Data Science Hacks
1.0.0
Data Science Hacks est créé et maintenu par Analytics Vidhya pour la communauté des sciences des données.
Il comprend une variété de conseils, astuces et hacks liés à la science des données, à l'apprentissage automatique
Ces hacks sont destinés à tous les scientifiques des données. Peu importe si vous êtes un débutant ou un professionnel avancé, ces hacks vous rendront certainement efficace!
N'hésitez pas à contribuer vos propres hacks de science des données ici. Assurez-vous que votre hack suit les directives de contribution
Ce référentiel fait partie du cours gratuit par analytique vidhya. Pour en savoir plus sur de tels hacks impressionnants, visitez les hacks, les conseils et les astuces de la science des données
Comment pouvez-vous extraire les données d'image directement à partir de Chrome en un seul clic? Imaginez que vous souhaitez faire votre propre projet d'apprentissage automatique mais vous n'avez pas assez de données, cela devient une tâche intimidante, non pas utiliser l'extension Resourcesaver pour télécharger directement les données! Voyons comment!
Mesures:
Pandas s'applique est l'une des fonctions les plus couramment utilisées pour jouer avec les données et créer de nouvelles variables. Il renvoie une certaine valeur après avoir passé chaque ligne / colonne d'une trame de données avec une fonction. La fonction peut être à la fois par défaut ou définie par l'utilisateur.
Il aide à sélectionner le sous-ensemble de données en fonction de la valeur des données dans le dataframe
Il est utilisé pour créer une feuille de calcul de style MS Excel. Les niveaux de la table PIVOT seront stockés dans des objets multi-index (index hiérarchiques) sur l'index et les colonnes du résultat DataFrame.
La fonction pd.crosstab () est utilisée pour obtenir une «sensation» (vue »initiale des données.
Il est utilisé pour appliquer les fonctions de chaîne vectorielles sur une colonne Pandas DataFrame. Disons que vous souhaitez diviser les noms dans une colonne DataFrame en prénom et nom de famille. pandas.series.str ainsi que Split () peuvent être utilisés pour effectuer cette tâche.
Voici un piratage intéressant pour extraire les identifiants de messagerie présents dans de longs morceaux de texte en utilisant simplement 2 lignes de code dans Python en utilisant des expressions régulières. L'extraction des informations des publications et des sites Web des médias sociaux est devenue une pratique courante dans l'analyse des données, mais parfois nous finissons par essayer des méthodes compliquées pour réaliser des choses qui peuvent être résolues facilement en utilisant la bonne technique.
L'une des hypothèses les plus importantes de régression linéaire et logistique est que nos données doivent suivre une distribution normale, mais nous savons tous que ce n'est généralement pas le cas dans la vie réelle. Nous devons souvent transformer nos données en distribution normale / gaussienne.
Le prétraitement est l'une des étapes clés pour améliorer les performances d'un modèle. L'une des principales raisons du prétraitement du texte est de supprimer les caractères indésirables du texte comme la ponctuation, les emojis, les liens, etc., ce qui n'est pas requis pour notre déclaration de problème.
La méthode du coude est utilisée pour identifier la valeur de K dans les voisins K-Dearest. Il s'agit d'un tracé d'erreurs à différentes valeurs de K et nous sélectionnons la valeur k ayant le moins d'erreur!
Une partie importante de l'analyse des données consiste à prétraiter. Plusieurs fois, nous devons évoluer nos fonctionnalités comme dans le cas de K-NN, nous devons toujours évoluer les données avant de construire le modèle, sinon cela donnera des résultats faux.
La plupart des données collectées aujourd'hui, contiennent les variables de date et d'heure. Il y a beaucoup d'informations que vous pouvez extraire de ces fonctionnalités et vous pouvez l'utiliser dans votre analyse!
Les modèles Deeplearning nécessitent généralement beaucoup de #DATA pour la formation. Mais l'acquisition de quantités massives de données s'accompagne de ses propres défis. Au lieu de passer des jours à collecter manuellement des données, vous pouvez utiliser des techniques d'augmentation d'image. C'est le processus de génération de nouvelles images. Ces nouvelles images sont générées à l'aide des images d'entraînement existantes et nous n'avons donc pas à les collecter manuellement.
La tokenisation est la tâche principale lors de la construction du vocabulaire. HuggingFace a récemment créé une bibliothèque de tokenisation qui fournit une implémentation des tokenisers les plus utilisés d'aujourd'hui, en mettant l'accent sur les performances et la polyvalence. Caractéristiques clés: ultra-rapide: ils peuvent coder 1 Go de texte en ~ 20 secondes sur le processeur d'un serveur standard
Vous pouvez extraire des fonctionnalités catégorielles et numériques dans des dataframes séparés dans seulement 1 ligne de code! Cela peut être fait à l'aide de la fonction SELECT_DTYPES.
Voulez-vous effectuer une analyse rapide des données sur votre dataframe? Vous pouvez utiliser le profilage Pandas pour générer un rapport de profil de votre ensemble de données dans seulement 1 ligne de code!
Convertissez les données larges de DataFrame en longue forme DataFrame en seulement 1 ligne de code! Dans pd.melt (), une autre colonne est utilisée comme identifiants. "Définissez les données", utilisez la fonction pivot ()
Savez-vous comment vous pouvez obtenir l'historique de toutes les commandes exécutant dans votre cahier Jupyter? Utilisez% History, la fonction magique intégrée de Jupyter Notebook! Remarque - Même si vous avez coupé les cellules dans votre ordinateur portable,% History imprimera également ces commandes!
Créez une carte thermique sur Pandas DataFrame en utilisant SeaBorn! Il vous aide à comprendre la plage complète des valeurs à un aperçu.
Scikit-Learn a publié sa version stable 0.22.1 avec de nouvelles fonctionnalités et des corrections de bogues. Une nouvelle fonction est la fonction Plot_confusion_Matrix qui génère une matrice de confusion extrêmement intuitive et personnalisable pour votre classificateur. Conseil de bonus: vous pouvez spécifier le format des nombres apparaissant dans les cases à l'aide du paramètre VALEUR ('n' pour les nombres entiers, .2f 'pour float, etc.)
Quelle sera la sortie si vous exécutez les commandes suivantes dans une seule cellule de votre cahier Jupyter? Df.shape df.head () Il sera bien sûr les cinq premières lignes de votre dataframe. Pouvons-nous obtenir la sortie de la commande exécutée dans la même cellule? Vous pouvez le faire à l'aide d'interactiveshell.
La plupart d'entre vous ont entendu parler de la bibliothèque TQDM et vous pourriez l'utiliser, suivez la progression de la course pour toujours pour les boucles. La plupart du temps, nous écrivons des fonctions complexes ayant imbriqué des boucles. #TQDM permet également de suivre cela. Voici comment vous pouvez suivre les boucles imbriquées en utilisant TDQM dans Python.
Les modèles Deeplearning nécessitent généralement beaucoup de données pour la formation. Mais l'acquisition de quantités massives de données s'accompagne de ses propres défis. Au lieu de passer des jours à collecter manuellement des données, vous pouvez utiliser des techniques d'augmentation d'image. C'est le processus de génération de nouvelles images. Ces nouvelles images sont générées à l'aide des images d'entraînement existantes et nous n'avons donc pas à les collecter manuellement.
Jupyter-thems offre un moyen facile de changer de thème, de polices et bien plus encore dans votre cahier de jupyter.
Étapes -
conda install -c conda-forge jupyterthemes
pip install jupyterthemes
jt - l
jt -t chesterish
jt -r
Pour ce faire, nous utilisons des thèmes de jupyter, il offre un moyen facile de changer de thème, de polices et bien plus encore dans votre cahier de jupyter.
Étapes -
Installez les thèmes Jupyter -
conda install -c conda-forge jupyterthemes
conda install -c pip install jupyterthemes
Changer le thème, la largeur des cellules, la hauteur des cellules
jt -t chesterish -cellw 100% lineh 170
Que faites-vous lorsque vous devez modifier le type de données d'une colonne en DateTime? Nous pouvons le faire directement au moment de la lecture des données à l'aide de l'argument PARSE_DATES.
Vous pouvez partager votre cahier Jupyter avec des non-programmeurs très facilement et la meilleure façon de le faire est d'utiliser Jupyter NBViewer. Conseil de pro - Vous pouvez utiliser Binder pour exécuter le code de NBViewer sur votre machine!
Savez-vous comment tracer un arbre de décision en seulement 1 ligne de code? Sklearn fournit un tracé de fonction simple_tree () pour effectuer cette tâche. Vous pouvez modifier les hyperparamètres selon vos besoins.
Savez-vous comment vous pouvez inverser un dictionnaire à Python? Le dictionnaire est une collection non ordonnée, modifiable et indexée. Il est largement utilisé dans la programmation quotidienne et les tâches d'apprentissage automatique.
Les boutons de manchette se lient directement à Pandas DataFrames! Par conséquent, vous pouvez faire des graphiques interactifs sans tracas ou codes longs.
Ce hack vise à enregistrer le contenu d'une cellule dans un fichier .py en utilisant la commande magique %% WriteFile, puis en exécutant le fichier dans un autre ordinateur portable Jupyter en utilisant la commande magique%
Vous confondez-vous tout en imprimant certaines des structures de données? Ne vous inquiétez pas, c'est très courant. Le module Prettrial fournit un moyen facile d'imprimer les structures de données de manière visuellement agréable!
Ce code vous permet de convertir la date de tout format en format spécifié. Plusieurs fois, nous recevons des dates de divers formats dans nos données. Ce hack vous aidera à convertir tous ces formats en format spécifié.
L'une des façons d'effectuer la sélection des fonctionnalités est d'utiliser l'attribut de fonctionnalité_importance_ des estimateurs de base. À l'aide de la fonction SELECTFROGLODEL, vous pouvez spécifier l'estimateur et le seuil pour fonctionnant_importance_, ce hack utilise «moyenne» comme seuil. Vous pouvez modifier le seuil pour obtenir des résultats optimaux. Pour en savoir plus, visitez la documentation
Quel pourrait être le moyen le plus simple de convertir une chaîne en caractères? Voici un simple hack qui est utile tout en travaillant avec des données de texte
Lors de la création d'un modèle de classification d'image à l'aide d'un apprentissage en profondeur, il est nécessaire que toutes les images soient de même taille. Cependant, comme les données proviennent de différentes sources, les images peuvent avoir différentes formes. Ainsi, pour les convertir en même forme, nous pouvons utiliser la fonction de redimensionnement à partir de CV ouvert. Ce hack vous aidera à convertir les images de toute forme en forme spécifiée.
Cela prend-il du temps pour effectuer des opérations sur votre Pandas DataFrame? Pandarallel est un outil simple et efficace pour paralléliser les opérations de Pandas sur tous vos processeurs disponibles!
Le générateur fournit un élément à la fois et les génère uniquement lorsqu'il est en demande. Les générateurs sont beaucoup plus efficaces en mémoire. Ce hack compare les expressions de générateur avec les compréhensions de la liste.
Évitez-vous le regex, car ils sont difficiles à lire et à écrire ainsi que délicats pour bien faire? Ce piratage vous aide à obtenir votre regex correct. Regex101 est un testeur regex en ligne, débogueur avec mise en évidence pour PHP, PCRE, Python, Golang et JavaScript
Parfois, les données peuvent prendre la forme d'une liste imbriquée. Par exemple, les données peuvent être des enregistrements de transaction dattes pour un produit particulier. Cependant, vous n'aurez peut-être besoin que dans une seule dimension. Ce hack vous aidera à aplatir la liste des listes en une seule liste.
Nous utilisons souvent des instructions d'impression à des fins de débogage. Ce hack vous aidera à désactiver les instructions d'impression dans une section particulière du code afin de faciliter le débogage.
Ce hack vous aidera à diviser un seul document PDF en plusieurs pages.
Ce hack vous aidera à combiner plusieurs documents PDF en un seul document. Ce hack est l'inverse de Hack # 42 Split PDF Document Page en termes
Parfois, vous auriez besoin d'une fonctionnalité qui n'est pas directement fournie par IMageDatagenerator de Keras. Vous pouvez facilement créer un emballage autour de lui pour répondre à vos besoins.
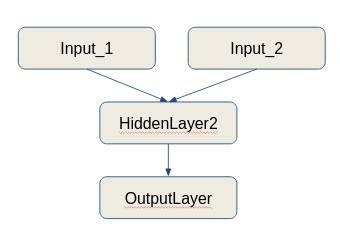
(c'est-à-dire un réseau de neurones qui prend les entrées de plusieurs sources de données et fait une formation combinée sur ces données), et vous souhaitez que le générateur de données puisse être en mesure de gérer la préparation des données à la volée, vous pouvez créer un wrapper autour de la classe IMageDatagenerator pour donner la sortie requise. Ce cahier explique une solution simple à cette USECase.


