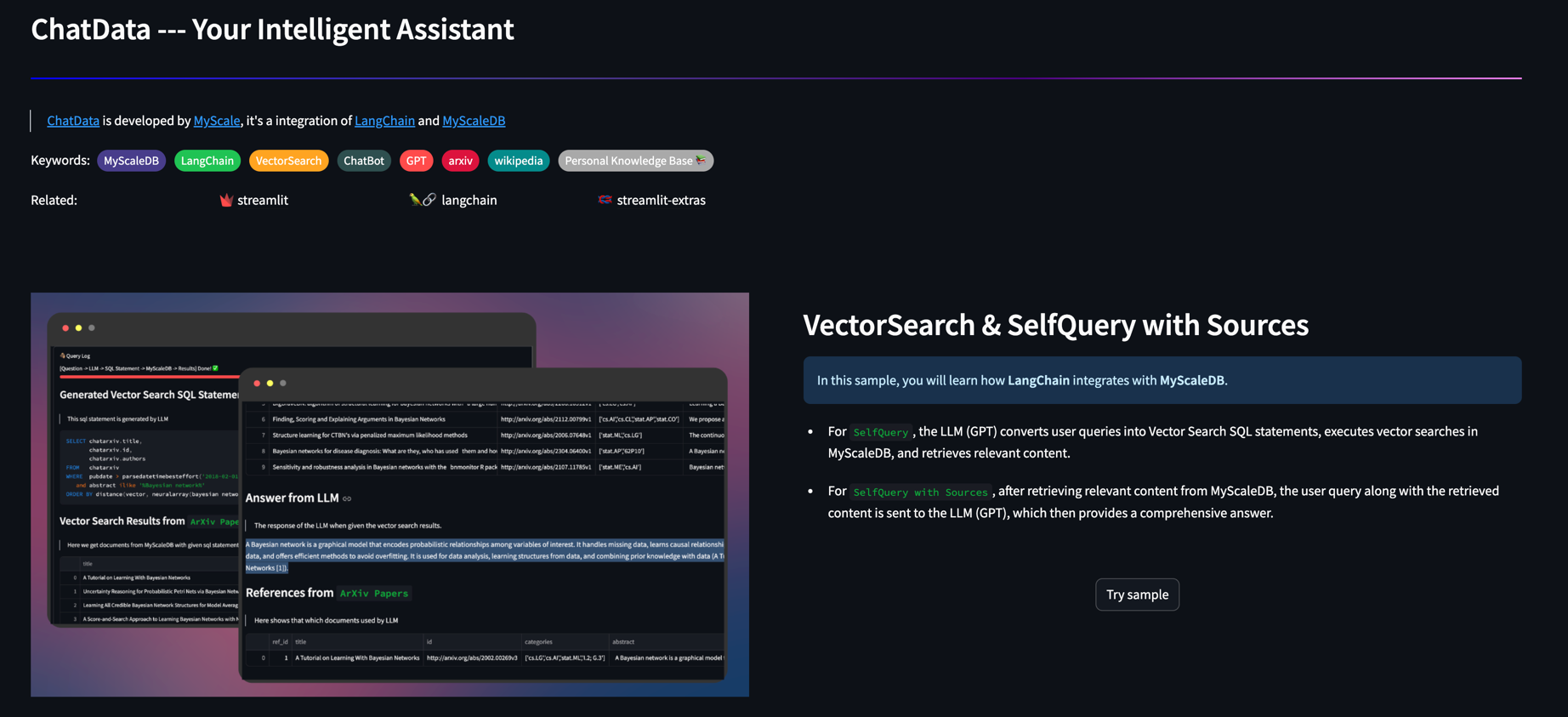
MyScale arbeitet eng mit Langchain zusammen und bietet die einfachste Schnittstelle, um komplexe Abfragen mit LLM zu erstellen.
Self-Retriever: MyScale Augmented Langchains Selbstabfrage-Retriever, wobei der LLM mehr Datentypen verwenden kann, z. B. Zeitstempel und Array von Zeichenfolgen, um Filter für die Abfrage zu erstellen.
VectorsQL: SQL ist leistungsstark und kann verwendet werden, um komplexe Suchabfragen zu konstruieren. Vector Structured Query Language (Vector SQL) soll LLMs vermitteln, wie SQL -Vektor -Datenbanken abfragen. Neben den allgemeinen Datentypen und Funktionen enthält VectorsQL zusätzliche Funktionen wie Distanz (Spalte, Query_Vector) und NeuralArray (Entity), mit denen wir die Standard -SQL für die Vektorsuche erweitern können.
Um Ihre Erfahrungen zu verbessern und die Interaktionen mit vorhandenen Sitzungen nahtlos fortzusetzen, hat ChatData die Funktionsverwaltungsfunktion eingeführt. Sie können Ihre Sitzungs -ID problemlos anpassen und Ihre Eingabeaufforderung ändern, um ChatData bei der Adressierung Ihrer Abfragen zu führen. Mit nur wenigen Klicks können Sie reibungslose und personalisierte Sitzungsinteraktionen genießen.
Zusätzlich zum Tippen auf die externe Wissensbasis von ChatData von MyScale für Antworten haben Sie auch die Möglichkeit, Ihre eigenen Dateien hochzuladen und eine personalisierte Wissensbasis einzurichten. Wir haben die unstrukturierte API zu diesem Zweck implementiert, um sicherzustellen, dass nur verarbeitete Texte aus Ihren Dokumenten gespeichert werden und Ihre Datenschutzpriorität priorisieren.
Zusammenfassend können Sie mit ChatData mühelos durch große Mengen an Daten navigieren und mühelos auf genau das zugreifen, was Sie benötigen. Egal, ob Sie ein Forscher, ein Student oder ein Wissensliebhaber sind, Chatdata ermöglicht es Ihnen, akademische Papiere und Forschungsdokumente wie nie zuvor zu erforschen. Schalte das wahre Potenzial des Informationsabrufs mit Chatdata frei und entdecken Sie eine Welt des Wissens in Ihren Fingerspitzen.
➡️ Tauchen Sie ein und erleben Sie Chatdata auf dem Umarmungsgesicht?
Datenbankanmeldeinformationen:
MYSCALE_HOST = " msc-950b9f1f.us-east-1.aws.myscale.com "
MYSCALE_PORT = 443
MYSCALE_USER = " chatdata "
MYSCALE_PASSWORD = " myscale_rocks " wiki.WikipediaChatdata bietet Ihnen auch Zugriff auf Wikipedia, eine große Wissensbasis, die etwa 36 Millionen Absätze unter 5 Millionen Wiki -Seiten enthält. Die Wissensbasis ist ein Schnappschuss für 2022-12.
Sie können hier mit dem öffentlichen Konto aus dieser Tabelle abfragen.
CREATE TABLE wiki .Wikipedia (
-- Record ID
` id ` String,
-- Page title to this paragraph
` title ` String,
-- Paragraph text
` text ` String,
-- Page URL
` url ` String,
-- Wiki page ID
` wiki_id ` UInt64,
-- View statistics
` views ` Float32,
-- Paragraph ID
` paragraph_id ` UInt64,
-- Language ID
` langs ` UInt32,
-- Feature vector to this paragraph
` emb ` Array(Float32),
-- Vector Index
VECTOR INDEX emb_idx emb TYPE MSTG( ' metric_type=Cosine ' ),
CONSTRAINT emb_len CHECK length(emb) = 768 )
ENGINE = ReplacingMergeTree ORDER BY id SETTINGS index_granularity = 8192 default.ChatArXivChatdata bringt Millionen von Papieren in Ihre Wissensbasis. Wir haben 2,2 Millionen Papiere mit Metadateninformationen importiert, die enthält:
idabstract : Papierabtrakte, die als Ranking -Kriterium verwendet werden (mit Instructxl)vector : Spalte, die das Vektorarray in Array(Float32)metadata : Langchain Vectorstore kompatible Spaltenmetadata.authors : Papierautoren in Liste der Saitenmetadata.abstract : Papiers Abstracts, die als Ranking -Kriterium verwendet werden (mit Instructxl)metadata.titles : Papers -Titelmetadata.categories : Papierkategorien in Liste der Zeichenfolgen wie ["Cs.cv"]metadata.pubdate : Veröffentlichungsdatum des Papiers in ISO 8601 Formatierte Zeichenfolgenmetadata.primary_category : die primäre Kategorie des Papiers in von Arxiv definierten Zeichenfolgenmetadata.comment : Einige zusätzliche Kommentare zum PapierSpalten unten sind native Spalten in MyScale und können nur als SQLDATABase verwendet werden
authors : Autoren von Papier in Liste der Zeichenfolgentitles : Papiere Titelcategories : Papierkategorien in Liste der Zeichenfolgen wie ["Cs.cv"]pubdate : Veröffentlichungsdatum des Papiers in Datum 32 Datentyp (schneller)primary_category : Die primäre Kategorie des Papiers in von Arxiv definierten Zeichenfolgencomment : Ein zusätzlicher Kommentar zum PapierUnd für das Gesamtstabsschema finden Sie im Abschnitt "Tabellenerstellung" in DOCs/Self-Query.md.
Wenn Sie diese Datenbank mit langchain.chains.sql_database.base.SQLDatabaseChain oder langchain.retrievers.SQLDatabaseRetriever verwenden möchten, befolgen Sie bitte die Anleitungen zum Abschnitt "Datenvorbereitungen" und "Kettenerstellung Abschnitt"/Vector-SQL.MD
Aus Parkettdateien auf S3
Oder verwenden Sie die MyScale -Datenbank direkt als Service ... kostenlos
import clickhouse_connect
client = clickhouse_connect . get_client (
host = 'msc-950b9f1f.us-east-1.aws.myscale.com' ,
port = 443 ,
username = 'chatdata' ,
password = 'myscale_rocks'
)app/ cd app/python3 -m venv venv
source venv/bin/activatepython3 -m pip install -r requirements.txt # fill you OpenAI key in .streamlit/secrets.toml
cp . streamlit / secrets . example . toml . streamlit / secrets . toml
# start the app
python3 - m streamlit run app . pyLesen Sie den vollständigen Artikel
Lesen Sie den vollständigen Artikel


