Data Science Hacks
1.0.0
Data Science Hacks ถูกสร้างและบำรุงรักษาโดย Analytics Vidhya สำหรับชุมชนวิทยาศาสตร์ข้อมูล
มีเคล็ดลับเทคนิคและแฮ็กที่เกี่ยวข้องกับวิทยาศาสตร์ข้อมูลการเรียนรู้ของเครื่องจักร
แฮ็กเหล่านี้มีไว้สำหรับนักวิทยาศาสตร์ข้อมูลทั้งหมดที่นั่น ไม่สำคัญว่าคุณจะเป็นมือใหม่หรือมืออาชีพขั้นสูงแฮ็กเหล่านี้จะทำให้คุณมีประสิทธิภาพแน่นอน!
อย่าลังเลที่จะมีส่วนร่วมในการแฮ็กวิทยาศาสตร์ข้อมูลของคุณเองที่นี่ ตรวจสอบให้แน่ใจว่าแฮ็คของคุณเป็นไปตามแนวทางการบริจาค
ที่เก็บนี้เป็นส่วนหนึ่งของหลักสูตรฟรีโดย Analytics Vidhya หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับแฮ็กที่ยอดเยี่ยมเช่นนี้ให้ไปที่แฮ็กข้อมูลวิทยาศาสตร์เคล็ดลับและกลเม็ด
คุณจะแยกข้อมูลรูปภาพโดยตรงจาก Chrome ได้อย่างไรในคลิกเดียว ลองนึกภาพว่าคุณต้องการสร้างโครงการเรียนรู้ของเครื่องจักรของคุณเอง แต่คุณไม่มีข้อมูลเพียงพอมันกลายเป็นงานที่น่ากังวลไม่ได้คุณสามารถใช้ส่วนขยายทรัพยากรเพื่อดาวน์โหลดข้อมูลโดยตรง! มาดูกันเถอะ!
ขั้นตอน:
Pandas ใช้เป็นหนึ่งในฟังก์ชั่นที่ใช้กันมากที่สุดสำหรับการเล่นกับข้อมูลและสร้างตัวแปรใหม่ มันส่งคืนค่าบางอย่างหลังจากผ่านแต่ละแถว/คอลัมน์ของเฟรมข้อมูลด้วยฟังก์ชั่นบางอย่าง ฟังก์ชั่นอาจเป็นทั้งค่าเริ่มต้นหรือกำหนดโดยผู้ใช้
ช่วยในการเลือกชุดข้อมูลย่อยตามค่าของข้อมูลใน DataFrame
มันถูกใช้เพื่อสร้างสเปรดชีตสไตล์ MS Excel ระดับในตาราง Pivot จะถูกเก็บไว้ในวัตถุ Multiindex (ดัชนีลำดับชั้น) บนดัชนีและคอลัมน์ของ Dataframe ผลลัพธ์
ฟังก์ชั่น pd.crosstab () ใช้เพื่อรับ“ ความรู้สึก” เริ่มต้น (ดู) ของข้อมูล
มันถูกใช้เพื่อใช้ฟังก์ชั่นสตริงเวกเตอร์ในคอลัมน์ pandas dataframe สมมติว่าคุณต้องการแยกชื่อในคอลัมน์ DataFrame เป็นชื่อและชื่อสุดท้าย pandas.series.str พร้อมกับ split () สามารถใช้ในการทำงานนี้
นี่คือแฮ็คที่น่าสนใจในการแยกรหัสอีเมลที่มีอยู่ในข้อความยาวโดยใช้รหัส 2 บรรทัดใน Python โดยใช้นิพจน์ทั่วไป การแยกข้อมูลจากโพสต์และเว็บไซต์โซเชียลมีเดียได้กลายเป็นวิธีปฏิบัติทั่วไปในการวิเคราะห์ข้อมูล แต่บางครั้งเราก็ลองใช้วิธีที่ซับซ้อนเพื่อให้บรรลุสิ่งที่สามารถแก้ไขได้ง่ายโดยใช้เทคนิคที่เหมาะสม
หนึ่งในสมมติฐานที่สำคัญที่สุดในการถดถอยเชิงเส้นและโลจิสติกคือข้อมูลของเราจะต้องปฏิบัติตามการแจกแจงแบบปกติ แต่เราทุกคนรู้ว่ามักจะไม่ใช่กรณีในชีวิตจริง เรามักจะต้องแปลงข้อมูลของเราเป็นการกระจายปกติ/ เกาส์เซียน
การประมวลผลล่วงหน้าเป็นหนึ่งในขั้นตอนสำคัญสำหรับการปรับปรุงประสิทธิภาพของโมเดล หนึ่งในเหตุผลหลักสำหรับการประมวลผลข้อความล่วงหน้าคือการลบอักขระที่ไม่พึงประสงค์ออกจากข้อความเช่นเครื่องหมายวรรคตอนอิโมจิลิงก์และอื่น ๆ ที่ไม่จำเป็นสำหรับคำสั่งปัญหาของเรา
วิธีการข้อศอกใช้สำหรับการระบุค่า K ในเพื่อนบ้าน K-Nearest มันเป็นพล็อตข้อผิดพลาดที่ค่าที่แตกต่างกันของ K และเราเลือกค่า k ที่มีข้อผิดพลาดน้อยที่สุด!
ส่วนสำคัญของการวิเคราะห์ข้อมูลคือการประมวลผลล่วงหน้า หลายครั้งที่เราจำเป็นต้องขยายคุณสมบัติของเราเช่นในกรณีของ K-NN เราจำเป็นต้องขยายข้อมูลก่อนที่จะสร้างโมเดลหรืออื่น ๆ มันจะให้ผลลัพธ์ปลอม
ข้อมูลส่วนใหญ่ที่รวบรวมในวันนี้ถือตัวแปรวันที่และเวลา มีข้อมูลมากมายที่คุณสามารถแยกออกจากคุณสมบัติเหล่านี้และคุณสามารถใช้ประโยชน์ได้ในการวิเคราะห์ของคุณ!
แบบจำลอง Deeplearning มักจะต้องใช้ #DATA จำนวนมากสำหรับการฝึกอบรม แต่การรับข้อมูลจำนวนมากมาพร้อมกับความท้าทายของตัวเอง แทนที่จะใช้เวลาหลายวันในการรวบรวมข้อมูลด้วยตนเองคุณสามารถใช้เทคนิคการเพิ่มภาพ มันเป็นกระบวนการสร้างภาพใหม่ ภาพใหม่เหล่านี้ถูกสร้างขึ้นโดยใช้ภาพการฝึกอบรมที่มีอยู่และด้วยเหตุนี้เราไม่จำเป็นต้องรวบรวมด้วยตนเอง
Tokenization เป็นงานหลักในขณะที่สร้างคำศัพท์ HuggingFace เพิ่งสร้างห้องสมุดสำหรับ Tokenization ซึ่งให้การดำเนินการของโทเคนิเซอร์ที่ใช้มากที่สุดในปัจจุบันโดยมุ่งเน้นไปที่ประสิทธิภาพและความคล่องตัว คุณสมบัติที่สำคัญ: Ultra-Fast: พวกเขาสามารถเข้ารหัสข้อความ 1GB ใน ~ 20Sec บน CPU ของเซิร์ฟเวอร์มาตรฐาน
คุณสามารถแยกคุณสมบัติที่เป็นหมวดหมู่และตัวเลขลงใน DataFrames แยกในรหัสเพียง 1 บรรทัด! สามารถทำได้โดยใช้ฟังก์ชั่น select_dtypes
คุณต้องการทำการวิเคราะห์ข้อมูลอย่างรวดเร็วบน DataFrame ของคุณหรือไม่? คุณสามารถใช้การทำโปรไฟล์แพนด้าเพื่อสร้างรายงานโปรไฟล์ของชุดข้อมูลของคุณในรหัสเพียง 1 บรรทัด!
แปลง DataFrame รูปแบบกว้างเป็นรูปแบบ DataFrame แบบยาวในรหัสเพียง 1 บรรทัด! ใน pd.melt () มีการใช้คอลัมน์อีกหนึ่งคอลัมน์เป็นตัวระบุ "Unmelt the Data" ใช้ฟังก์ชัน Pivot ()
คุณรู้หรือไม่ว่าคุณจะได้รับประวัติของคำสั่งทั้งหมดที่ทำงานภายในสมุดบันทึก Jupyter ของคุณได้อย่างไร? ใช้ประวัติ %ฟังก์ชั่นเวทมนตร์ในตัวของ Jupyter Notebook! หมายเหตุ - แม้ว่าคุณจะตัดเซลล์ในสมุดบันทึกของคุณประวัติ %จะพิมพ์คำสั่งเหล่านั้นด้วย!
สร้างความร้อนบน Pandas Dataframe โดยใช้ Seoborn! มันช่วยให้คุณเข้าใจช่วงของค่าที่สมบูรณ์แบบที่เหลือบ
Scikit-Learn ได้เปิดตัวเวอร์ชัน 0.22.1 ที่เสถียรพร้อมคุณสมบัติใหม่และการแก้ไขข้อบกพร่อง หนึ่งฟังก์ชั่นใหม่คือฟังก์ชั่น plot_confusion_matrix ซึ่งสร้างเมทริกซ์ความสับสนที่ใช้งานง่ายและปรับแต่งได้มากสำหรับตัวจําแนกของคุณ เคล็ดลับโบนัส: คุณสามารถระบุรูปแบบของตัวเลขที่ปรากฏในกล่องโดยใช้พารามิเตอร์ values_format ('n' สำหรับตัวเลขทั้งหมด '.2f' สำหรับลอย ฯลฯ )
จะเป็นอย่างไรถ้าคุณเรียกใช้คำสั่งต่อไปนี้ในเซลล์เดียวของสมุดบันทึก Jupyter ของคุณ? df.shape df.head () แน่นอนว่ามันจะเป็นห้าแถวแรกของ dataframe ของคุณ เราสามารถรับเอาต์พุตของทั้งคำสั่งทำงานในเซลล์เดียวกันได้หรือไม่? คุณสามารถทำได้โดยใช้ InteractiveShell
พวกคุณส่วนใหญ่เคยได้ยินเกี่ยวกับ Library TQDM และคุณอาจใช้มันติดตามความคืบหน้าของการทำงานตลอดไปสำหรับลูป เวลาส่วนใหญ่ที่เราเขียนฟังก์ชั่นที่ซับซ้อนซึ่งซ้อนกันสำหรับลูป #TQDM อนุญาตให้ติดตามได้เช่นกัน นี่คือวิธีที่คุณสามารถติดตามลูปซ้อนกันโดยใช้ TDQM ใน Python
แบบจำลอง Deeplearning มักจะต้องใช้ข้อมูลจำนวนมากสำหรับการฝึกอบรม แต่การรับข้อมูลจำนวนมากมาพร้อมกับความท้าทายของตัวเอง แทนที่จะใช้เวลาหลายวันในการรวบรวมข้อมูลด้วยตนเองคุณสามารถใช้เทคนิคการเพิ่มภาพ มันเป็นกระบวนการสร้างภาพใหม่ ภาพใหม่เหล่านี้ถูกสร้างขึ้นโดยใช้ภาพการฝึกอบรมที่มีอยู่และด้วยเหตุนี้เราไม่จำเป็นต้องรวบรวมด้วยตนเอง
ธีม Jupyter เป็นวิธีที่ง่ายในการเปลี่ยนธีมฟอนต์และอีกมากมายในสมุดบันทึก Jupyter ของคุณ
ขั้นตอน -
conda install -c conda-forge jupyterthemes
pip install jupyterthemes
jt - l
jt -t chesterish
jt -r
ในการทำเช่นนี้เราใช้ธีม Jupyter มันเป็นวิธีที่ง่ายในการเปลี่ยนธีมฟอนต์และอีกมากมายในสมุดบันทึก Jupyter ของคุณ
ขั้นตอน -
ติดตั้ง JUPYTER -FEMES -
conda install -c conda-forge jupyterthemes
conda install -c pip install jupyterthemes
เปลี่ยนธีมความกว้างของเซลล์ความสูงของเซลล์
jt -t chesterish -cellw 100% lineh 170
คุณจะทำอย่างไรเมื่อคุณต้องการเปลี่ยนประเภทข้อมูลของคอลัมน์เป็น DateTime? เราสามารถทำได้โดยตรงในเวลาที่อ่านข้อมูลโดยใช้อาร์กิวเมนต์ parse_dates
คุณสามารถแบ่งปันสมุดบันทึก Jupyter ของคุณกับผู้ที่ไม่ใช่โปรแกรมเมอร์ได้อย่างง่ายดายและวิธีที่ดีที่สุดในการทำคือการใช้ Jupyter NbViewer เคล็ดลับมืออาชีพ - คุณสามารถใช้สารยึดเกาะเพื่อเรียกใช้รหัสจาก NBViewer บนเครื่องของคุณ!
คุณรู้วิธีพล็อตแผนผังการตัดสินใจในรหัสเพียง 1 บรรทัดหรือไม่? Sklearn ให้ฟังก์ชั่นง่าย ๆ plot_tree () เพื่อทำงานนี้ คุณสามารถปรับแต่งพารามิเตอร์ hyperparameters ตามความต้องการของคุณ
คุณรู้หรือไม่ว่าคุณสามารถกลับพจนานุกรมใน Python ได้อย่างไร? พจนานุกรมเป็นคอลเลกชันที่ไม่ได้เรียงลำดับเปลี่ยนแปลงและจัดทำดัชนี มีการใช้กันอย่างแพร่หลายในการเขียนโปรแกรมแบบวันต่อวันและงานการเรียนรู้ของเครื่อง
Cufflinks ผูกพล็อตโดยตรงกับ pandas dataframes! ดังนั้นคุณสามารถสร้างแผนภูมิแบบโต้ตอบได้โดยไม่ต้องยุ่งยากหรือมีรหัสยาว
การแฮ็คนี้เกี่ยวกับการบันทึกเนื้อหาของเซลล์เป็นไฟล์. py โดยใช้คำสั่ง Magic %% WriteFile จากนั้นเรียกใช้ไฟล์ในสมุดบันทึก Jupyter อื่นโดยใช้ Magic Command %Run Run Run
คุณสับสนในขณะที่พิมพ์โครงสร้างข้อมูลบางส่วนหรือไม่? ไม่ต้องกังวลมันเป็นเรื่องธรรมดามาก โมดูลการพิมพ์สวยเป็นวิธีที่ง่ายในการพิมพ์โครงสร้างข้อมูลด้วยวิธีที่น่าพอใจ!
รหัสนี้ช่วยให้คุณสามารถแปลงวันที่ของรูปแบบใด ๆ เป็นรูปแบบที่ระบุ หลายครั้งที่เราได้รับวันที่ของรูปแบบต่าง ๆ ในข้อมูลของเรา แฮ็คนี้จะช่วยให้คุณแปลงรูปแบบเหล่านั้นทั้งหมดเป็นรูปแบบที่ระบุ
หนึ่งในวิธีการเลือกคุณสมบัติคือการใช้แอตทริบิวต์ feature_importance_ ของตัวประมาณพื้นฐาน การใช้ฟังก์ชั่น SelectFroverel คุณสามารถระบุตัวประมาณและเกณฑ์สำหรับ Feature_importance_ แฮ็คนี้ใช้ 'หมายถึง' เป็นเกณฑ์ คุณสามารถปรับแต่งธรณีประตูเพื่อให้ได้ผลลัพธ์ที่ดีที่สุด เพื่อเรียนรู้เพิ่มเติมเยี่ยมชมเอกสาร
วิธีที่ง่ายที่สุดในการแปลงสตริงเป็นอักขระคืออะไร? นี่คือแฮ็คง่าย ๆ ที่มีประโยชน์ในขณะที่ทำงานกับข้อมูลข้อความ
ในขณะที่การสร้างรูปแบบการจำแนกรูปภาพโดยใช้การเรียนรู้อย่างลึกซึ้งจำเป็นต้องมีภาพทั้งหมดที่ควรมีขนาดเท่ากัน อย่างไรก็ตามเนื่องจากข้อมูลมาจากแหล่งข้อมูลที่แตกต่างกันรูปภาพอาจมีรูปร่างที่แตกต่างกัน ดังนั้นในการแปลงให้เป็นรูปร่างเดียวกันเราสามารถใช้ฟังก์ชั่น Resize จาก CV แบบเปิด แฮ็คนี้จะช่วยให้คุณแปลงภาพรูปร่างใด ๆ เป็นรูปร่างที่กำหนด
ต้องใช้เวลาในการดำเนินการบนแพนด้า dataframe ของคุณหรือไม่? Pandarallel เป็นเครื่องมือที่เรียบง่ายและมีประสิทธิภาพในการขนานการทำงานของ Pandas ในซีพียูที่มีอยู่ทั้งหมดของคุณ!
เครื่องกำเนิดไฟฟ้าให้ผลครั้งละหนึ่งรายการและสร้างขึ้นเมื่อต้องการเท่านั้น เครื่องกำเนิดไฟฟ้ามีประสิทธิภาพมากขึ้น แฮ็คนี้เปรียบเทียบนิพจน์เครื่องกำเนิดไฟฟ้ากับรายการความเข้าใจ
คุณหลีกเลี่ยง regex เพราะยากที่จะอ่านและเขียนและยุ่งยากในการได้รับใช่ไหม? แฮ็คนี้ช่วยให้คุณแก้ไข regex ได้ Regex101 เป็นตัวทดสอบ Regex ออนไลน์ดีบักเกอร์พร้อมไฮไลต์สำหรับ PHP, PCRE, Python, Golang และ JavaScript
บางครั้งข้อมูลอาจอยู่ในรูปแบบของรายการซ้อนกัน ตัวอย่างเช่นข้อมูลอาจเป็นบันทึกการทำธุรกรรมที่ชาญฉลาดสำหรับผลิตภัณฑ์เฉพาะ อย่างไรก็ตามคุณอาจต้องใช้ในมิติเดียวเท่านั้น การแฮ็คนี้จะช่วยให้คุณแบนรายการรายการลงในรายการเดียว
เรามักจะใช้คำสั่งพิมพ์เพื่อวัตถุประสงค์ในการดีบัก แฮ็คนี้จะช่วยให้คุณปิดงบพิมพ์ในส่วนเฉพาะของรหัสเพื่อให้การดีบักง่ายขึ้น
แฮ็คนี้จะช่วยให้คุณแยกเอกสาร PDF เดียวเป็นหลายหน้า
การแฮ็กนี้จะช่วยให้คุณรวมเอกสาร PDF หลายรายการไว้ในเอกสารเดียว แฮ็คนี้เป็นหน้าผกผันของแฮ็ค #42 หน้าเอกสาร PDF ที่ฉลาด
บางครั้งคุณอาจต้องใช้ฟังก์ชันการทำงานที่ไม่ได้รับโดยตรงจากเครื่องถ่ายภาพของ Keras คุณสามารถสร้างเสื้อคลุมรอบ ๆ ได้อย่างง่ายดายเพื่อให้เหมาะกับความต้องการของคุณ
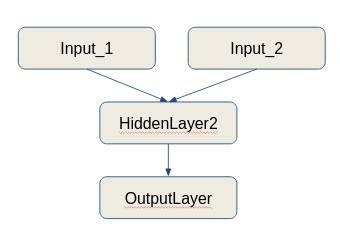
(เช่นเครือข่ายประสาทซึ่งรับข้อมูลจากแหล่งข้อมูลหลายแหล่งและทำการฝึกอบรมรวมกันในข้อมูลนี้) และคุณต้องการให้เครื่องกำเนิดข้อมูลควรจัดการการเตรียมข้อมูลได้ทันทีคุณสามารถสร้าง wrapper รอบคลาส imagedatagenerator เพื่อให้เอาต์พุตที่จำเป็น


