ChatData
1.0.0
Estamos constantemente melhorando o Retriever de Langchain. Alguns dos recursos ainda não foram mesclados.

Outro aplicativo de bate-papo com documentos, mas suportando consultas sobre milhões de arquivos com o MyScale e o Langchain.
O ChatData é um aplicativo robusto de Chat-With-Documents, projetado para extrair informações e fornecer respostas, consultando a Base de Conhecimento Grátis do MyScale ou seus documentos enviados.
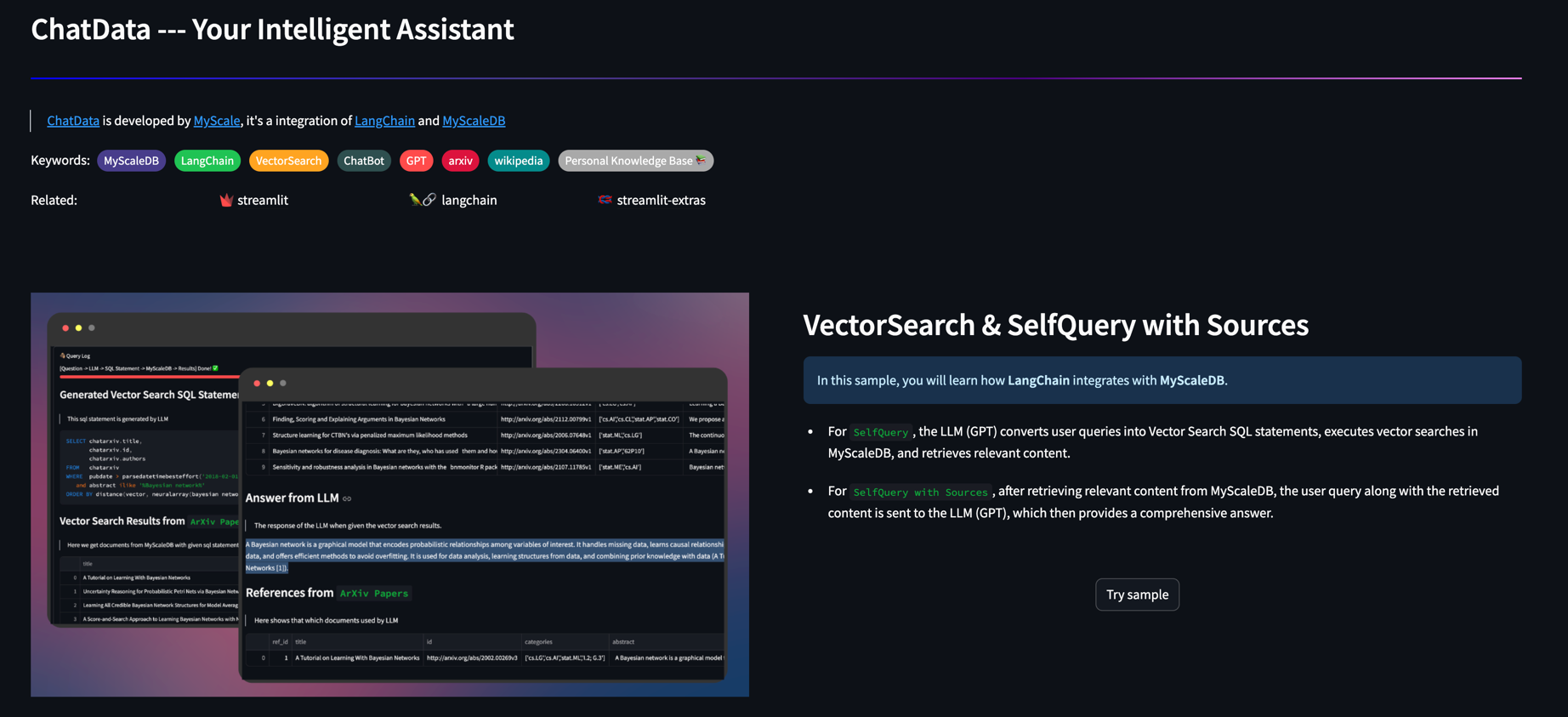
Alimentado pela estrutura de geração aumentada de recuperação (RAG), o ChatData alavanca milhões de páginas da Wikipedia e artigos ARXIV como sua base de conhecimento externa, com o MyScale gerenciando todas as tarefas de hospedagem de dados. Simplesmente insira suas perguntas em linguagem natural, e o ChatData cuida de gerar SQL, consultar os dados e apresentar os resultados.
Aprimorando sua experiência de bate -papo, o ChatData apresenta três recursos principais. Vamos nos aprofundar em cada um deles em detalhes.
O MyScale trabalha em estreita colaboração com Langchain, fornecendo a interface mais fácil para criar consultas complexas com o LLM.
Retriever auto-inquietante: MyScale aumentou o Retriever de consulta de Langchain, onde o LLM pode usar mais tipos de dados, por exemplo, registro de data e hora e matriz de strings, para criar filtros para a consulta.
VectorsQL: O SQL é poderoso e pode ser usado para construir consultas de pesquisa complexas. O Vector Structured Query Language (Vector SQL) foi projetado para ensinar LLMs a consultar bancos de dados de vetores SQL. Além dos tipos e funções gerais de dados, o VectorSQL contém funções extras como distância (coluna, query_vector) e neuralArray (entidade), com a qual podemos estender o SQL padrão para pesquisa vetorial.
Para aprimorar sua experiência e continuar perfeitamente interações com as sessões existentes, o ChatData introduziu o recurso de gerenciamento de sessão. Você pode personalizar facilmente o ID da sessão e modificar seu prompt para orientar o ChatData para abordar suas consultas. Com apenas alguns cliques, você pode desfrutar de interações suaves e personalizadas da sessão.
Além de explorar a base de conhecimento externa da ChatData, alimentada pelo MyScale para obter respostas, você também tem a opção de fazer upload de seus próprios arquivos e estabelecer uma base de conhecimento personalizada. Implementamos a API não estruturada para esse fim, garantindo que apenas os textos processados de seus documentos sejam armazenados, priorizando sua privacidade de dados.
Em conclusão, com o ChatData, você pode navegar sem esforço por vastas quantidades de dados, acessando com precisão o que precisa. Seja você um pesquisador, um estudante ou um entusiasta do conhecimento, o ChatData o capacita a explorar trabalhos acadêmicos e documentos de pesquisa como nunca antes. Desbloqueie o verdadeiro potencial da recuperação de informações com o ChatData e descubra um mundo de conhecimento na ponta dos dedos.
➡️ mergulhe e experimente Chatdata em abraçar o rosto?
Credenciais de banco de dados:
MYSCALE_HOST = " msc-950b9f1f.us-east-1.aws.myscale.com "
MYSCALE_PORT = 443
MYSCALE_USER = " chatdata "
MYSCALE_PASSWORD = " myscale_rocks " wiki.WikipediaO ChatData também fornece acesso à Wikipedia, uma grande base de conhecimento que contém cerca de 36 milhões de parágrafos abaixo de 5 milhões de páginas wiki. A base de conhecimento é um instantâneo em 2022-12.
Você pode consultar esta tabela com a conta pública aqui.
CREATE TABLE wiki .Wikipedia (
-- Record ID
` id ` String,
-- Page title to this paragraph
` title ` String,
-- Paragraph text
` text ` String,
-- Page URL
` url ` String,
-- Wiki page ID
` wiki_id ` UInt64,
-- View statistics
` views ` Float32,
-- Paragraph ID
` paragraph_id ` UInt64,
-- Language ID
` langs ` UInt32,
-- Feature vector to this paragraph
` emb ` Array(Float32),
-- Vector Index
VECTOR INDEX emb_idx emb TYPE MSTG( ' metric_type=Cosine ' ),
CONSTRAINT emb_len CHECK length(emb) = 768 )
ENGINE = ReplacingMergeTree ORDER BY id SETTINGS index_granularity = 8192 default.ChatArXivO ChatData traz milhões de papéis para sua base de conhecimento. Importamos 2,2 milhões de artigos com informações de metadados, que contém:
idabstract : Resumos do artigo usado como critério de classificação (com InstructXL)vector : coluna que contém a matriz vetorial na Array(Float32)metadata : colunas compatíveis com Vectorsore de Langchainmetadata.authors : autores do Paper na lista de stringsmetadata.abstract : resumos do artigo usado como critério de classificação (com InstructXL)metadata.titles : títulos dos papéismetadata.categories : categorias do artigo na lista de strings como ["cs.cv"]metadata.pubdate : Data de publicação do artigo na ISO 8601 Strings formadosmetadata.primary_category : Categoria Primária do Paper em Strings definidas por ARXIVmetadata.comment : algum comentário adicional ao artigoAs colunas abaixo são colunas nativas em MyScale e só podem ser usadas como sqldatabase
authors : autores do Paper na lista de stringstitles : títulos dos papéiscategories : categorias do artigo na lista de strings como ["cs.cv"]pubdate : data de publicação do artigo no Date32 Tipo de dados (mais rápido)primary_category : categoria principal do artigo em strings definidos por arxivcomment : Algum comentário adicional ao artigoE para o esquema geral da tabela, consulte a seção de criação de tabela em documentos/auto-query.md.
Se você deseja usar este banco de dados com langchain.chains.sql_database.base.SQLDatabaseChain ou langchain.retrievers.SQLDatabaseRetriever , siga os Guides na seção de preparação de dados e seção de criação de cadeia em documentos/vetor-sql.md
De arquivos parquet no S3
Ou use diretamente o banco de dados do MyScale como serviço ... gratuitamente
import clickhouse_connect
client = clickhouse_connect . get_client (
host = 'msc-950b9f1f.us-east-1.aws.myscale.com' ,
port = 443 ,
username = 'chatdata' ,
password = 'myscale_rocks'
)app/ cd app/python3 -m venv venv
source venv/bin/activatepython3 -m pip install -r requirements.txt # fill you OpenAI key in .streamlit/secrets.toml
cp . streamlit / secrets . example . toml . streamlit / secrets . toml
# start the app
python3 - m streamlit run app . pyLeia o artigo completo
Leia o artigo completo


