Real Agents
v1.0.0
中文 | Inglés
Real Agents es un marco de planificación que combina métodos tradicionales de inteligencia artificial con modelos de idiomas grandes (LLM) y es adecuado para agentes de IA generativos. Incluye un proyecto de complemento y demostración de Unity.
La razón del desarrollo de este proyecto es completar mi tesis de pregrado (diseño) y mi interés personal en la IA del juego.
Los modelos de idiomas grandes pueden realizar problemas de razonamiento, toma de decisiones y planificación. Ya tenemos muchos marcos de agentes maduros para ayudar a los usuarios a operar algunas herramientas, como buscar documentos y crear páginas web.
Pero creo que hay varios problemas al implementarlo en el juego:
Difícil de depurar: si la ejecución del comportamiento se basa en LLM, provocará un uso de token difícil de estimar y cómo manejar las excepciones de agentes;
Respuesta lenta: por ejemplo, si el estado en el juego cambia, es posible que necesitemos reconstruir la palabra rápida y el contexto. Si deja que NPC genere planes como en Generation AI, llevará mucho tiempo esperar a que se genere LLM, que no se puede aplicar a los juegos en tiempo real.
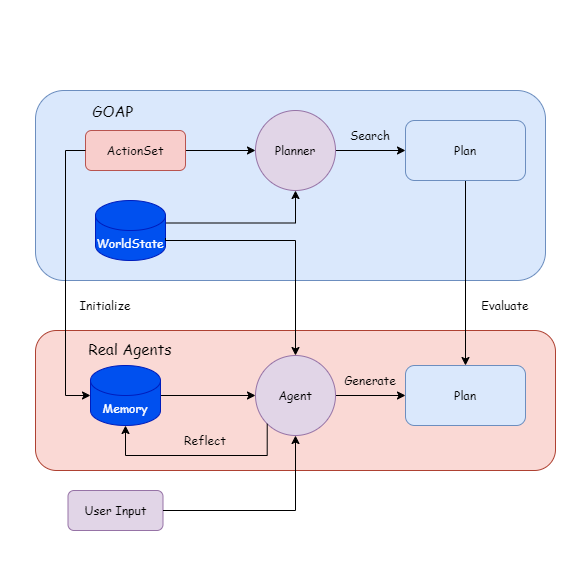
Por lo tanto, intenté hacer LLM en función del método de IA tradicional, permitiendo que el agente planifique comprender la relación entre las cantidades y comportamientos de estado, mientras que el programa completan la ejecución del comportamiento y el monitoreo de estado, y el agente solo activará las acciones de planificación cuando el estado cambia. .
{
"dependencies" : {
"com.cysharp.unitask" : " https://github.com/Cysharp/UniTask.git?path=src/UniTask/Assets/Plugins/UniTask " ,
"com.huggingface.sharp-transformers" : " https://github.com/AkiKurisu/sharp-transformers.git " ,
"com.kurisu.akiai" : " https://github.com/AkiKurisu/AkiAI.git " ,
"com.kurisu.akibt" : " https://github.com/AkiKurisu/AkiBT.git " ,
"com.kurisu.akiframework" : " https://github.com/AkiKurisu/AkiFramework.git " ,
"com.kurisu.akigoap" : " https://github.com/AkiKurisu/AkiGOAP.git " ,
"com.kurisu.unichat" : " https://github.com/AkiKurisu/UniChat.git "
}
}Descargue la versión de compilación de Windows desde la página de lanzamiento
Primero use LLM para etiquetar la acción y el objetivo en función de los datos de GoAP.
Deje que el agente y el planificador generen y sean planes basados en estados mundiales (estados mundiales) durante el tiempo de ejecución.
Compare el plan, LLM refleja e itera en la memoria.
Luego puede cerrar el planificador y dejar que el agente genere el plan.
Primero, el desarrollador define un conjunto de acciones ejecutables ( ActionSet ) y un conjunto de objetivos ( GoalSet ).
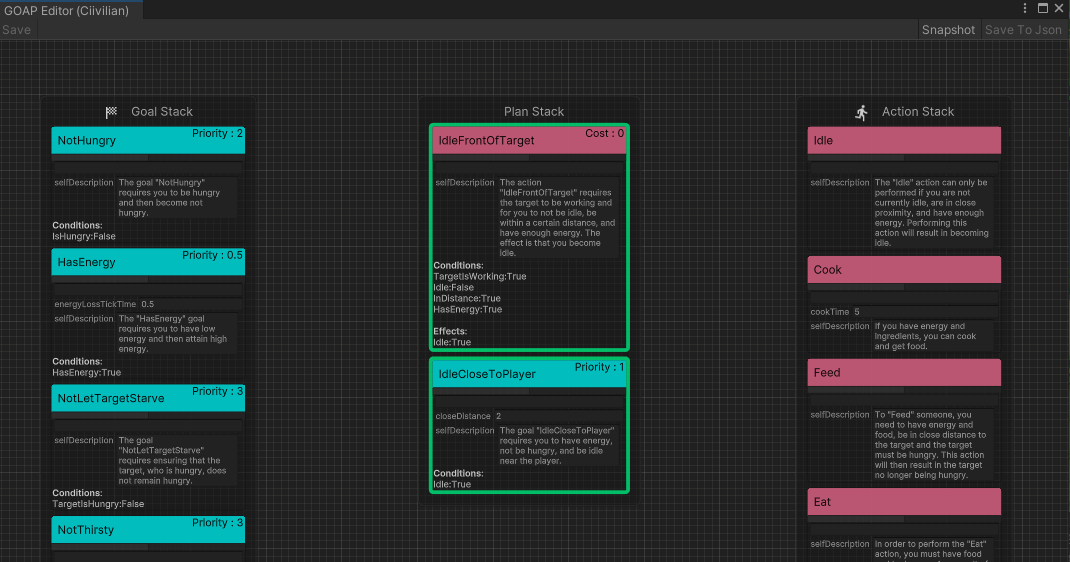
Cada comportamiento se basa en las reglas GoAP y tiene una condición previa Precondition y un Effect de efecto.
public class Eat : DescriptiveTask
{
protected sealed override void SetupDerived ( )
{
Preconditions [ States . HasFood ] = true ;
Preconditions [ States . IsHungry ] = true ;
}
protected sealed override void SetupEffects ( )
{
Effects [ States . IsHungry ] = false ;
}
} En segundo lugar, ingrese Action al modelo de lenguaje grande, resumirlo en el lenguaje natural como la impresión inicial del agente del comportamiento ( InitialImpression ) y la memoria a largo plazo ( Summary ), y deje la memoria a corto plazo ( Comments ) en blanco.
"Name" : " Cook " ,
"InitialImpression" : " To Cook, you need to have energy and ingredients, and as a result, you will have food. " ,
"Summary" : " Latest summary " ,
"Comments" : [
" " ,
" " ,
" " ,
" " ,
" "
] Ingrese Goal del modelo de lenguaje grande y deje que LLM genere un lenguaje natural como explicación ( Explanation ) para usar el objetivo. Y combinarlos para obtener la interpretación del conjunto G.
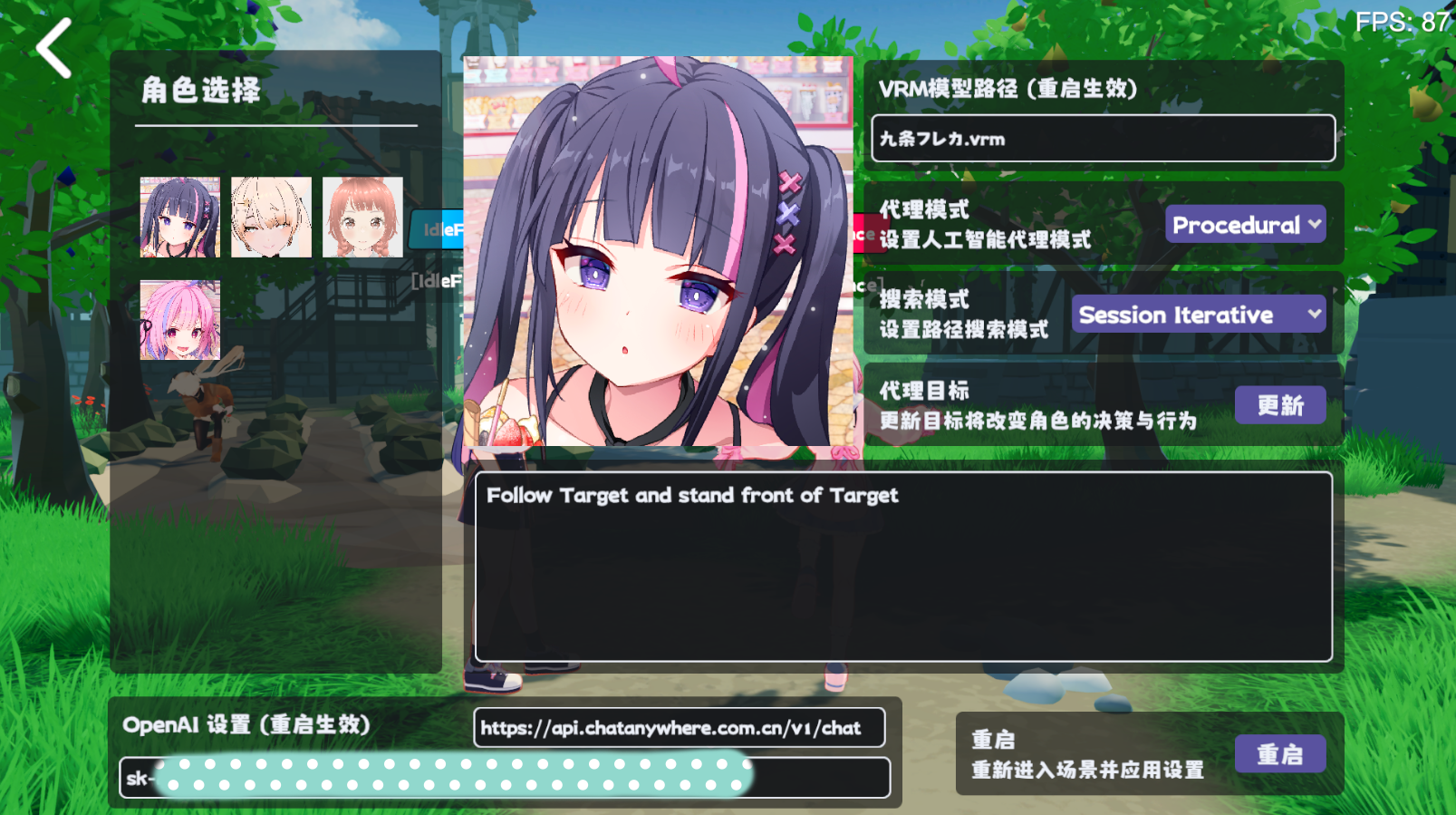
En agentes reales, puede hacer clic directamente en Self Description en el editor de RealAgentSet para generar los datos anteriores.
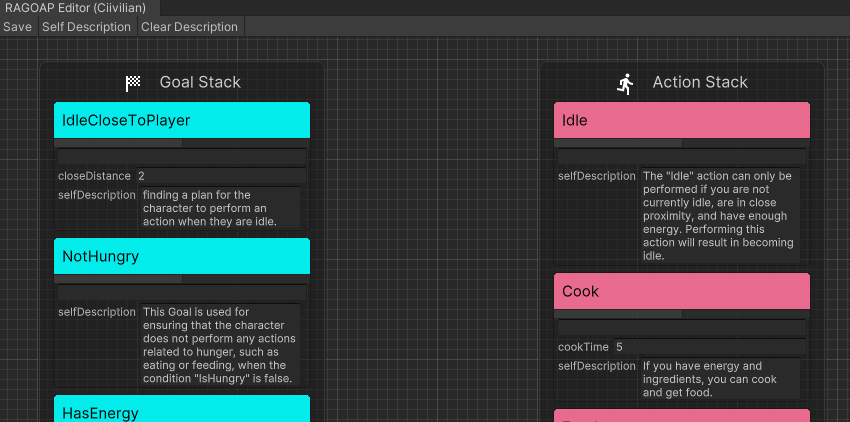
Ajuste el modo de agente ( AgentMode ) y configúrelo en Training .
El planificador busca el Plan que se ejecuta en este momento, y el agente genera un Plan al mismo tiempo. Si hay una diferencia en el comportamiento, LLM reflexiona sobre la razón y genera un Comment como memoria a corto plazo.
Cuando la memoria a corto plazo alcanza el umbral, el agente lo resume en función de la impresión inicial, los comentarios y la memoria actual a largo plazo, sobrescribe la memoria a largo plazo e itera.
Basado en los objetivos de entrada desde el exterior, el agente razona en tiempo real en el espacio virtual.
LLM encuentra un Plan adecuado basado en su propia memoria de cada comportamiento. Dado que no hay comparación del planificador, solo determina si el Plan es factible. Si no, LLM genera ( Comment ) y lo inyecta en la memoria.
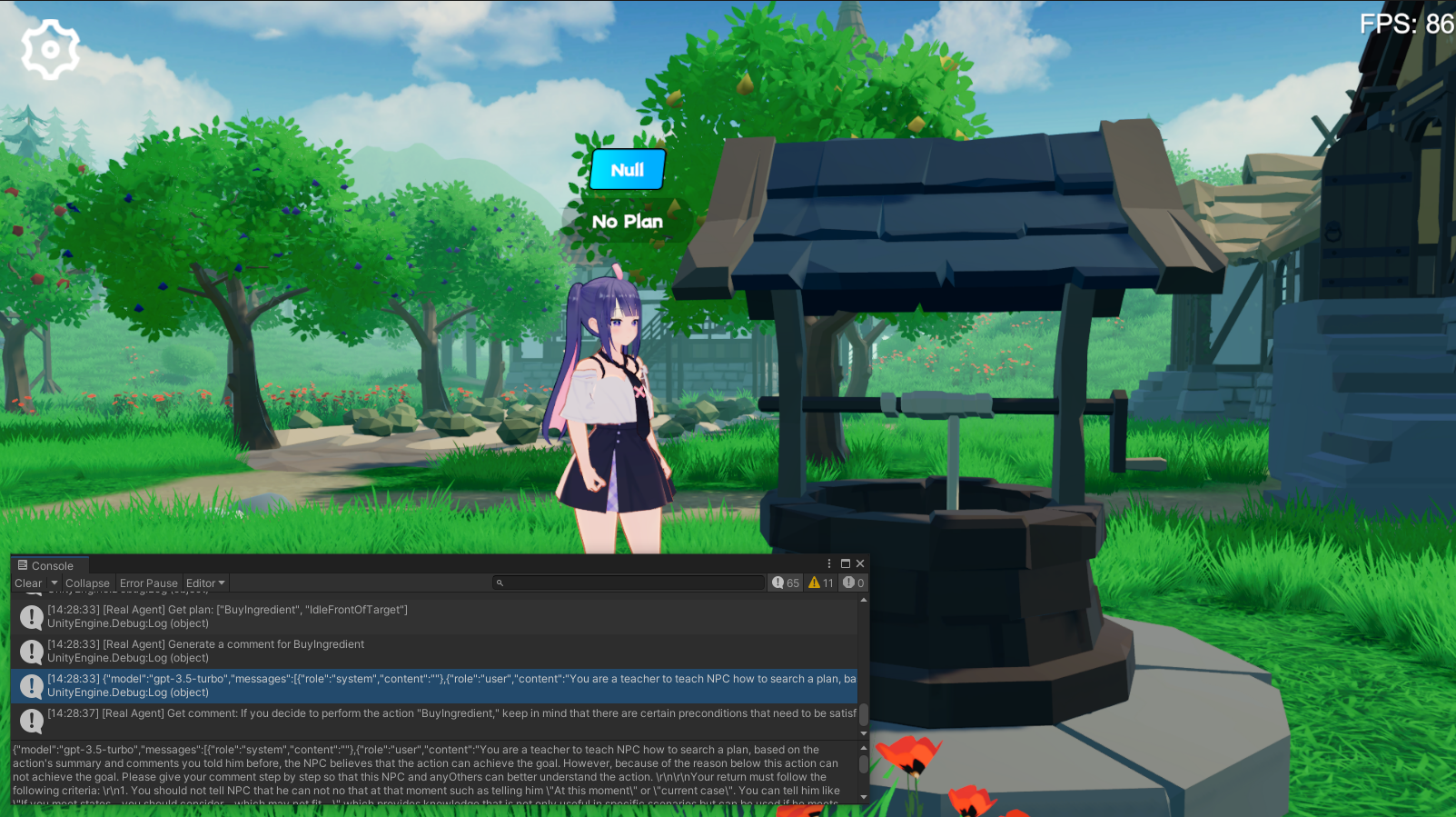
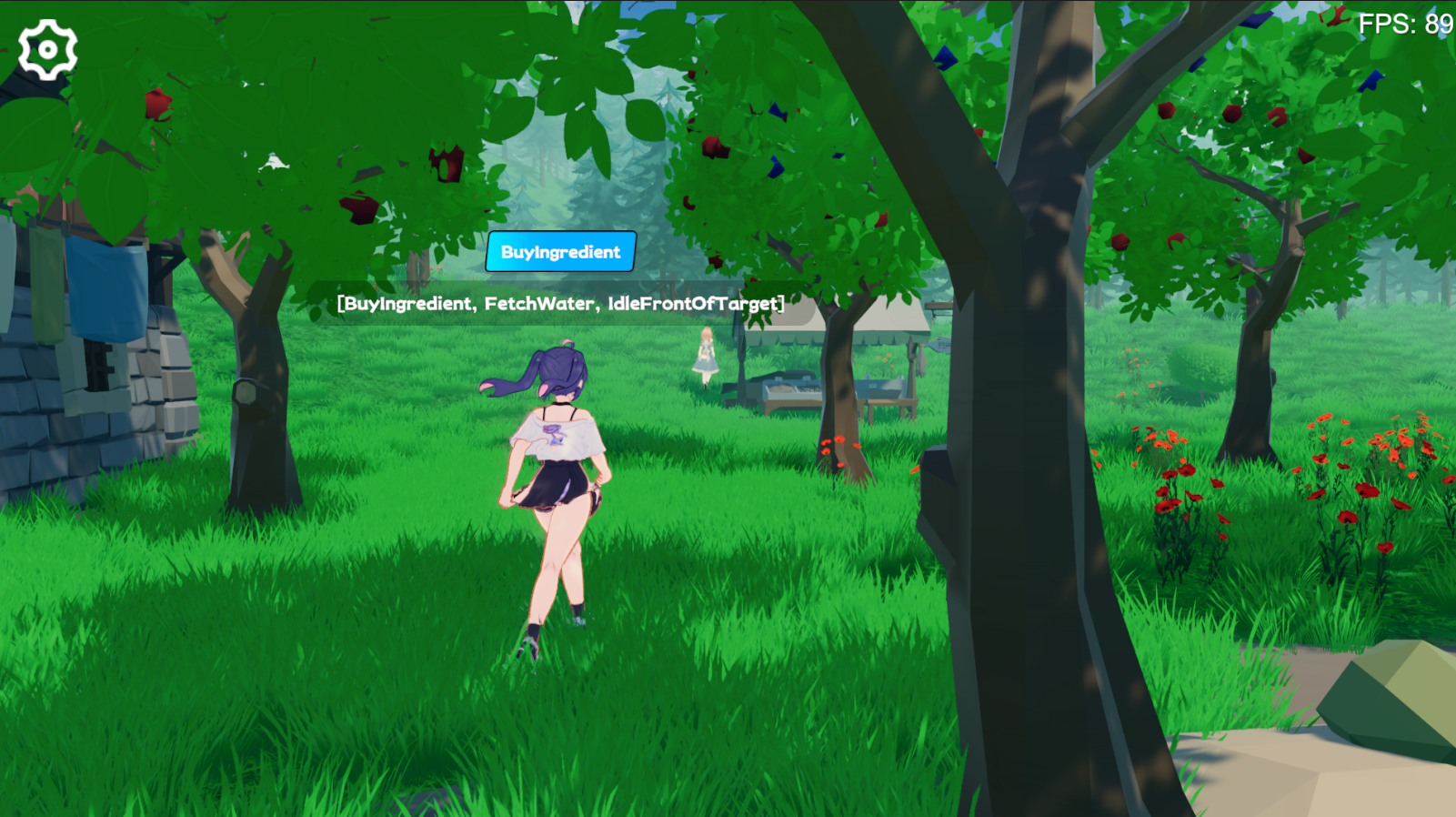
El experimento utiliza ChatGPT3.5 de OpenAI como modelo de inferencia. Debes completar tu propia clave API en la interfaz de configuración del juego.
MIT
Para los modelos VRM, consulte las declaraciones de licencia del autor individual.
Polygon Fantasy Kingdom es un activo pagado.
https://assetstore.unity.com/packages/3d/environments/fantasy/polygon-fantasy-kingdom-low-poly-3d-art-by-synty-164532
La escena de ejemplo está optimizada por la escena optimizador creada por mundos de procedimiento.
El entorno LowPoly se puede descargar en Assetstore de forma gratuita.
https://assetstore.unity.com/packages/3d/environments/lowpoly-environment-nature-free-medieval-fantasy-series-187052
Calor: la interfaz de usuario moderna completa se paga.
https://assetstore.unity.com/packages/2d/gui/heat-complete-modern-ui-264857
Gui-Casualfantasy es un activo pagado.
https://assetstore.unity.com/packages/2d/gui/gui-casual-fantasy-265651
Unity Chan Animation es propiedad de Unity Technology Japan y bajo la licencia UC2.
MEGA PACK de animaciones medievales es un activo pagado.
https://assetstore.unity.com/packages/3d/animations/medieval-animations-mega-pack-12141
Unity Starter Asset está bajo la licencia de Unity Companion y se puede descargar en Assetstore de forma gratuita.
https://assetstore.unity.com/packages/essentials/starter-assets-thirdperson-updates-in-new-characterController-pa-196526
UNIVRM está bajo licencia MIT.
https://github.com/vrm-c/univrm
Akiframework está bajo la licencia MIT.
https://github.com/akikurisu/akiframework
Otros recursos de animación, música, interfaz de usuario y fuente utilizados en la demostración son recursos de red y no deben usarse para fines comerciales.
@misc{realagents,
author = {YiFei Feng},
title = {Real Agents: An planning framework for generative artificial intelligence agents},
year = {2024},
publisher = {GitHub},
journal = {https://github.com/AkiKurisu/Real-Agents},
school = {East China University of Political Science and Law},
location = {Shanghai, China}
}
Steve Rabin, Juego AI Pro 3: Profesionales de AI de sabiduría de AI , Libro estándar internacional.
[Orkin 06] Orkin, J. 2006. 3 estados y un plan: la IA del miedo , la conferencia de desarrolladores de juegos, San Francisco, CA.
Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang y Michael S. Bernstein. 2023. Agentes generativos: simulacros interactivos del comportamiento humano.
Wang, Zihao et al. "Describa, explique, planifique y seleccione: la planificación interactiva con modelos de idiomas grandes permite agentes de tareas múltiples del mundo abierto". ARXIV ABS/2302.01560 (2023): n. pag.
Lin J, Zhao H, Zhang A, et al. Agentsims: una caja de arena de código abierto para la evaluación del modelo de lenguaje grande [J]. Preimpresión ARXIV ARXIV: 2308.04026, 2023.
Xi, Z., Chen, W., Guo, X., He, W., Ding, Y., Hong, B., Zhang, M., Wang, J., Jin, S., Zhou, E., Zheng, R., Fan, X., Wang, X., Xiong, L., Liu, Q., Zhou, Y., Wang, W., Jiang, C., Zou, Y., Liu, X., Yin, Z., Dou, S., Weng, R., Cheng, W., Zhang, Q., Qin, W., Zheng, Y., Qiu, X., Huan, X. y Gui, T. (2023). El aumento y el potencial de los agentes basados en modelos de idiomas grandes: una encuesta. ARXIV, ABS/2309.07864.


