Data Science Hacks
1.0.0
O Data Science Hacks é criado e mantido pelo Analytics Vidhya para a comunidade de ciências de dados.
Inclui uma variedade de dicas, truques e hacks relacionados à ciência de dados, aprendizado de máquina
Esses hacks são para todos os cientistas de dados por aí. Não importa se você é um profissional iniciante ou avançado, esses hacks definitivamente o tornarão eficiente!
Sinta -se à vontade para contribuir com seus próprios hackers de ciência de dados aqui. Certifique -se de que seu hack siga as diretrizes de contribuição
Este repositório faz parte do curso gratuito da Analytics Vidhya. Para saber mais sobre tais impressionantes hacks, visite hacks, dicas e truques da ciência de dados
Como você pode extrair dados de imagem diretamente do Chrome em um clique? Imagine que você deseja criar seu próprio projeto de aprendizado de máquina, mas você não tem dados suficientes, ele se torna uma tarefa assustadora se preocupe, não você pode usar a extensão do Recursosever para baixar diretamente os dados! Vamos ver como!
Passos:
Os pandas aplicáveis são uma das funções mais usadas para brincar com dados e criar novas variáveis. Ele retorna algum valor depois de passar cada linha/coluna de um quadro de dados com alguma função. A função pode ser padrão ou definida pelo usuário.
Ajuda a selecionar o subconjunto de dados com base no valor dos dados no quadro de dados
É usado para criar planilha de estilo MS Excel. Os níveis na tabela pivô serão armazenados em objetos multiindex (índices hierárquicos) no índice e nas colunas do quadro de dados do resultado.
A função pd.crosStab () é usada para obter uma “sensação” inicial (visualização) dos dados.
É usado para aplicar funções de string vetorizadas em uma coluna Pandas Dataframe. Digamos que você queira dividir os nomes em uma coluna DataFrame no primeiro nome e sobrenome. Pandas.Series.str junto com Split () pode ser usado para executar esta tarefa.
Aqui está um hack interessante para extrair IDs de email presentes em longos peças de texto, apenas usando 2 linhas de código no Python usando expressões regulares. A extração de informações de postagens e sites de mídia social tornou -se uma prática comum na análise de dados, mas às vezes acabamos tentando métodos complicados para alcançar coisas que podem ser resolvidas facilmente usando a técnica correta.
Uma das suposições mais importantes na regressão linear e logística é que nossos dados devem seguir uma distribuição normal, mas todos sabemos que geralmente não é o caso na vida real. Geralmente, precisamos transformar nossos dados em distribuição normal/ gaussiana.
O pré -processamento é uma das etapas principais para melhorar o desempenho de um modelo. Uma das principais razões para o pré -processamento de texto é remover caracteres indesejados do texto como pontuação, emojis, links e assim por diante, que não são necessários para a nossa declaração de problemas.
O método do cotovelo é usado para identificar o valor de k em vizinhos mais parecidos. É um gráfico de erros em diferentes valores de K e selecionamos o valor K com menor erro!
Uma parte importante da análise de dados é o pré -processamento. Muitas vezes, precisamos dimensionar nossos recursos, como no caso da K-NN, sempre precisamos dimensionar os dados antes de criar o modelo, ou então eles fornecerão resultados espúrios.
A maioria dos dados coletados hoje, mantenha as variáveis de data e hora. Há muitas informações que você pode extrair desses recursos e pode utilizá -las em sua análise!
Os modelos DEEplearning geralmente exigem muito #Data para treinamento. Mas adquirir grandes quantidades de dados vem com seus próprios desafios. Em vez de gastar dias coletando manualmente dados, você pode usar as técnicas de aumento da imagem. É o processo de geração de novas imagens. Essas novas imagens são geradas usando as imagens de treinamento existentes e, portanto, não precisamos coletá -las manualmente.
A tokenização é a principal tarefa ao criar o vocabulário. A Huggingface criou recentemente uma biblioteca para tokenização que fornece uma implementação dos tokenizadores mais usados de hoje, com foco no desempenho e na versatilidade. Principais recursos: Ultra-Fast: eles podem codificar 1 GB de texto em ~ 20seg na CPU de um servidor padrão
Você pode extrair recursos categóricos e numéricos em quadros de dados separados em apenas 1 linha de código! Isso pode ser feito usando a função select_dtypes.
Deseja executar uma análise rápida de dados em seu quadro de dados? Você pode usar o perfil do Pandas para gerar relatório de perfil do seu conjunto de dados em apenas 1 linha de código!
Converta o quadro de dados de formato amplo em DataFrame de formato longo em apenas 1 linha de código! Em pd.melt (), mais uma colunas é usada como identificadores. "UNNORD os dados", use a função pivot ()
Você sabe como pode obter o histórico de todos os comandos em execução no seu notebook Jupyter? Use %History, a função mágica interna do Jupyter Notebook! NOTA - Mesmo se você tiver cortado as células em seu notebook, o %History também imprimirá esses comandos!
Crie mapa de calor no quadro de dados de pandas usando o SeaBorn! Ajuda você a entender a gama completa de valores em um vislumbre.
A Scikit-Learn lançou sua versão estável 0.22.1 com novos recursos e correções de bugs. Uma nova função é a função plot_confusion_matrix que gera uma matriz de confusão extremamente intuitiva e personalizável para o seu classificador. Dica de bônus: você pode especificar o formato dos números que aparecem nas caixas usando o parâmetro valores_format ('n' para números inteiros, '.2f' para flutuação, etc)
Qual será a saída se você executar os seguintes comandos em uma única célula do seu notebook Jupyter? df.Shape df.head () Claro, serão as primeiras cinco linhas do seu quadro de dados. Podemos obter a saída de ambos o comando executado na mesma célula? Você pode fazer isso usando o interativeShell.
A maioria de vocês já ouviu falar do TQDM da biblioteca e pode estar usando o progresso de correr para sempre em loops. Na maioria das vezes, escrevemos funções complexas tendo aninhadas para loops. #tqdm permite rastrear isso também. Aqui está como você pode rastrear os loops aninhados usando o TDQM no Python.
Os modelos de deeplearning geralmente exigem muitos dados para treinamento. Mas adquirir grandes quantidades de dados vem com seus próprios desafios. Em vez de gastar dias coletando manualmente dados, você pode usar as técnicas de aumento da imagem. É o processo de geração de novas imagens. Essas novas imagens são geradas usando as imagens de treinamento existentes e, portanto, não precisamos coletá -las manualmente.
O Jupyter-Themes fornece uma maneira fácil de mudar o tema, as fontes e muito mais no seu notebook Jupyter.
Passos -
conda install -c conda-forge jupyterthemes
pip install jupyterthemes
jt - l
jt -t chesterish
jt -r
Para fazer isso, usamos os temas Jupyter, ele fornece uma maneira fácil de mudar o tema, as fontes e muito mais no seu notebook Jupyter.
Passos -
Instale Jupyter -Themas -
conda install -c conda-forge jupyterthemes
conda install -c pip install jupyterthemes
Mude o tema, largura da célula, altura da célula
jt -t chesterish -cellw 100% lineh 170
O que você faz quando precisa alterar o tipo de dados de uma coluna para o DateTime? Podemos fazer isso diretamente no momento da leitura de dados usando o argumento parse_dates.
Você pode compartilhar seu notebook Jupyter com não programadores com muita facilidade e a melhor maneira de fazer isso é usando o Jupyter NBViewer. Dica profissional - você pode usar o fichário para executar o código do NBViewer em sua máquina!
Você sabe como plotar uma árvore de decisão em apenas 1 linha de código? A Sklearn fornece uma função simples plot_tree () para realizar esta tarefa. Você pode ajustar os hiperparâmetros de acordo com seus requisitos.
Você sabe como pode inverter um dicionário em Python? O dicionário é uma coleção que não é ordenada, mutável e indexada. É amplamente utilizado na programação diária e nas tarefas de aprendizado de máquina.
Os abotoados se ligam diretamente diretamente aos quadros de dados do Pandas! Portanto, você pode fazer gráficos interativos sem problemas ou códigos longos.
Este hack é sobre salvar o conteúdo de uma célula em um arquivo .py usando o comando mágico %% writefile e depois executar o arquivo em outro notebook Jupyter usando o comando mágico %run
Você está ficando confuso ao imprimir algumas das estruturas de dados? Não se preocupe, é muito comum. O módulo de impressão bonita fornece uma maneira fácil de imprimir as estruturas de dados de uma maneira visualmente agradável!
Este código permite que você converta a data de qualquer formato em um formato especificado. Muitas vezes, recebemos datas de vários formatos em nossos dados. Este hack ajudará você a converter todos esses formatos em um formato especificado.
Uma das maneiras de executar a seleção de recursos é usando o atributo rache_importance_ dos estimadores básicos. Usando a função SelectFrodmodel, você pode especificar o estimador e o limite para o recurso_importance_, este hack usa 'significa' como o limite. Você pode ajustar o limite para obter os melhores resultados. Para saber mais, visite a documentação
Qual poderia ser a maneira mais fácil de converter uma string em caracteres? Aqui está um hack simples que é útil enquanto trabalha com dados de texto
Ao criar um modelo de classificação de imagem usando aprendizado profundo, é necessário que todas as imagens sejam do mesmo tamanho. No entanto, como os dados vêm de fontes diferentes, as imagens podem ter formas diferentes. Portanto, para convertê -los na mesma forma, podemos usar a função de redimensionamento do CV aberto. Este hack ajudará você a converter as imagens de qualquer forma em uma forma especificada.
Leva tempo para executar operações em seu quadro de dados de pandas? O Pandarallelal é uma ferramenta simples e eficiente para paralelizar as operações de pandas em todas as suas CPUs disponíveis!
O gerador produz um item de cada vez e os gera apenas quando estiver em demanda. Os geradores são muito mais eficientes em memória. Este hack compara as expressões geradoras com as compreensões da lista.
Você evita Regex porque eles são difíceis de ler e escrever e também complicados de acertar? Este hack ajuda a corrigir seu regex. Regex101 é um testador de regex online, depurador com destaque para PHP, PCRE, Python, Golang e JavaScript
Às vezes, os dados podem estar na forma de lista aninhada. Por exemplo, os dados podem ser registros de transações em data para um produto específico. No entanto, você pode precisar apenas em uma única dimensão. Este hack ajudará você a achatar a lista de listas em uma única lista.
Frequentemente usamos declarações de impressão para fins de depuração. Esse hack ajudará você a desativar as instruções de impressão em uma seção específica do código, para facilitar a depuração.
Este hack ajudará você a dividir um único documento em PDF em várias páginas.
Este hack ajudará você a combinar vários documentos em PDF em um único documento. Este hack é o inverso do hack
Às vezes, você precisaria de uma funcionalidade que não seja fornecida diretamente pelo ImagerAgenerator de Keras. Você pode criar facilmente um invólucro ao seu redor para atender às suas necessidades.
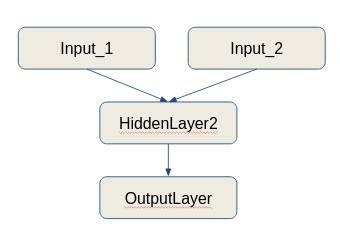
(ou seja, uma rede neural que recebe a entrada de várias fontes de dados e faz um treinamento combinado sobre esses dados) e você deseja que o gerador de dados possa lidar com a preparação de dados em tempo real, você pode criar uma pulseira em torno da classe IMAGEDATAGenerator para fornecer a saída necessária. Este notebook explica uma solução simples para esta USecase.


