Real Agents
v1.0.0
中文 | Inglês
Os agentes reais são uma estrutura de planejamento que combina métodos tradicionais de inteligência artificial com grandes modelos de linguagem (LLM) e é adequado para agentes de IA generativos. Inclui um projeto de plug-in e demonstração do Unity.
A razão para o desenvolvimento deste projeto é concluir minha tese de graduação (design) e meu interesse pessoal na AI do jogo.
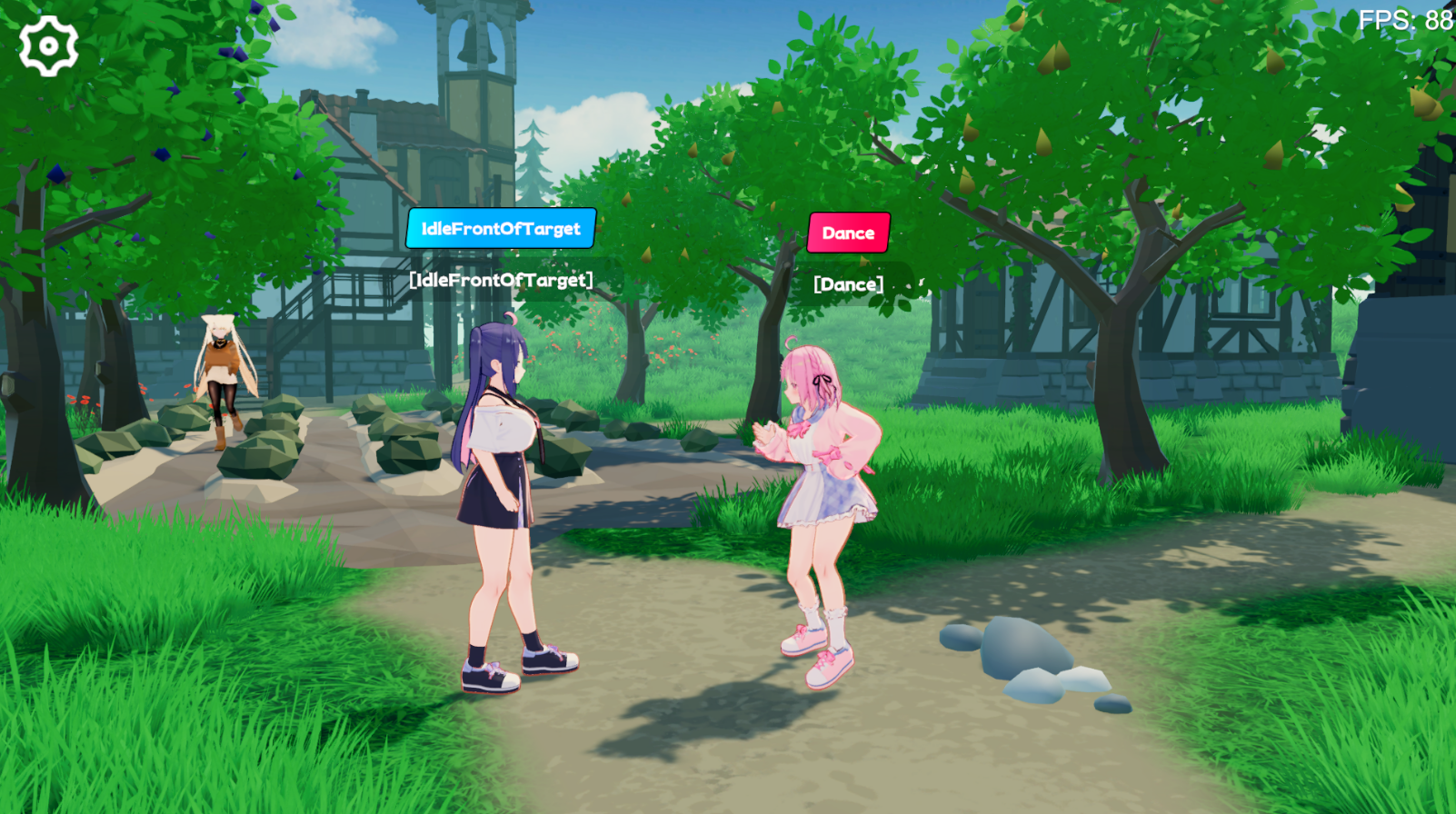
Modelos de idiomas grandes podem executar problemas de raciocínio, tomada de decisão e planejamento. Já temos muitas estruturas de agentes maduros para ajudar os usuários a operar algumas ferramentas, como procurar documentos e criar páginas da web.
Mas acho que existem vários problemas ao implementá -lo no jogo:
Difícil de depuração: se a execução do comportamento depende do LLM, trará o uso de token difícil de estimar e como lidar com exceções de agentes;
Resposta lenta: por exemplo, se o estado do jogo mudar, podemos precisar reconstruir a palavra e o contexto imediatos. Se você deixar o NPC gerar planos como na IA generativa, levará muito tempo para esperar que o LLM seja gerado, o que não pode ser aplicado a jogos em tempo real.
Portanto, tentei tornar o LLM com base no método tradicional de IA, permitindo que o agente planeje entendendo a relação entre quantidades e comportamentos de estado, enquanto a execução do comportamento e o monitoramento do status são concluídos pelo programa, e o agente acionará apenas as ações de planejamento quando o status mudar. .
{
"dependencies" : {
"com.cysharp.unitask" : " https://github.com/Cysharp/UniTask.git?path=src/UniTask/Assets/Plugins/UniTask " ,
"com.huggingface.sharp-transformers" : " https://github.com/AkiKurisu/sharp-transformers.git " ,
"com.kurisu.akiai" : " https://github.com/AkiKurisu/AkiAI.git " ,
"com.kurisu.akibt" : " https://github.com/AkiKurisu/AkiBT.git " ,
"com.kurisu.akiframework" : " https://github.com/AkiKurisu/AkiFramework.git " ,
"com.kurisu.akigoap" : " https://github.com/AkiKurisu/AkiGOAP.git " ,
"com.kurisu.unichat" : " https://github.com/AkiKurisu/UniChat.git "
}
}Baixe a versão do Windows Build na página de lançamento
Primeiro, use o LLM para rotular a ação e o objetivo com base nos dados do GOAP.
Deixe o agente e o planejador gerar e pesquisar planos com base nos estados mundiais (estados mundiais) durante o tempo de execução.
Compare o Plan, LLM reflete e itera na memória.
Você pode fechar o planejador e deixar o agente gerar o plano.
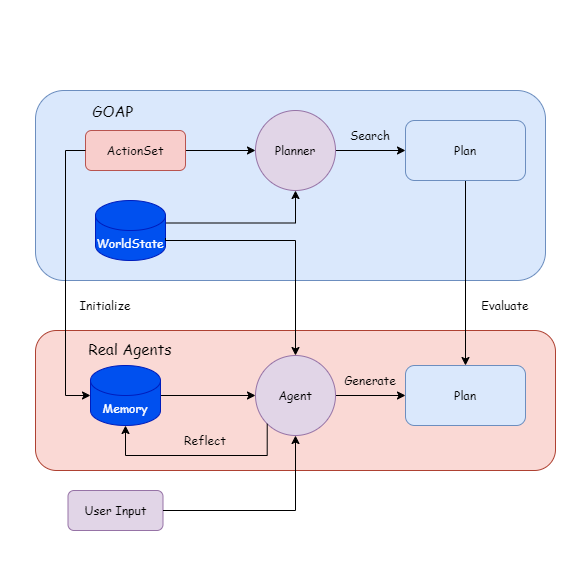
Primeiro, o desenvolvedor define um conjunto de ações executáveis ( ActionSet ) e um conjunto de metas ( GoalSet ).
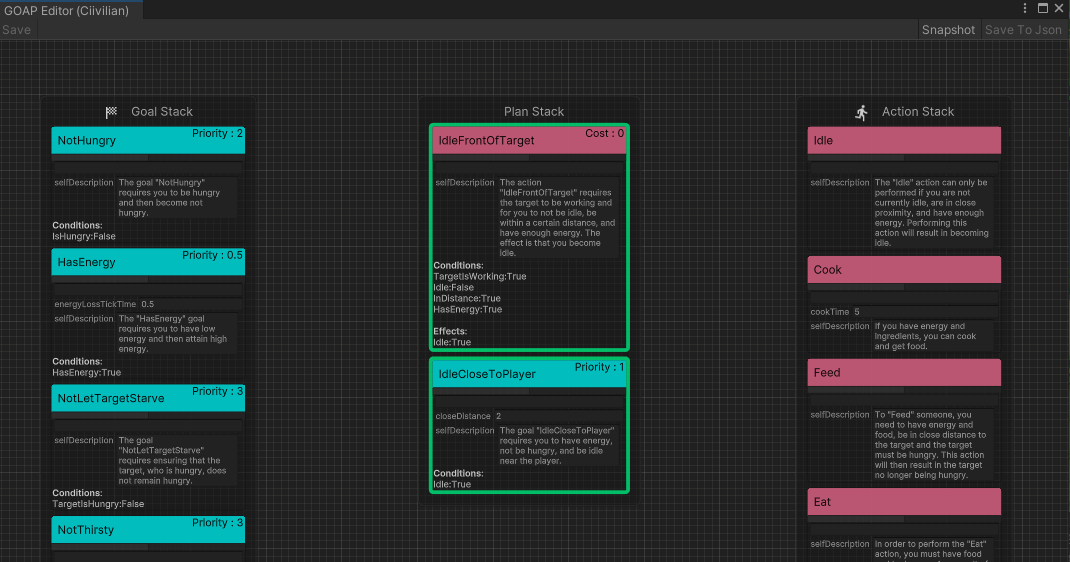
Cada comportamento é baseado nas regras do GOAP e possui uma pré -condição Precondition e um Effect de efeito.
public class Eat : DescriptiveTask
{
protected sealed override void SetupDerived ( )
{
Preconditions [ States . HasFood ] = true ;
Preconditions [ States . IsHungry ] = true ;
}
protected sealed override void SetupEffects ( )
{
Effects [ States . IsHungry ] = false ;
}
} Em segundo lugar, Action de entrada para o modelo de linguagem grande resume-a na linguagem natural como a impressão inicial do agente do comportamento ( InitialImpression ) e memória de longo prazo ( Summary ) e deixa a memória de curto prazo ( Comments ) em branco.
"Name" : " Cook " ,
"InitialImpression" : " To Cook, you need to have energy and ingredients, and as a result, you will have food. " ,
"Summary" : " Latest summary " ,
"Comments" : [
" " ,
" " ,
" " ,
" " ,
" "
] Entrar Goal do modelo de idioma grande e deixar o LLM gerar linguagem natural como uma explicação ( Explanation ) para usar a meta. E combine -os para obter a interpretação do conjunto G.
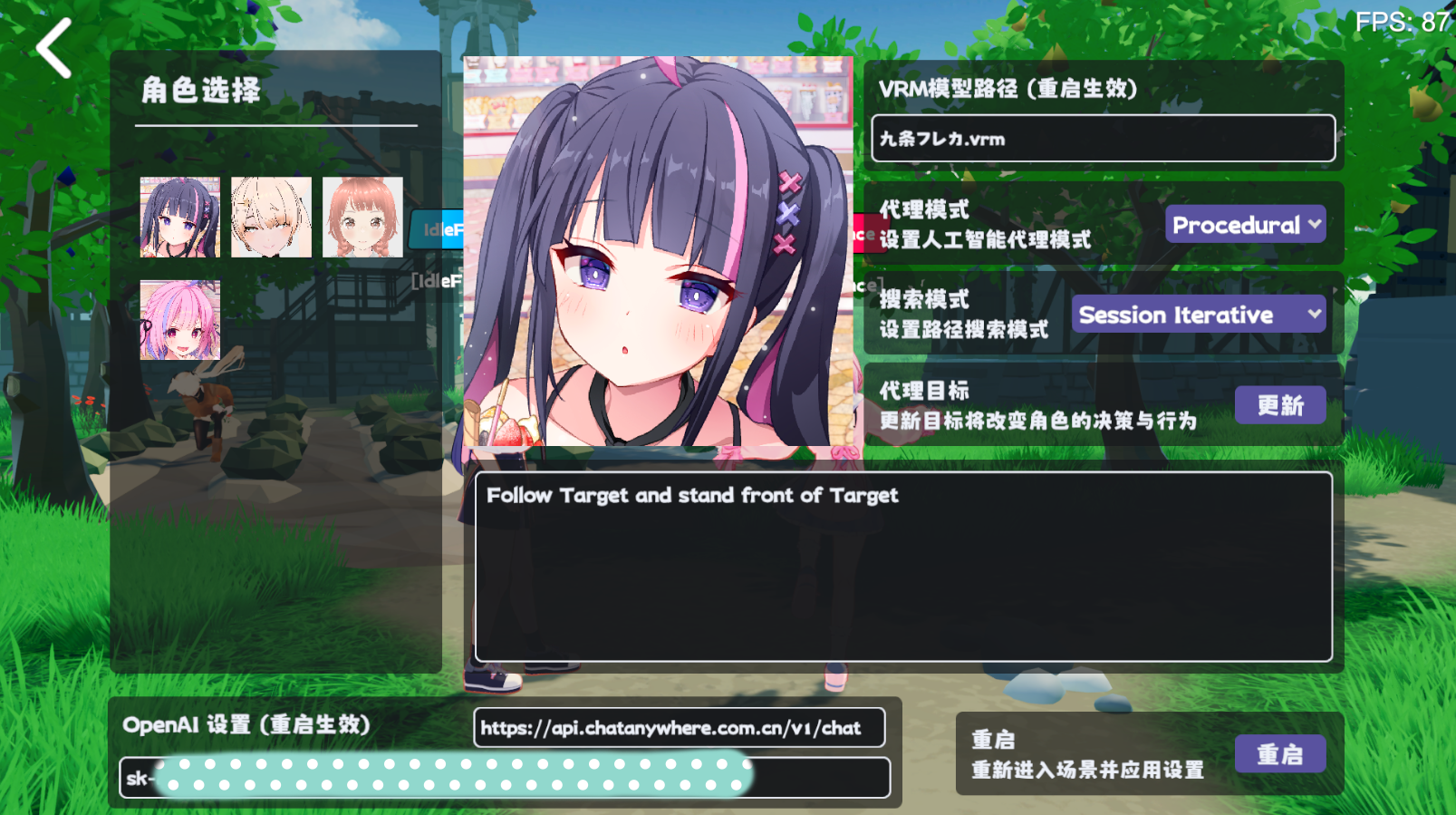
Em agentes reais, você pode clicar diretamente à Self Description no editor da RealAgentSet para gerar os dados acima.
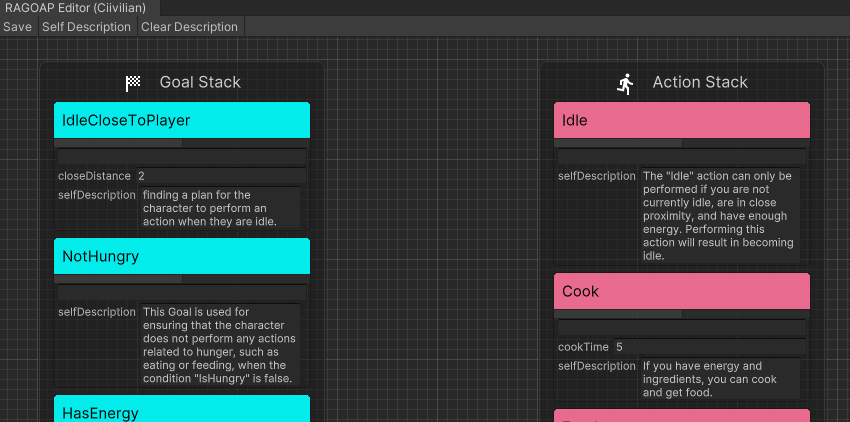
Ajuste o modo agente ( AgentMode ) e defina -o para Training .
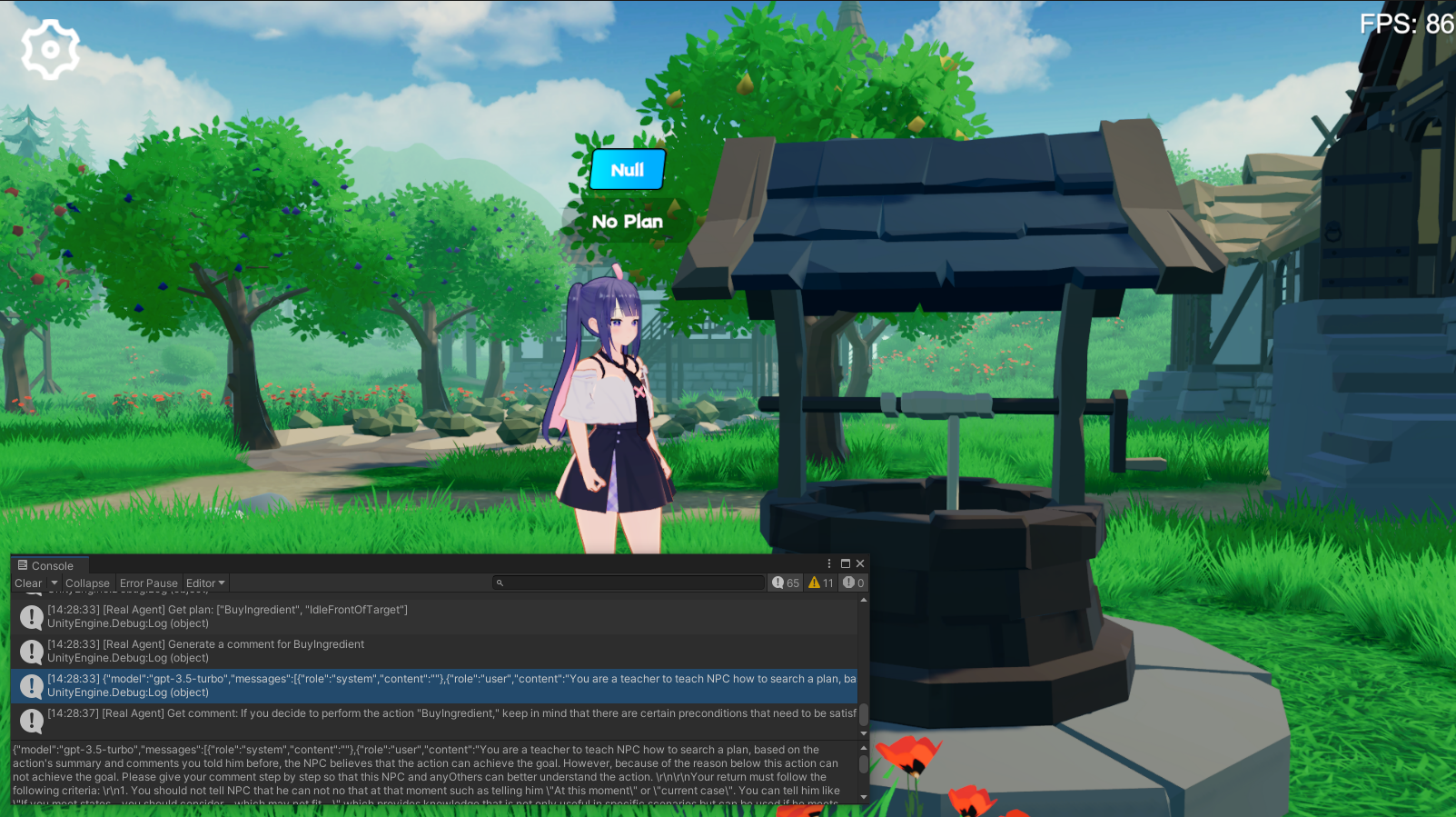
O Plan em execução neste momento é pesquisado pelo planejador e o agente gera um Plan ao mesmo tempo. Se houver uma diferença de comportamento, o LLM reflete sobre o motivo e gera um Comment como uma memória de curto prazo.
Quando a memória de curto prazo atinge o limite, o agente a resume com base na impressão inicial, nos comentários e na memória atual de longo prazo, substitui a memória de longo prazo e itera.
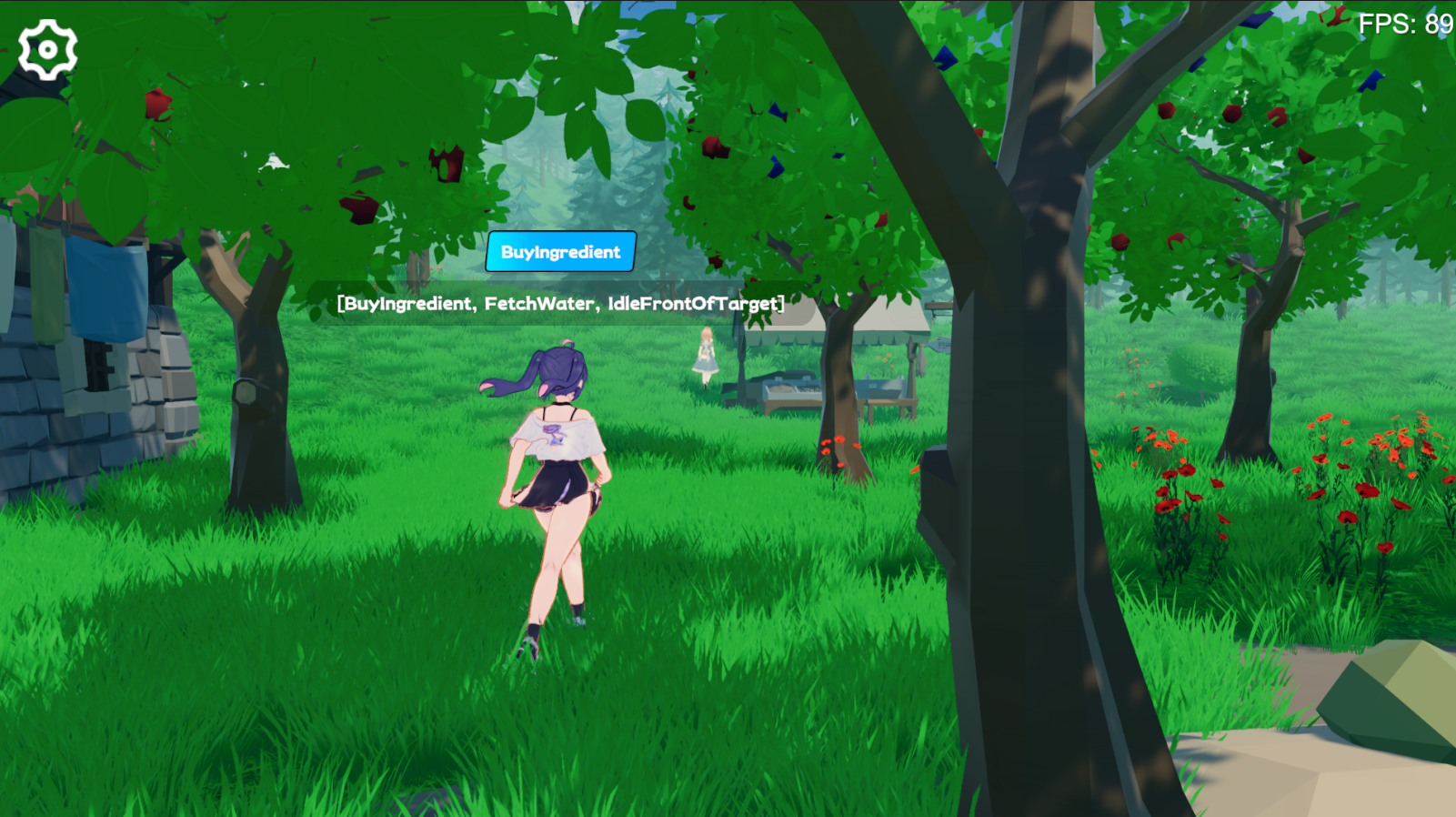
Com base nos objetivos de entrada de fora, o agente raciocina em tempo real no espaço virtual.
A LLM encontra um Plan adequado com base em sua própria memória de cada comportamento. Como não há comparação do planejador, isso apenas determina se o Plan é viável. Caso contrário, o LLM gera ( Comment ) e o injeta na memória.
O experimento usa o ChatGPT3.5 do OpenAI como o modelo de inferência. Você precisa preencher sua própria chave de API na interface de configurações do jogo.
Mit
Para modelos VRM, consulte as declarações de licença do autor individual.
O Polygon Fantasy Kingdom é um ativo pago.
https://assetstore.unity.com/packages/3d/environments/fantasy/polygon-fantasy-kingdom-low-poly-3d-art-by-synty-164532
A cena de exemplo é otimizada pelo otimizador de cenas criado pelos mundos processuais.
O ambiente Lowpoly pode ser baixado em AssetStore gratuitamente.
https://assetstore.unity.com/packages/3d/environments/lowpoly-enevironment-nature-rie-medieval-fantasy-series-187052
Calor - A interface do usuário moderna completa é paga ativo.
https://assetstore.unity.com/packages/2d/gui/heat-complete-modern-ui-264857
O Gui-CasualFantasy é pago.
https://assetstore.unity.com/packages/2d/gui/gui-casual-fantasy-265651
A Unity Chan Animation é de propriedade da Unity Technology Japan e da UC2 License.
Animações medievais Mega Pack recebe ativo pago.
https://assetstore.unity.com/packages/3d/animations/medieval-animations-mega-pack-12141
O Unity Starter Asset está sob a Licença Companion do Unity e pode ser baixado em AssetStore gratuitamente.
https://assetstore.unity.com/packages/essentials/starter-assets-therdperson updates-in-new-charactercontroller-pa-196526
O Univrm está sob licença do MIT.
https://github.com/vrm-c/univrm
Akiframework está sob licença do MIT.
https://github.com/akikurisu/akiframwork
Outros recursos de animação, música, interface do usuário e fonte usados na demonstração são recursos de rede e não devem ser usados para fins comerciais.
@misc{realagents,
author = {YiFei Feng},
title = {Real Agents: An planning framework for generative artificial intelligence agents},
year = {2024},
publisher = {GitHub},
journal = {https://github.com/AkiKurisu/Real-Agents},
school = {East China University of Political Science and Law},
location = {Shanghai, China}
}
Steve Rabin, Game AI Pro 3: Sabedoria coletada de profissionais da AI da AI , Livro Padrão Internacional.
[Orkin 06] Orkin, J. 2006. 3 Estados e um plano: A IA do medo , conferência de desenvolvedores de jogos, San Francisco, CA.
Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang e Michael S. Bernstein. 2023. Agentes generativos: simulacra interativo do comportamento humano.
Wang, Zihao et al. “Descreva, explique, planeje e selecione: planejamento interativo com grandes modelos de idiomas permite agentes de várias tarefas do mundo aberto.” ARXIV ABS/2302.01560 (2023): n. Pag.
Lin J, Zhao H, Zhang A, et al. AgentsIms: uma caixa de areia de código aberto para avaliação de modelos de linguagem grande [J]. Arxiv pré -impressão Arxiv: 2308.04026, 2023.
Xi, Z., Chen, W., Guo, X., He, W., Ding, Y., Hong, B., Zhang, M., Wang, J., Jin, S., Zhou, E., Zheng, R., Fan, X., Wang, X., Xiong, L., Liu, Q., Zhou, Y., Wang, W., Jiang, C., Zou, Y., Liu, X., Yin, Z., Dou, S., Weng, R., Cheng, W., Zhang, Q., Qin, W., Zheng, Y., Qiu, X., Huan, X., & Gui, T. (2023). A ascensão e o potencial de grandes agentes baseados em modelos de linguagem: uma pesquisa. ARXIV, ABS/2309.07864.


