Data Science Hacks
1.0.0
Data Science Hacks wird von Analytics Vidhya für die Data Science Community erstellt und gepflegt.
Es enthält eine Vielzahl von Tipps, Tricks und Hacks im Zusammenhang mit Datenwissenschaft und maschinellem Lernen
Diese Hacks sind für alle Datenwissenschaftler da draußen gedacht. Es spielt keine Rolle, ob Sie ein Anfänger oder ein fortgeschrittener Fachmann sind, diese Hacks werden Sie auf jeden Fall effizient machen!
Fühlen Sie sich frei, hier Ihre eigenen Data Science -Hacks beizutragen. Stellen Sie sicher, dass Ihr Hack den Beitragsrichtlinien befolgt
Dieses Repository ist Teil des freien Kurs von Analytics Vidhya. Um mehr von solch großartigen Hacks zu erfahren, besuchen Sie Data Science -Hacks, Tipps und Tricks
Wie können Sie Bilddaten in einem Klick direkt aus Chrome extrahieren? Stellen Sie sich vor, Sie möchten Ihr eigenes Projekt für maschinelles Lernen erstellen, aber Sie haben nicht genügend Daten. Es wird zu einer entmutigenden Aufgabe, die sich nicht mit der Erweiterung der Ressourcenverwandte befassen können, um Daten direkt herunterzuladen! Mal sehen wie!
Schritte:
Pandas anwenden ist eine der am häufigsten verwendeten Funktionen für das Spielen mit Daten und das Erstellen neuer Variablen. Es gibt einen Wert zurück, nachdem jede Zeile/Spalte eines Datenrahmens mit einer bestimmten Funktion bestanden hat. Die Funktion kann sowohl standardmäßig als auch benutzerdefiniert sein.
Es hilft bei der Auswahl der Datenuntergruppe von Daten basierend auf dem Wert der Daten im Datenrahmen
Es wird verwendet, um die Tabelle im MS -Excel -Stil zu erstellen. Die Ebenen in der Pivot -Tabelle werden in Multiindex -Objekten (hierarchischen Indizes) im Index und in den Spalten des Ergebnisdatenrahmens gespeichert.
Pd.CroSStab () -Funktion wird verwendet, um ein anfängliches „Gefühl“ (Ansicht) der Daten zu erhalten.
Es wird verwendet, um vektorisierte String -Funktionen in einer Spalte von Pandas DataFrame anzuwenden. Nehmen wir an, Sie möchten die Namen in einer DataFrame -Spalte in den Vornamen und den Nachnamen aufteilen. Pandas.Series.str zusammen mit Split () kann verwendet werden, um diese Aufgabe auszuführen.
Hier ist ein interessanter Hack, um E -Mail -IDs zu extrahieren, die in langen Textteilen vorhanden sind, indem Sie nur 2 Codezeilen in Python unter Verwendung regelmäßiger Ausdrücke verwenden. Das Extrahieren von Informationen aus Social -Media -Posts und Websites ist zu einer gängigen Praxis in der Datenanalyse geworden, aber manchmal versuchen wir komplizierte Methoden, um Dinge zu erreichen, die mit der richtigen Technik leicht gelöst werden können.
Eine der wichtigsten Annahmen in der linearen und logistischen Regression ist, dass unsere Daten einer Normalverteilung folgen müssen, aber wir alle wissen, dass dies im wirklichen Leben normalerweise nicht der Fall ist. Wir müssen unsere Daten oft in eine normale/ gaußsche Verteilung umwandeln.
Die Vorverarbeitung ist einer der wichtigsten Schritte zur Verbesserung der Leistung eines Modells. Einer der Hauptgründe für die Vorbereitung von Text besteht darin, unerwünschte Zeichen aus Text wie Interpunktion, Emojis, Links usw. zu entfernen, über die für unsere Problemanweisung nicht erforderlich ist.
Die Ellbogenmethode wird verwendet, um den Wert von k in k-nearsten Nachbarn zu identifizieren. Es ist ein Fehler von Fehlern bei verschiedenen Werten von k und wir wählen den k -Wert mit geringsten Fehler aus!
Ein wichtiger Bestandteil der Datenanalyse ist die Vorverarbeitung. Oft müssen wir unsere Funktionen wie im Fall von K-NN skalieren, die wir die Daten stets vor dem Erstellen von Modells skalieren müssen, oder es wird falsche Ergebnisse liefern.
Die meisten heute gesammelten Daten halten die Datums- und Uhrzeitvariablen. Es gibt viele Informationen, die Sie aus diesen Funktionen extrahieren können, und Sie können sie in Ihrer Analyse verwenden!
DeepLearning -Modelle erfordern normalerweise viel #Data für das Training. Der Erwerb von massiven Datenmengen ist jedoch mit eigenen Herausforderungen verbunden. Anstatt Tage manuell zu sammeln, können Sie Bildvergrößerungstechniken verwenden. Es ist der Prozess, neue Bilder zu generieren. Diese neuen Bilder werden unter Verwendung der vorhandenen Trainingsbilder generiert und müssen sie daher nicht manuell sammeln.
Tokenisierung ist die Hauptaufgabe beim Aufbau des Wortschatzes. Huggingface hat kürzlich eine Bibliothek für Tokenisierung erstellt, die eine Implementierung der am häufigsten verwendeten Tokenisierer bietet und sich auf Leistung und Vielseitigkeit konzentriert. Schlüsselmerkmale: Ultra-SPAST: Sie können 1 GB Text in ~ 20 Sekunden auf der CPU eines Standardservers codieren
Sie können kategorische und numerische Merkmale in separate Datenrahmen in nur 1 Codezeile extrahieren! Dies kann mit der Funktion Select_dtypes erfolgen.
Möchten Sie eine schnelle Datenanalyse in Ihrem Datenrahmen durchführen? Sie können Pandas Profiling verwenden, um einen Profilbericht Ihres Datensatzes in nur 1 Codezeile zu generieren!
Konvertieren Sie den Datenframe mit breitem Formular in Long Form DataFrame in nur 1 Codezeile! In Pd.Melt () werden weitere Spalten als Kennungen verwendet. "Die Daten entlarven", verwenden Sie Pivot () -Funktion
Wissen Sie, wie Sie die Geschichte aller Befehle in Ihrem Jupyter -Notizbuch erhalten können? Verwenden Sie %History, Jupyter Notebooks integrierte magische Funktion! Hinweis - Auch wenn Sie die Zellen in Ihrem Notebook geschnitten haben, druckt %History auch diese Befehle!
Erstellen Sie mit Seeborn Wärme auf Pandas DataFrame! Es hilft Ihnen, den gesamten Wertebereich auf einen Blick zu verstehen.
Scikit-Learn hat seine stabile 0,22.1-Version mit neuen Funktionen und Fehlerbehebungen veröffentlicht. Eine neue Funktion ist die Funktion Plot_confusion_Matrix, die eine extrem intuitive und anpassbare Verwirrungsmatrix für Ihren Klassifikator erzeugt. Bonus -Tipp: Sie können das Format der in den Feldern angezeigten Zahlen mit dem Parameter Values_Format ('n' für ganze Zahlen, '.2f' für float usw. angeben ('n'
Was wird die Ausgabe sein, wenn Sie die folgenden Befehle in einer einzelnen Zelle Ihres Jupyter -Notizbuchs ausführen? DF.SHAPE DF.HEAD () Natürlich werden es die ersten fünf Zeilen Ihres Datenrahmens sein. Können wir sowohl den Befehlslauf in derselben Zelle ausgeben? Sie können es mit InteractiveShell tun.
Die meisten von Ihnen haben von der Bibliothek TQDM gehört, und Sie verwenden sie möglicherweise den Fortschritt des Forever Running for Loops. Meistens schreiben wir komplexe Funktionen, die sich für Schleifen verschachtelt haben. #TQDM ermöglicht auch das Nachverfolgung. So können Sie die verschachtelten Schleifen mit TDQM in Python verfolgen.
DeepLearning -Modelle erfordern normalerweise viele Daten für das Training. Der Erwerb von massiven Datenmengen ist jedoch mit eigenen Herausforderungen verbunden. Anstatt Tage manuell zu sammeln, können Sie Bildvergrößerungstechniken verwenden. Es ist der Prozess, neue Bilder zu generieren. Diese neuen Bilder werden unter Verwendung der vorhandenen Trainingsbilder generiert und müssen sie daher nicht manuell sammeln.
Jupyter-Themes bietet eine einfache Möglichkeit, Themen, Schriftarten und vieles mehr in Ihrem Jupyter-Notizbuch zu ändern.
Schritte -
conda install -c conda-forge jupyterthemes
pip install jupyterthemes
jt - l
jt -t chesterish
jt -r
Dazu verwenden wir Jupyter-Themen. Es bietet eine einfache Möglichkeit, Themen, Schriftarten und vieles mehr in Ihrem Jupyter-Notizbuch zu ändern.
Schritte -
Installieren Sie Jupyter -Themen -
conda install -c conda-forge jupyterthemes
conda install -c pip install jupyterthemes
Ändern Sie das Thema, die Zellbreite, die Zellhöhe
jt -t chesterish -cellw 100% lineh 170
Was tun Sie, wenn Sie den Datentyp einer Spalte in DateTime ändern müssen? Wir können dies zum Zeitpunkt des Lesens von Daten mithilfe von Parse_dates -Argument direkt tun.
Sie können Ihr Jupyter-Notizbuch mit Nichtprogrammierern sehr einfach teilen und der beste Weg, dies zu tun, besteht darin, Jupyter NBViewer zu verwenden. Pro -Tipp - Mit Binder können Sie den Code von NBViewer auf Ihrem Computer ausführen!
Wissen Sie, wie Sie einen Entscheidungsbaum in nur 1 Codezeile zeichnen können? Sklearn bietet eine einfache Funktion plot_tree (), um diese Aufgabe zu erledigen. Sie können die Hyperparameter gemäß Ihren Anforderungen optimieren.
Wissen Sie, wie Sie ein Wörterbuch in Python umkehren können? Dictionary ist eine Sammlung, die nicht ordnungsgemäß, veränderlich und indiziert ist. Es wird in der täglichen Programmierung und maschinellem Lernaufgaben weit verbreitet.
Manschettenknöpfe binden Plotly direkt an Pandas DataFrames! Daher können Sie interaktive Diagramme ohne Probleme oder lange Codes erstellen.
In diesem Hack geht es darum, Inhalte einer Zelle in einer .py -Datei mithilfe des Magic Command %% WriteFile zu speichern und dann die Datei in einem anderen Jupyter -Notizbuch mit dem Magic Command %Run zu führen
Werden Sie verwirrt, während Sie einige Datenstrukturen drucken? Sorge nicht, es ist sehr häufig. Das Print-Print-Modul bietet eine einfache Möglichkeit, die Datenstrukturen visuell ansprechend zu drucken!
Mit diesem Code können Sie das Datum eines beliebigen Formats in ein bestimmtes Format umwandeln. Oft erhalten wir Daten verschiedener Formate in unseren Daten. Dieser Hack hilft Ihnen, all diese Formate in ein bestimmtes Format umzuwandeln.
Eine der Möglichkeiten zur Auswahl der Feature -Auswahl ist die Verwendung von Feature_Importance_ -Attribut der Basisschätzer. Mithilfe der SelectFrorMrom -Funktion können Sie den Schätzer und den Schwellenwert für feature_importance_ angeben. Dieser Hack verwendet "Mittelwert" als Schwellenwert. Sie können den Schwellenwert optimieren, um optimale Ergebnisse zu erzielen. Weitere Informationen finden Sie in der Dokumentation
Was könnte der einfachste Weg sein, eine Zeichenfolge in Zeichen umzuwandeln? Hier ist ein einfacher Hack, der bei der Arbeit mit Textdaten nützlich ist
Beim Erstellen eines Bildklassifizierungsmodells unter Verwendung von Deep Learning ist es erforderlich, dass alle Bilder gleich groß sind. Da die Daten jedoch aus verschiedenen Quellen stammen, können Bilder unterschiedliche Formen haben. Um sie in die gleiche Form zu konvertieren, können wir die Größe der Größenrate von offenem Lebenslauf verwenden. Dieser Hack hilft Ihnen dabei, die Bilder einer beliebigen Form in eine bestimmte Form umzuwandeln.
Nächsten Sie sich Zeit, um Operationen auf Ihrem Pandas -Datenframe auszuführen? Pandarallel ist ein einfaches und effizientes Werkzeug, mit dem Pandas -Operationen für alle verfügbaren CPUs parallelisiert werden können!
Der Generator liefert jeweils jeweils einen Artikel und generiert sie nur, wenn sie gefragt sind. Generatoren sind viel speichereffizienter. Dieser Hack vergleicht Generatorausdrücke mit List -Verständnissen.
Vermeiden Sie Regex, weil sie schwer zu lesen und zu schreiben und schwierig zu schreiben? Dieser Hack hilft Ihnen, Ihren Regex korrekt zu machen. REGEX101 ist ein Online -Regex -Tester, Debugger mit Marke für PHP, PCRE, Python, Golang und JavaScript
Manchmal können die Daten in Form einer verschachtelten Liste erfolgen. Beispielsweise können die Daten für ein bestimmtes Produkt Datumsübertragungsaufzeichnungen sein. Möglicherweise benötigen Sie jedoch nur in einer einzigen Dimension. Dieser Hack hilft Ihnen, die Liste der Listen in eine einzige Liste zu verflachen.
Wir verwenden häufig Druckanweisungen zum Debugging -Zweck. Dieser Hack hilft Ihnen dabei, die Druckanweisungen in einem bestimmten Abschnitt des Codes auszuschalten, damit das Debuggen erleichtert wird.
Dieser Hack hilft Ihnen, ein einzelnes PDF -Dokument in mehrere Seiten aufzuteilen.
Dieser Hack hilft Ihnen dabei, mehrere PDF -Dokumente in ein einzelnes Dokument zu kombinieren. Dieser Hack ist die Umkehrung des Hacks #42 Split PDF-Dokumentseiten- und Weise
Manchmal benötigen Sie eine Funktionalität, die nicht direkt von Keras 'Imagingatagenerator bereitgestellt wird. Sie können problemlos einen Wrapper um ihn erstellen, um Ihren Anforderungen zu entsprechen.
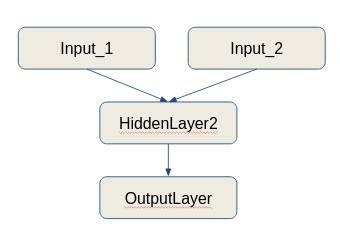
(dh ein neuronales Netzwerk, das Eingaben aus mehreren Datenquellen nimmt und ein kombiniertes Training für diese Daten durchführt.


