Data Science Hacks
1.0.0
Data Science Hacksは、Data Science CommunityのAnalytics Vidhyaによって作成および維持されています。
データサイエンス、機械学習に関連するさまざまなヒント、トリック、ハッキングが含まれています
これらのハックは、そこにあるすべてのデータサイエンティスト向けです。あなたが初心者であろうと高度な専門家であるかどうかは関係ありません。これらのハッキングは間違いなく効率的になります!
ここで独自のデータサイエンスハックをお気軽に提供してください。ハックが貢献ガイドラインに従っていることを確認してください
このリポジトリは、Analytics Vidhyaによる無料コースの一部です。このような素晴らしいハッキングの詳細については、データサイエンスハック、ヒント、トリックをご覧ください
ワンクリックでChromeから直接画像データを抽出するにはどうすればよいですか?独自の機械学習プロジェクトを作成したいのですが、十分なデータがないことを想像してください。リソースアバー拡張機能を使用してデータを直接ダウンロードできるのではなく、困難なタスクになります。どのように見てみましょう!
ステップ:
Pandas Applyは、データで再生し、新しい変数を作成するために最も一般的に使用される関数の1つです。データフレームの各行/列を何らかの関数で渡した後、ある程度の値を返します。関数は、デフォルトまたはユーザー定義の両方にすることができます。
データフレーム内のデータの値に基づいてデータのサブセットを選択するのに役立ちます
MS Excelスタイルのスプレッドシートを作成するために使用されます。ピボットテーブルのレベルは、結果データフレームのインデックスと列にマルチインデックスオブジェクト(階層インデックス)に保存されます。
PD.CROSSTAB()関数は、データの最初の「感触」(ビュー)を取得するために使用されます。
Pandas DataFrame列にベクトル化された文字列関数を適用するために使用されます。データフレーム列の名前を名と姓に分割するとしましょう。 pandas.series.strとsplit()を使用して、このタスクを実行できます。
これは、正規表現を使用してPythonで2行のコードを使用するだけで、長いテキストに存在する電子メールIDを抽出するための興味深いハックです。ソーシャルメディアの投稿やウェブサイトから情報を抽出することは、データ分析の一般的な慣行となっていますが、適切な手法を使用して簡単に解決できるものを実現するための複雑な方法を試してみることになります。
線形およびロジスティック回帰の最も重要な仮定の1つは、データが正規分布に従う必要があることですが、実際の生活では通常そうではないことを知っています。多くの場合、データを通常/ガウス分布に変換する必要があります。
前処理は、モデルのパフォーマンスを改善するための重要なステップの1つです。テキストの前処理の主な理由の1つは、問題のステートメントには必要ない句読点、絵文字、リンクなどのテキストから不要な文字を削除することです。
肘法は、K-nearest NeighborsのKの値を識別するために使用されます。これは、kの異なる値でのエラーのプロットであり、最小エラーのK値を選択します!
データ分析の重要な部分は、前処理することです。多くの場合、K-NNの場合のように機能をスケーリングする必要があります。モデルを構築する前に常にデータをスケーリングする必要があります。
今日収集されたデータのほとんどは、日付と時刻の変数を保持します。これらの機能から抽出できる多くの情報があり、分析でそれを利用できます!
ディープラーニングモデルには、通常、トレーニングには多くの#DATAが必要です。しかし、膨大な量のデータを取得するには、独自の課題があります。データを手動で収集するのではなく、画像の増強技術を利用できます。これは、新しい画像を生成するプロセスです。これらの新しい画像は既存のトレーニング画像を使用して生成されるため、手動で収集する必要はありません。
トークン化は、語彙を構築する際の主要なタスクです。 Huggingfaceは最近、パフォーマンスと汎用性に焦点を当てた、今日で最も使用されているトークンザーの実装を提供するトークン化のライブラリを作成しました。主な機能:超高速:標準サーバーのCPUで1GBのテキストを〜20秒でエンコードできます
わずか1行のコードで、カテゴリと数値の機能を別々のデータフレームに抽出できます!これは、select_dtypes関数を使用して実行できます。
データフレームで簡単なデータ分析を実行したいですか? Pandasプロファイリングを使用して、わずか1行のコードでデータセットのプロファイルレポートを生成できます。
ワイドフォームのデータフレームをわずか1行のコードで長いフォームデータフレームに変換します! pd.melt()では、もう1つの列が識別子として使用されます。 「データを解除する」、Pivot()関数を使用します
Jupyterノートブック内で実行されているすべてのコマンドの歴史をどのように得ることができるか知っていますか? Jupyter Notebookの組み込みマジック機能、履歴を使用してください!メモ - ノートブックでセルをカットした場合でも、%履歴もこれらのコマンドを印刷します!
Seabornを使用してPandas DataFrameでヒートマップを作成してください!それはあなたが垣間見るだけで価値の完全な範囲を理解するのに役立ちます。
Scikit-Learnは、新しい機能とバグ修正を備えた安定した0.22.1バージョンをリリースしました。新しい関数の1つは、分類器に非常に直感的でカスタマイズ可能な混乱マトリックスを生成するplot_confusion_matrix関数です。ボーナスのヒント:Value_Formatパラメーター(整数の 'n'、 '.2f'などを使用してボックスに表示される数字の形式を指定できます。
Jupyterノートブックの単一セルで次のコマンドを実行すると、出力はどうなりますか? df.shape df.head()ofcourseデータフレームの最初の5行になります。同じセルで実行されるコマンドの両方の出力を取得できますか? InteractiveShellを使用して行うことができます。
あなたのほとんどは、ライブラリTQDMについて聞いたことがありますが、それを使用しているかもしれません。ほとんどの場合、ループ用にネストされた複雑な関数を書きます。 #TQDMもそれを追跡できます。 PythonのTDQMを使用して、ネストされたループを追跡する方法は次のとおりです。
ディープラーニングモデルは通常、トレーニングのために多くのデータを必要とします。しかし、膨大な量のデータを取得するには、独自の課題があります。データを手動で収集するのではなく、画像の増強技術を利用できます。これは、新しい画像を生成するプロセスです。これらの新しい画像は既存のトレーニング画像を使用して生成されるため、手動で収集する必要はありません。
Jupyter-Themesは、Jupyterノートブックでテーマ、フォントなどを変更する簡単な方法を提供します。
ステップ -
conda install -c conda-forge jupyterthemes
pip install jupyterthemes
jt - l
jt -t chesterish
jt -r
これを行うために、Jupyter-Themesを使用すると、Jupyterノートブックでテーマ、フォントなどを簡単に変更する方法が提供されます。
ステップ -
Jupyter -Themesをインストール -
conda install -c conda-forge jupyterthemes
conda install -c pip install jupyterthemes
テーマ、セルの幅、セルの高さを変更します
jt -t chesterish -cellw 100% lineh 170
列のデータ型をDateTimeに変更する必要がある場合はどうしますか? parse_dates引数を使用してデータを読み取る時点でこれを直接行うことができます。
Jupyterノートブックを非プログラマーと非常に簡単に共有できます。それを行う最良の方法は、Jupyter nbviewerを使用することです。プロのヒント - バインダーを使用して、マシンのnbviewerからコードを実行できます!
わずか1行のコードで決定ツリーをプロットする方法を知っていますか? Sklearnは、このタスクを実行するための単純な関数plot_tree()を提供します。要件に応じて、ハイパーパラメーターを調整できます。
Pythonで辞書を反転する方法を知っていますか?辞書は、順序付けられておらず、変更可能で、インデックスが施されたコレクションです。日々のプログラミングや機械学習タスクで広く使用されています。
CufflinksはPlotlyをPandas DataFramesに直接結合します!したがって、手間や長いコードなしでインタラクティブなチャートを作成できます。
このハックは、魔法コマンド%% writeFileを使用してセルのコンテンツを.pyファイルに保存し、魔法のコマンド%runを使用して別のjupyterノートブックでファイルを実行することです
データ構造の一部を印刷しているときに混乱していますか?心配しないでください、それは非常に一般的です。プリティプリントモジュールは、視覚的に心地よい方法でデータ構造を簡単に印刷する簡単な方法を提供します!
このコードを使用すると、任意のフォーマットの日付を指定された形式に変換できます。多くの場合、データにさまざまな形式の日付を受け取ります。このハックは、これらすべての形式を指定された形式に変換するのに役立ちます。
機能選択を実行する方法の1つは、ベース推定器のfeature_importance_属性を使用することです。 SelectFromMoMtel関数を使用すると、feature_importance_の推定器としきい値を指定できます。このハックは、しきい値として「平均」を使用します。しきい値を微調整して、最適な結果を得ることができます。詳細については、ドキュメントをご覧ください
文字列をキャラクターに変換する最も簡単な方法は何ですか?これがテキストデータの使用中に役立つ簡単なハックです
深い学習を使用して画像分類モデルを構築する際、すべての画像が同じサイズである必要があります。ただし、データはさまざまなソースから来るため、画像の形状は異なる場合があります。したがって、それらを同じ形状に変換するために、開いたCVのサイズ変更関数を使用できます。このハックは、任意の形状の画像を指定された形状に変換するのに役立ちます。
Pandasデータフレームで操作を実行するのに時間がかかりますか? Pandar Allelは、利用可能なすべてのCPUでパンダ操作を並列化するためのシンプルで効率的なツールです!
ジェネレーターは一度に1つのアイテムを生成し、需要の場合にのみ生成します。ジェネレーターは、メモリ効率がはるかに高くなります。このハックは、ジェネレーターの式をリストの概念と比較します。
regexは、読み書きが難しいだけでなく、正しくするのが難しいので、正規表現を避けていますか?このハックは、あなたがあなたの正規表現を正しくするのに役立ちます。 Regex101は、PHP、PCRE、Python、Golang、JavaScriptのハイライトを備えたオンラインRegexテスター、デバッガーです
データがネストされたリストの形である場合があります。たとえば、データは特定の製品の日付ごとのトランザクションレコードにすることができます。ただし、単一の次元でのみ必要な場合があります。このハックは、リストのリストを単一のリストにフラット化するのに役立ちます。
多くの場合、デバッグの目的で印刷ステートメントを使用します。このハックは、コードの特定のセクションの印刷ステートメントをオフにするのに役立ち、デバッグが容易になります。
このハックは、単一のPDFドキュメントを複数のページに分割するのに役立ちます。
このハックは、複数のPDFドキュメントを単一のドキュメントに結合するのに役立ちます。このハックは、ハックの逆です#42スプリットPDFドキュメントページごとに
KerasのImagedatageneratorによって直接提供されない機能が必要になる場合があります。あなたのニーズに合わせて、その周りにラッパーを簡単に作成できます。
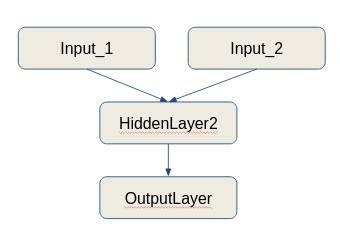
(つまり、複数のデータソースから入力し、このデータの合計トレーニングを行うニューラルネットワーク)、およびデータジェネレーターがその場でのデータの準備を処理できるようにする必要があります。イメイジタゲネレータークラスの周りにラッパーを作成して、必要な出力を提供できます。


