Real Agents
v1.0.0
中文 | ภาษาอังกฤษ
ตัวแทนจริงเป็นกรอบการวางแผนที่รวมวิธีการปัญญาประดิษฐ์แบบดั้งเดิมเข้ากับแบบจำลองภาษาขนาดใหญ่ (LLM) และเหมาะสำหรับตัวแทน AI กำเนิด มันมีปลั๊กอินความสามัคคีและโครงการสาธิต
เหตุผลในการพัฒนาโครงการนี้คือการทำวิทยานิพนธ์ระดับปริญญาตรี (การออกแบบ) ของฉันให้สำเร็จและความสนใจส่วนตัวของฉันในเกม AI
แบบจำลองภาษาขนาดใหญ่สามารถดำเนินการให้เหตุผลการตัดสินใจและปัญหาการวางแผน เรามีเฟรมเวิร์กเอเจนต์ผู้ใหญ่มากมายเพื่อช่วยให้ผู้ใช้ใช้งานเครื่องมือบางอย่างเช่นการค้นหาเอกสารและการสร้างหน้าเว็บ
แต่ฉันคิดว่ามีปัญหาหลายอย่างเมื่อนำไปใช้ในเกม:
ยากต่อการดีบัก: หากการดำเนินการพฤติกรรมขึ้นอยู่กับ LLM มันจะนำมาซึ่งการใช้โทเค็นที่ยากต่อการประเมินและวิธีจัดการกับข้อยกเว้นของตัวแทน
การตอบสนองช้า: ตัวอย่างเช่นหากสถานะในเกมเปลี่ยนแปลงเราอาจจำเป็นต้องสร้างคำและบริบทที่รวดเร็วขึ้นใหม่ หากคุณปล่อยให้ NPC สร้างแผนเช่นใน Generative AI มันจะต้องใช้เวลามากในการรอ LLM ที่จะสร้างขึ้นซึ่งไม่สามารถนำไปใช้กับเกมเรียลไทม์ได้
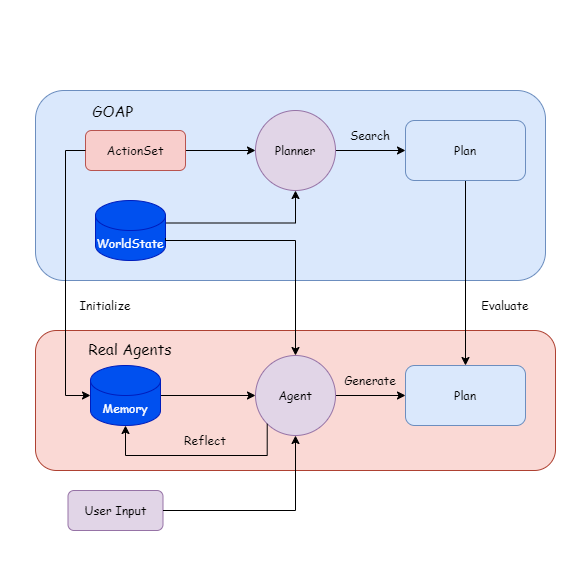
ดังนั้นฉันจึงพยายามสร้าง LLM ตามวิธี AI แบบดั้งเดิมทำให้ตัวแทนสามารถวางแผนได้โดยการทำความเข้าใจความสัมพันธ์ระหว่างปริมาณและพฤติกรรมของรัฐในขณะที่การดำเนินการพฤติกรรมและการตรวจสอบสถานะเสร็จสิ้นโดยโปรแกรมและตัวแทนจะกระตุ้นการดำเนินการเมื่อมีการเปลี่ยนแปลงสถานะ -
{
"dependencies" : {
"com.cysharp.unitask" : " https://github.com/Cysharp/UniTask.git?path=src/UniTask/Assets/Plugins/UniTask " ,
"com.huggingface.sharp-transformers" : " https://github.com/AkiKurisu/sharp-transformers.git " ,
"com.kurisu.akiai" : " https://github.com/AkiKurisu/AkiAI.git " ,
"com.kurisu.akibt" : " https://github.com/AkiKurisu/AkiBT.git " ,
"com.kurisu.akiframework" : " https://github.com/AkiKurisu/AkiFramework.git " ,
"com.kurisu.akigoap" : " https://github.com/AkiKurisu/AkiGOAP.git " ,
"com.kurisu.unichat" : " https://github.com/AkiKurisu/UniChat.git "
}
}ดาวน์โหลดเวอร์ชัน Windows Build จากหน้าเผยแพร่
ก่อนอื่นใช้ LLM เพื่อติดฉลากการกระทำและเป้าหมายตามข้อมูล GOAP
ให้ตัวแทนและนักวางแผนสร้างและแผนการค้นหาตามรัฐโลก (WorldStates) ในช่วงรันไทม์
เปรียบเทียบแผน LLM สะท้อนและวนซ้ำในหน่วยความจำ
จากนั้นคุณสามารถปิดการวางแผนและปล่อยให้ตัวแทนสร้างแผน
ก่อนอื่นผู้พัฒนาจะกำหนดชุดการดำเนินการที่ดำเนินการได้ ( ActionSet ) และชุดเป้าหมาย ( GoalSet )
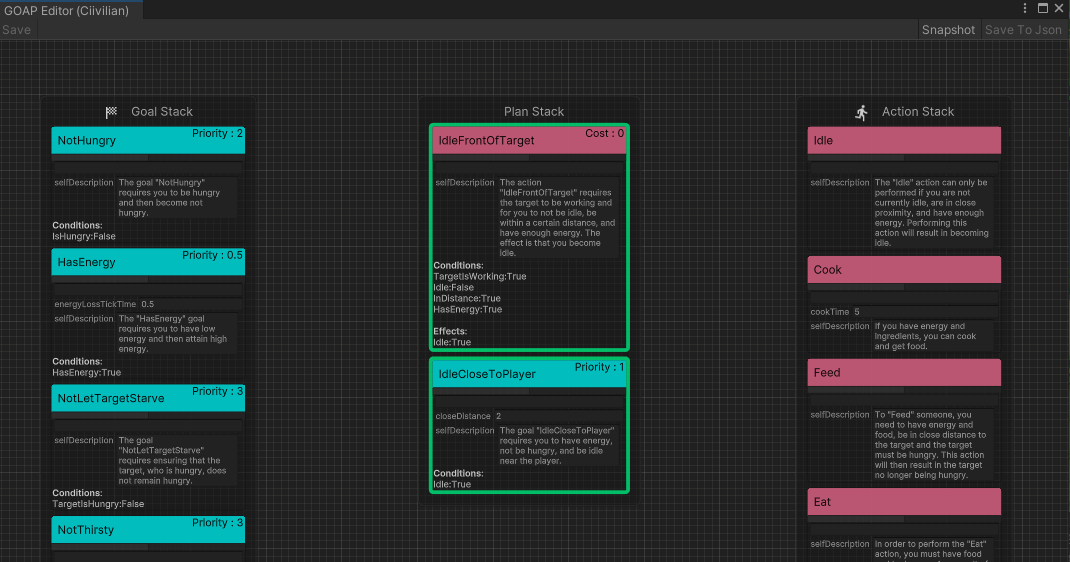
พฤติกรรมแต่ละอย่างขึ้นอยู่กับกฎของ GOAP และมี Precondition ล่วงหน้าและ Effect เอฟเฟกต์
public class Eat : DescriptiveTask
{
protected sealed override void SetupDerived ( )
{
Preconditions [ States . HasFood ] = true ;
Preconditions [ States . IsHungry ] = true ;
}
protected sealed override void SetupEffects ( )
{
Effects [ States . IsHungry ] = false ;
}
} ประการที่สอง Action ดำเนินการป้อนข้อมูลไปยังแบบจำลองภาษาขนาดใหญ่สรุปเป็นภาษาธรรมชาติเป็นความประทับใจเริ่มต้นของตัวแทนของพฤติกรรม ( InitialImpression ) และหน่วยความจำระยะยาว ( Summary ) และปล่อยให้หน่วยความจำระยะสั้น ( Comments ) ว่างเปล่า
"Name" : " Cook " ,
"InitialImpression" : " To Cook, you need to have energy and ingredients, and as a result, you will have food. " ,
"Summary" : " Latest summary " ,
"Comments" : [
" " ,
" " ,
" " ,
" " ,
" "
] Goal อินพุตไปยังรูปแบบภาษาขนาดใหญ่และให้ LLM สร้างภาษาธรรมชาติเป็นคำอธิบาย ( Explanation ) สำหรับการใช้เป้าหมาย และรวมเข้าด้วยกันเพื่อรับการตีความของชุด G.
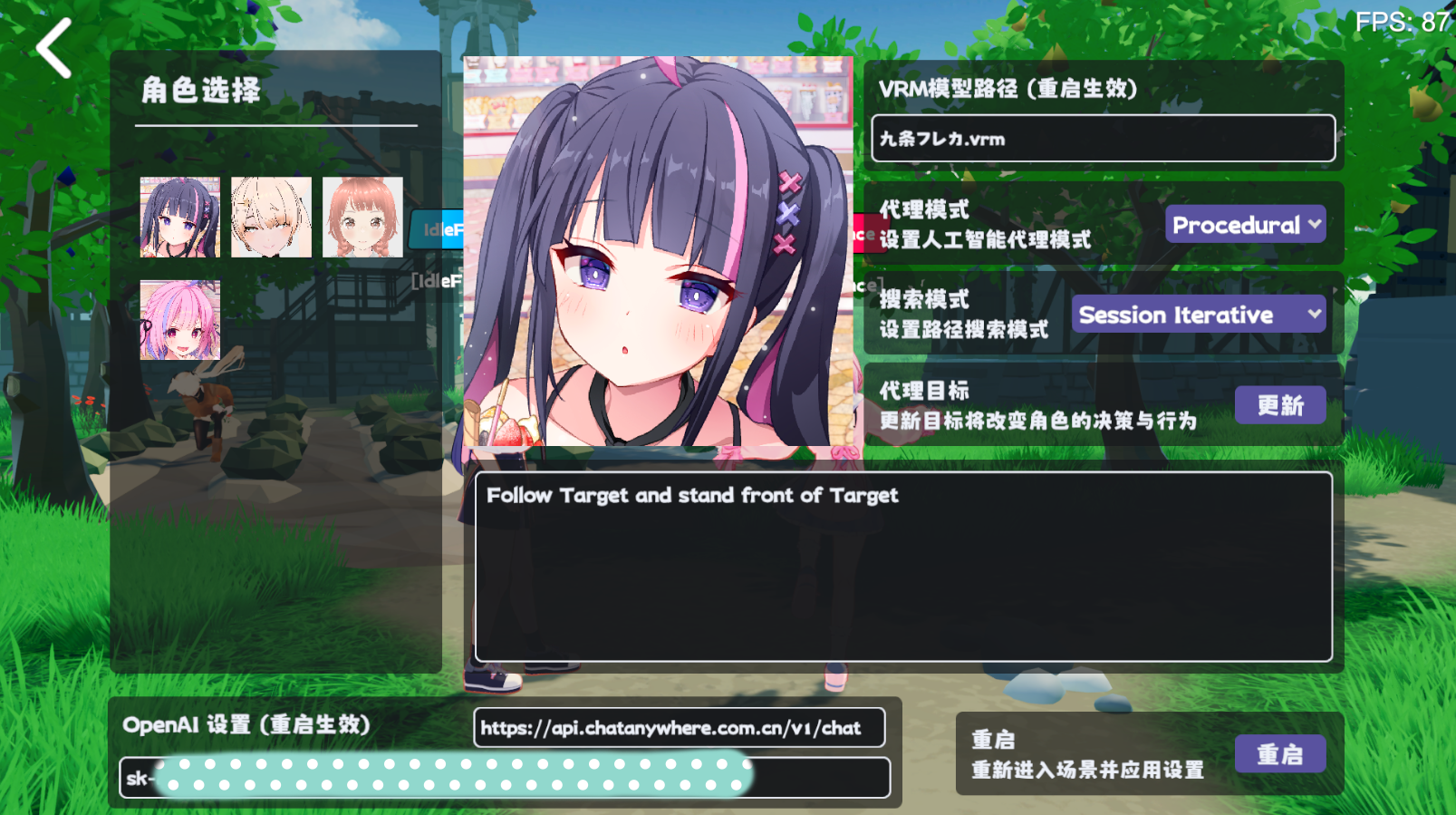
ในตัวแทนจริงคุณสามารถคลิก Self Description โดยตรงในบรรณาธิการของ RealAgentSet เพื่อสร้างข้อมูลข้างต้น
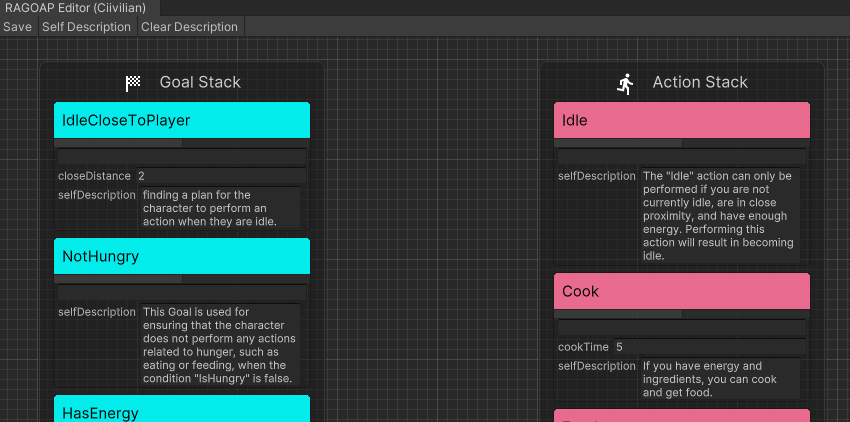
ปรับโหมดตัวแทน ( AgentMode ) และตั้งค่าเป็นการ Training
Plan ทำงานในเวลานี้ถูกค้นหาโดย Planner และตัวแทนสร้าง Plan ในเวลาเดียวกัน หากมีพฤติกรรมที่แตกต่างกัน LLM จะสะท้อนเหตุผลและสร้าง Comment เป็นหน่วยความจำระยะสั้น
เมื่อหน่วยความจำระยะสั้นถึงเกณฑ์ตัวแทนจะสรุปมันขึ้นอยู่กับความประทับใจเริ่มต้นความคิดเห็นและหน่วยความจำระยะยาวปัจจุบันเขียนทับหน่วยความจำระยะยาวและวนซ้ำ
ขึ้นอยู่กับเป้าหมายการป้อนข้อมูลจากภายนอกเหตุผลของตัวแทนในเวลาจริงในพื้นที่เสมือนจริง
LLM ค้นหา Plan เหมาะสมตามความทรงจำของตัวเองของแต่ละพฤติกรรม เนื่องจากไม่มีการเปรียบเทียบนักวางแผนจึงกำหนดว่า Plan จะเป็นไปได้หรือไม่ หากไม่เป็นเช่นนั้น LLM จะสร้าง ( Comment ) และฉีดเข้าไปในหน่วยความจำ
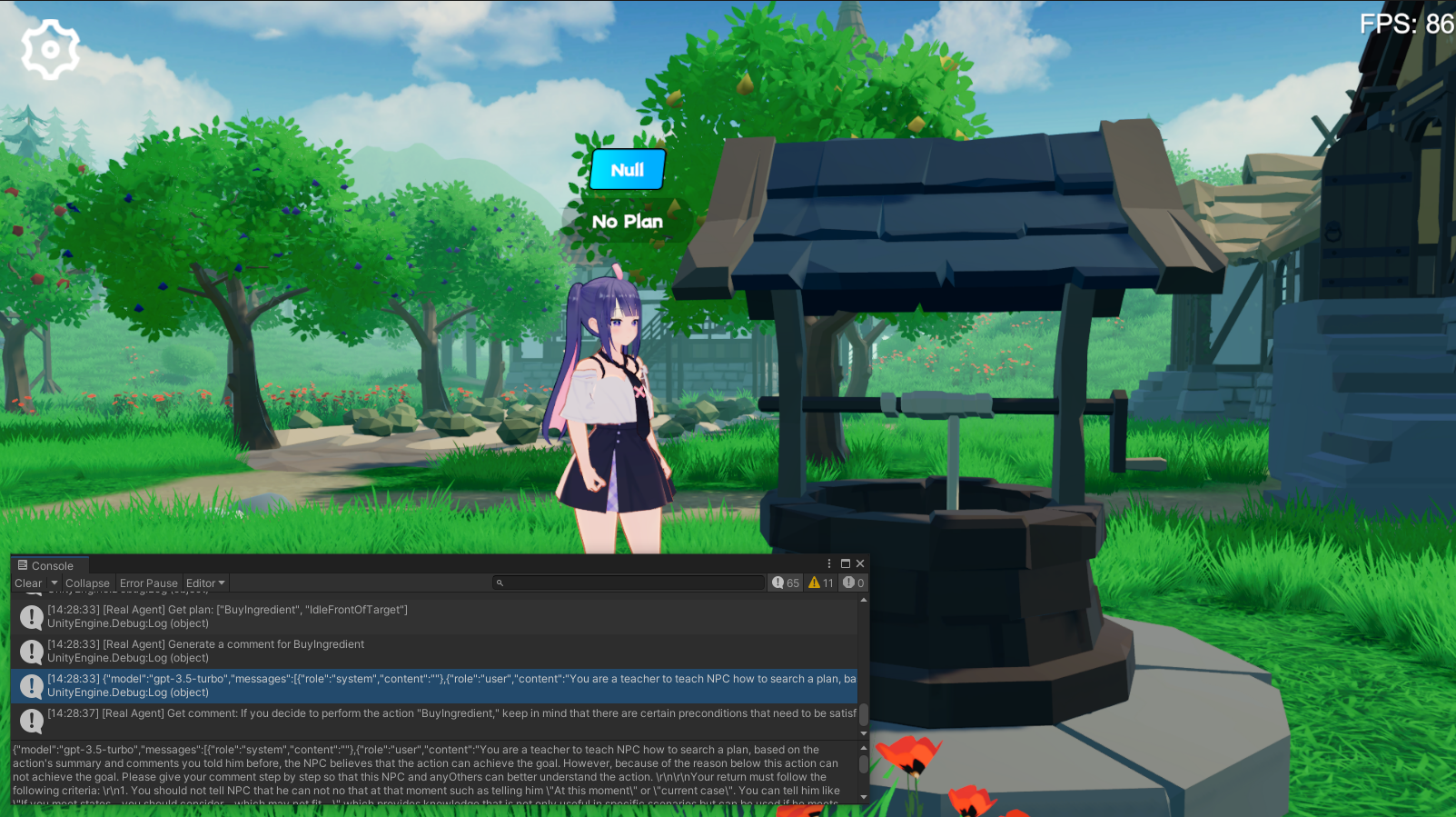
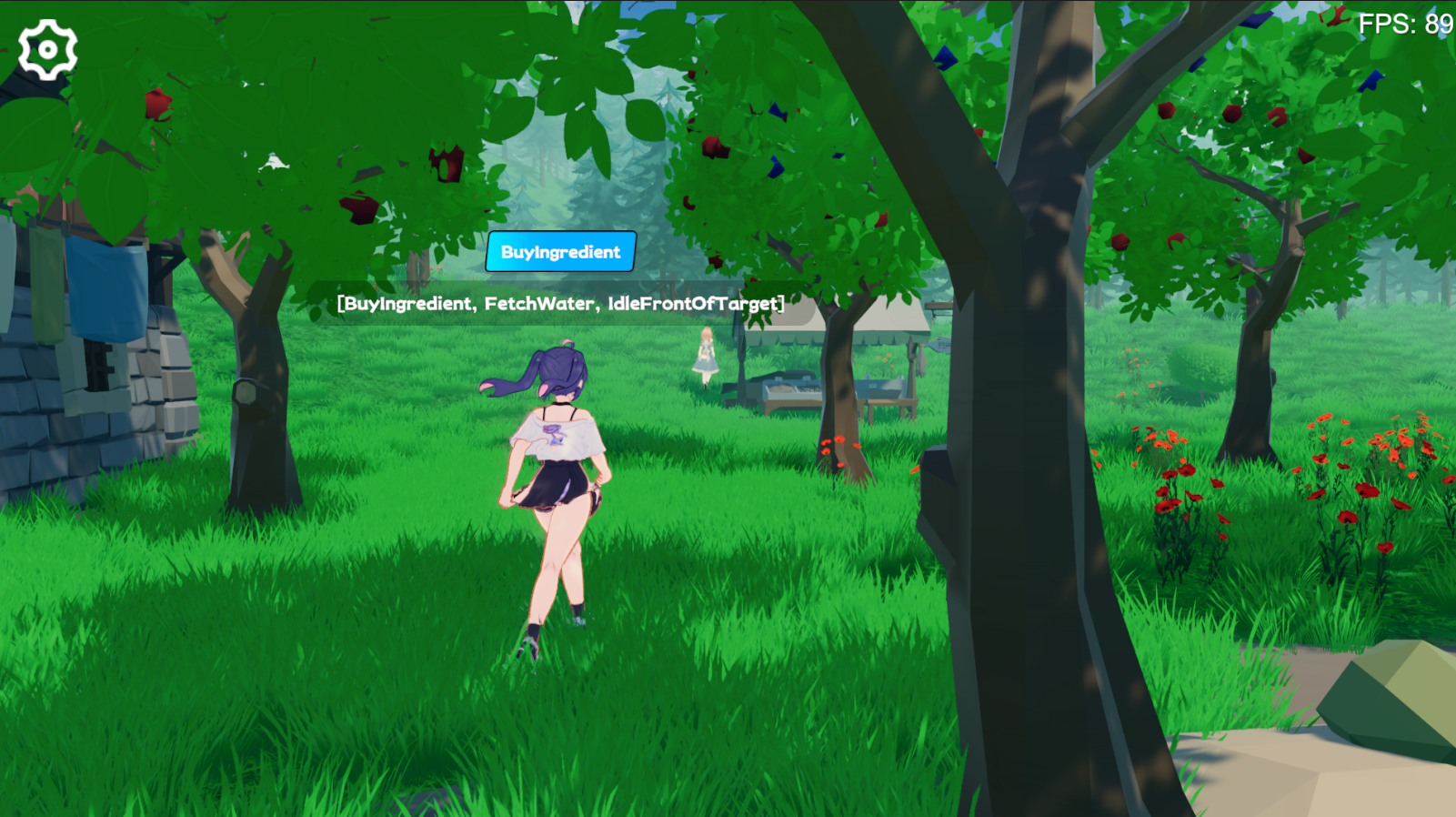
การทดลองใช้ chatgpt3.5 ของ OpenAi เป็นรูปแบบการอนุมาน คุณต้องกรอกคีย์ API ของคุณเองในส่วนต่อประสานการตั้งค่าเกม
มิกซ์
สำหรับรุ่น VRM โปรดดูใบอนุญาตใบอนุญาตของผู้เขียนแต่ละคน
Polygon Fantasy Kingdom เป็นสินทรัพย์ที่ได้รับค่าตอบแทน
https://assetstore.unity.com/packages/3d/environments/fantasy/polygon-fantasy-kingdom-low-poly-3d-art-by-synty-164532
ตัวอย่างฉากได้รับการปรับให้เหมาะสมโดย Scene Optimizer ที่สร้างขึ้นโดย Procedural Worlds
สามารถดาวน์โหลดสภาพแวดล้อม Lowpoly ได้ฟรี
https://assetstore.unity.com/packages/3d/environments/lowpoly-environment-nature-free-medieval-fantasy-series-187052
ความร้อน - UI ที่ทันสมัยสมบูรณ์เป็นสินทรัพย์ที่ชำระแล้ว
https://assetstore.unity.com/packages/2d/gui/heat-complete-modern-ui-264857
Gui-CasualFantasy เป็นสินทรัพย์ที่จ่าย
https://assetstore.unity.com/packages/2d/gui/gui-casual-fantasy-265651
Unity Chan Animation เป็นเจ้าของโดย Unity Technology Japan และภายใต้ใบอนุญาต UC2
แอนิเมชันยุคกลาง Mega Pack เป็นสินทรัพย์ที่จ่ายเงิน
https://assetstore.unity.com/packages/3d/animations/medieval-animations-mega-pack-12141
Unity Starter Asset อยู่ภายใต้ใบอนุญาต Unity Companion และสามารถดาวน์โหลดได้ใน Store ฟรี
https://assetstore.unity.com/packages/essentials/starter-assets-thirdperson-updates-in-new-charactercontroller-pa-196526
Univrm อยู่ภายใต้ใบอนุญาต MIT
https://github.com/vrm-c/univrm
Akiframework อยู่ภายใต้ใบอนุญาต MIT
https://github.com/akikurisu/akiframework
อนิเมชั่นอื่น ๆ เพลง UI และตัวอักษรที่ใช้ในการสาธิตคือทรัพยากรเครือข่ายและไม่ควรใช้เพื่อวัตถุประสงค์ทางการค้า
@misc{realagents,
author = {YiFei Feng},
title = {Real Agents: An planning framework for generative artificial intelligence agents},
year = {2024},
publisher = {GitHub},
journal = {https://github.com/AkiKurisu/Real-Agents},
school = {East China University of Political Science and Law},
location = {Shanghai, China}
}
Steve Rabin, Game AI Pro 3: รวบรวมภูมิปัญญาของมืออาชีพ AI Game , International Standard Book
[Orkin 06] Orkin, J. 2006. 3 รัฐและแผน: AI of Fear , การประชุมนักพัฒนาเกม, ซานฟรานซิสโก, แคลิฟอร์เนีย
JOON SUNG PARK, JOSEPH C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang และ Michael S. Bernstein 2023. ตัวแทนกำเนิด: simulacra แบบโต้ตอบของพฤติกรรมมนุษย์
Wang, Zihao และคณะ “ อธิบายอธิบายวางแผนและเลือก: การวางแผนแบบโต้ตอบด้วยแบบจำลองภาษาขนาดใหญ่ช่วยให้ตัวแทนหลายงานเปิดกว้าง” Arxiv ABS/2302.01560 (2023): n. pag.
Lin J, Zhao H, Zhang A, และคณะ ตัวแทน: กล่องทรายโอเพนซอร์ซสำหรับการประเมินแบบจำลองภาษาขนาดใหญ่ [J] arxiv preprint arxiv: 2308.04026, 2023
Xi, Z. , Chen, W. , Guo, X. , เขา, W. , Ding, Y. , Hong, B. , Zhang, M. , Wang, J. , Jin, S. , Zhou, E. , Zheng, R. , Fan, X. , Wang, X. , Xiong, L. , Liu, Q. Yin, Z. , Dou, S. , Weng, R. , Cheng, W. , Zhang, Q. , Qin, W. , Zheng, Y. , Qiu, X. , Huan, X. , & Gui, T. (2023) การเพิ่มขึ้นและศักยภาพของเอเจนต์แบบจำลองภาษาขนาดใหญ่: การสำรวจ arxiv, abs/2309.07864


