ChatData
1.0.0
우리는 Langchain의 자체 정체 리트리버를 지속적으로 개선하고 있습니다. 일부 기능은 아직 병합되지 않았습니다.

또 다른 채팅이있는 Documents 앱이지만 MyScale 및 Langchain을 사용하여 수백만 개의 파일에 대한 쿼리를 지원합니다.
ChatData는 MyScale Free Knowledge Base 또는 업로드 된 문서를 쿼리하여 정보를 추출하고 답변을 제공하도록 설계된 강력한 Chat-With-Documents 응용 프로그램입니다.
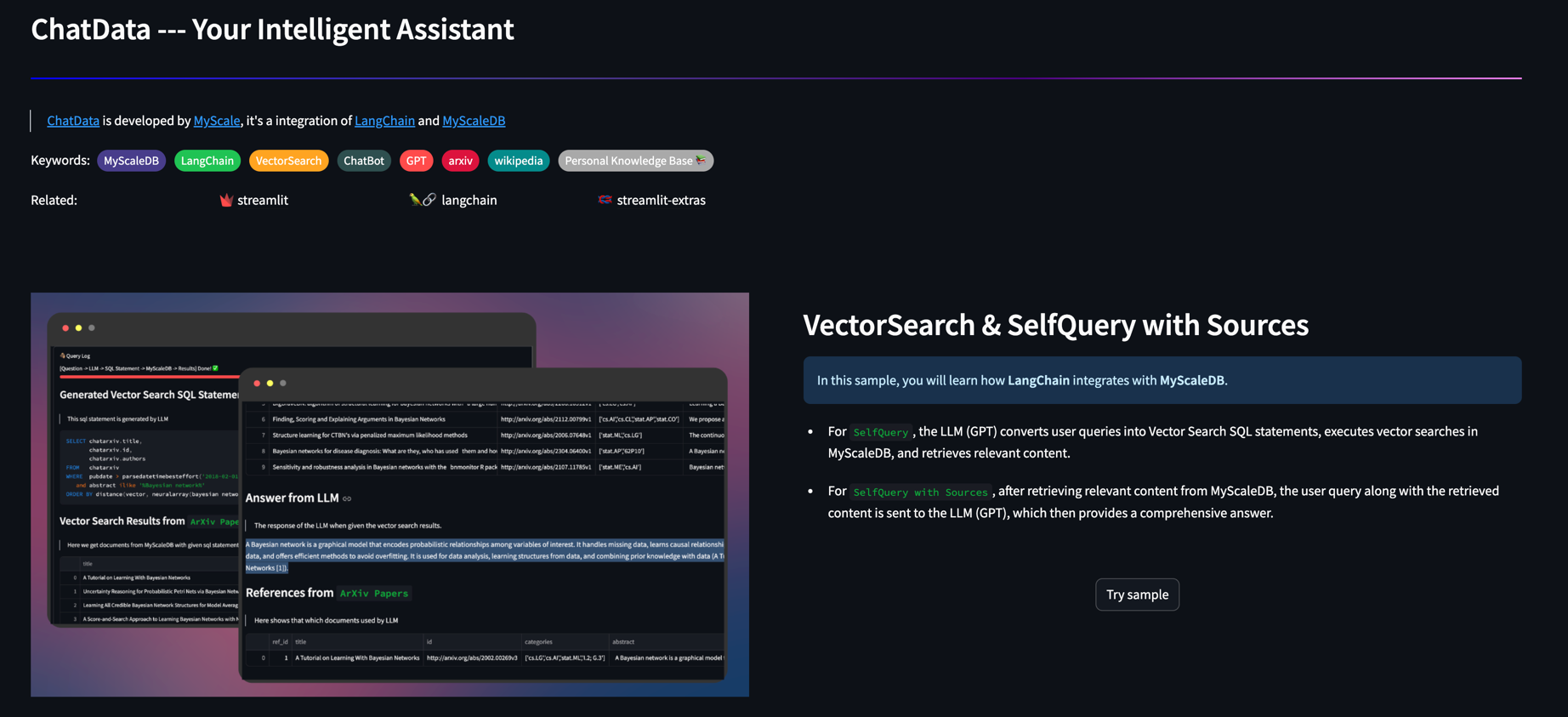
RAG (Respreval Augmented Generation) 프레임 워크에 의해 구동되는 ChatData는 수백만 개의 Wikipedia 페이지와 ARXIV 용지를 외부 지식 기반으로 활용하며 모든 데이터 호스팅 작업을 관리하는 MyScale. 단순히 질문을 자연어로 입력하면 ChatData는 SQL을 생성하고 데이터를 쿼리하며 결과를 제시하는 것을 관리합니다.
채팅 경험을 향상시켜 ChatData는 세 가지 주요 기능을 소개합니다. 각각을 자세히 살펴 보겠습니다.
MyScale은 Langchain과 긴밀히 협력하여 LLM으로 복잡한 쿼리를 구축하기위한 가장 쉬운 인터페이스를 제공합니다.
자체 질문 리트리버 : MyScale은 Langchain의 자체 쿼리 리트리버를 확대했습니다. LLM은 더 많은 데이터 유형 (예 : 타임 스탬프 및 문자열 배열)을 사용하여 쿼리 용 필터를 구축 할 수 있습니다.
VectorsQL : SQL은 강력하며 복잡한 검색 쿼리를 구성하는 데 사용할 수 있습니다. 벡터 구조화 된 쿼리 언어 (Vector SQL)는 LLMS에 SQL 벡터 데이터베이스를 쿼리하는 방법을 가르치도록 설계되었습니다. 일반적인 데이터 유형 및 함수 외에도 VectorsQL에는 거리 (열, Query_vector) 및 NeuralArray (Entity)와 같은 추가 기능이 포함되어 있으며 벡터 검색을 위해 표준 SQL을 확장 할 수 있습니다.
경험을 향상시키고 기존 세션과 원활하게 상호 작용을 유지하기 위해 ChatData는 세션 관리 기능을 도입했습니다. 세션 ID를 쉽게 사용자 정의하고 프롬프트를 수정하여 쿼리를 해결할 때 ChatData를 안내 할 수 있습니다. 몇 번의 클릭만으로 매끄럽고 개인화 된 세션 상호 작용을 즐길 수 있습니다.
답변을 위해 MyScale로 구동되는 ChatData의 외부 지식 기반을 활용하는 것 외에도 자신의 파일을 업로드하고 맞춤형 지식 기반을 설정할 수 있습니다. 우리는이 목적을 위해 구조화되지 않은 API를 구현하여 문서에서 처리 된 텍스트 만 저장되어 데이터 개인 정보를 우선 순위를 정합니다.
결론적으로 ChatData를 사용하면 방대한 양의 데이터를 쉽게 탐색하여 필요한 것에 쉽게 액세스 할 수 있습니다. 당신이 연구원, 학생 또는 지식 애호가이든, Chatdata는 이전과는 다른 학문과 연구 문서를 탐색 할 수 있습니다. ChatData로 정보 검색의 진정한 잠재력을 잠금 해제하고 손끝에서 지식의 세계를 발견하십시오.
➡️에 들어가서 껴안는 얼굴에 채팅 데이터를 경험 하시겠습니까?
데이터베이스 자격 증명 :
MYSCALE_HOST = " msc-950b9f1f.us-east-1.aws.myscale.com "
MYSCALE_PORT = 443
MYSCALE_USER = " chatdata "
MYSCALE_PASSWORD = " myscale_rocks " wiki.WikipediaChatData는 또한 5 백만 개의 위키 페이지 미만의 약 3,600 만 개 단락을 포함하는 대형 지식 기반 인 Wikipedia에 액세스 할 수 있습니다. 지식 기반은 2022-12의 스냅 샷입니다.
이 테이블에서 공개 계정을 사용하여 여기에서 쿼리 할 수 있습니다.
CREATE TABLE wiki .Wikipedia (
-- Record ID
` id ` String,
-- Page title to this paragraph
` title ` String,
-- Paragraph text
` text ` String,
-- Page URL
` url ` String,
-- Wiki page ID
` wiki_id ` UInt64,
-- View statistics
` views ` Float32,
-- Paragraph ID
` paragraph_id ` UInt64,
-- Language ID
` langs ` UInt32,
-- Feature vector to this paragraph
` emb ` Array(Float32),
-- Vector Index
VECTOR INDEX emb_idx emb TYPE MSTG( ' metric_type=Cosine ' ),
CONSTRAINT emb_len CHECK length(emb) = 768 )
ENGINE = ReplacingMergeTree ORDER BY id SETTINGS index_granularity = 8192 default.ChatArXivChatData는 수백만 개의 논문을 지식 기반에 가져옵니다. 메타 데이터 정보가 포함 된 220 만 개의 논문을 수입했습니다.
id : 종이의 arxiv idabstract : 순위 기준으로 사용되는 논문의 초록 (습스 XL 포함)vector : Array(Float32)metadata : Langchain vectorstore 호환 열metadata.authors : 문자열 목록의 종이 저자metadata.abstract : 순위 기준으로 사용되는 논문의 초록 (습스 xl 포함)metadata.titles : 종이 제목metadata.categories : [ "CS.CV"와 같은 문자열 목록의 종이 카테고리.metadata.pubdate : ISO 8601 형성 문자열 의 논문 출판 날짜metadata.primary_category : arxiv에 의해 정의 된 문자열 의 용지의 기본 범주metadata.comment : 논문에 대한 추가 의견아래 열은 MyScale의 기본 열이며 SqlDatabase로만 사용할 수 있습니다.
authors : 문자열 목록의 논문 저자titles : 논문의 제목categories : [ "C.CV"와 같은 문자열 목록의 종이 카테고리]pubdate : Date32 데이터 유형 의 논문 출판 날짜 (빠른)primary_category : Arxiv에 의해 정의 된 문자열 의 용지의 기본 범주comment : 논문에 대한 추가 의견전체 테이블 스키마의 경우 Docs/SelfQuery.md의 테이블 생성 섹션을 참조하십시오.
이 데이터베이스를 langchain.chains.sql_database.base.SQLDatabaseChain 또는 langchain.retrievers.SQLDatabaseRetriever 와 함께 사용하려면 Docs/Vector-Sql.md의 데이터 준비 섹션 및 체인 제작 섹션에 대한 가이드를 따르십시오.
S3의 Parquet 파일에서
또는 MyScale 데이터베이스 를 서비스로 직접 사용하십시오
import clickhouse_connect
client = clickhouse_connect . get_client (
host = 'msc-950b9f1f.us-east-1.aws.myscale.com' ,
port = 443 ,
username = 'chatdata' ,
password = 'myscale_rocks'
)app/ cd app/python3 -m venv venv
source venv/bin/activatepython3 -m pip install -r requirements.txt # fill you OpenAI key in .streamlit/secrets.toml
cp . streamlit / secrets . example . toml . streamlit / secrets . toml
# start the app
python3 - m streamlit run app . py전체 기사를 읽으십시오
전체 기사를 읽으십시오


