chatpdflike
แอปพลิเคชันการตอบคำถามแบบ end-to-end Appis โดยใช้ API แบบจำลองภาษาขนาดใหญ่
หมายเหตุ : โครงการนี้ไม่ได้เป็นพันธมิตรหรือรับรองโดย ChATPDF นี่เป็นโครงการอิสระที่พยายามทำซ้ำฟังก์ชันการทำงานที่คล้ายกัน
ภาพรวม
chatpdf-like เป็นเว็บแอปพลิเคชันที่อนุญาตให้ผู้ใช้อัปโหลดเอกสาร PDF และโต้ตอบกับพวกเขาโดยใช้แบบสอบถามภาษาธรรมชาติ แอปพลิเคชันใช้ประโยชน์จากแบบจำลองภาษาขนาดใหญ่ (LLMs) เช่น Turbo GPT-3.5 ของ OpenAI เพื่อทำความเข้าใจเนื้อหาของ PDF และให้คำตอบที่กระชับและแม่นยำสำหรับคำถามผู้ใช้
คุณสมบัติ
- การอัปโหลดเอกสาร PDF : อัปโหลดไฟล์ PDF ในเครื่องหรือระบุ URL ไปยังเอกสาร PDF
- ปฏิสัมพันธ์ภาษาธรรมชาติ : ถามคำถามเกี่ยวกับเนื้อหาของ PDF ในภาษาธรรมชาติ
- คำตอบที่เกี่ยวข้อง : รับคำตอบที่กระชับตามเนื้อหาของเอกสาร
- การอ้างอิงแหล่งที่มา : ดูแหล่งที่มา (ส่วนของ PDF) ที่ใช้ในการสร้างคำตอบ
- ผู้ให้บริการ LLM หลายราย : สนับสนุนทั้งรุ่น OpenAI และ Ollama
- เว็บอินเตอร์เฟส : เว็บอินเตอร์เฟสที่เรียบง่ายและใช้งานง่ายสร้างขึ้นด้วยขวดและจาวาสคริปต์
มันทำงานอย่างไร
แอปพลิเคชันเป็นไปตามขั้นตอนหลักเหล่านี้:
การสกัดข้อความและการประมวลผล :
- PDF ถูกแยกวิเคราะห์โดยใช้
PyPDF2 - ข้อความถูกดึงออกมาจากแต่ละหน้าและข้อความขนาดใหญ่จะถูกแบ่งออกเป็นชิ้นที่จัดการได้
การฝังรุ่น :
- สำหรับแต่ละอันข้อความนั้นเวกเตอร์ฝังจะถูกสร้างขึ้นโดยใช้โมเดลการฝังที่เลือก (เช่น OpenAI ของ OpenAI
text-embedding-ada-002 ) - การฝังตัวเหล่านี้แสดงถึงความหมายเชิงความหมายของชิ้นข้อความและจัดเก็บไว้สำหรับการคำนวณความคล้ายคลึงกัน
การจัดการแบบสอบถามผู้ใช้ :
- เมื่อผู้ใช้ถามคำถามเวกเตอร์ฝังตัวสำหรับแบบสอบถามจะถูกสร้างขึ้นโดยใช้โมเดลการฝังเดียวกัน
การค้นหาความคล้ายคลึงกัน :
- แอปพลิเคชันคำนวณความคล้ายคลึงกันของโคไซน์ระหว่างการฝังคิวรีและการฝังตัวของข้อความ
- ชิ้นข้อความที่เกี่ยวข้องมากที่สุดจะถูกเลือกตามคะแนนความคล้ายคลึงกันสูงสุด
การก่อสร้างที่รวดเร็ว :
- พรอมต์ถูกสร้างขึ้นสำหรับรูปแบบภาษาโดยรวมคำถามของผู้ใช้และชิ้นข้อความที่เกี่ยวข้องมากที่สุด
การสร้างคำตอบ :
- พรอมต์จะถูกส่งไปยังรูปแบบภาษา (เช่น GPT-3.5 Turbo ของ OpenAI)
- โมเดลสร้างคำตอบสำหรับคำถามของผู้ใช้ตามบริบทที่ให้ไว้
การตอบสนองการตอบสนอง :
- คำตอบจะแสดงต่อผู้ใช้ในเว็บอินเตอร์เฟส
- นอกจากนี้ยังมีการอ้างอิงถึงชิ้นข้อความต้นฉบับเพื่อความโปร่งใส
เริ่มต้น
ข้อกำหนดเบื้องต้น
- Python : จำเป็นต้องใช้เวอร์ชัน 3.6 หรือสูงกว่า
- คีย์ API :
- คีย์ OpenAI API : จำเป็นต้องใช้โมเดลของ OpenAI สำหรับการสร้างและการสร้างคำตอบ
- คีย์ Ollama API : เป็นทางเลือก จำเป็นหากคุณต้องการใช้โมเดล Ollama
การติดตั้ง
โคลนที่เก็บ
git clone https://github.com/Ulov888/chatpdflike.git
cd chatpdflike
ติดตั้งการพึ่งพา
ใช้ pip ติดตั้งแพ็คเกจที่ต้องการ:
pip install -r requirements.txt
คีย์ API
เพื่อใช้ API ของ Openai:
ลงทะเบียนสำหรับคีย์ API ที่ OpenAI
ตั้งค่าตัวแปรสภาพแวดล้อม OPENAI_API_KEY :
export OPENAI_API_KEY= " your_openai_api_key "
เพื่อใช้ API ของ Ollama (ถ้าต้องการ):
รับคีย์ API จาก Ollama
ตั้งค่าตัวแปรสภาพแวดล้อม OLLAMA_API_KEY :
export OLLAMA_API_KEY= " your_ollama_api_key "
การใช้งาน
เริ่มแอปพลิเคชัน
เรียกใช้แอปพลิเคชันขวด:
โดยค่าเริ่มต้นเซิร์ฟเวอร์จะทำงานบน http://0.0.0.0:8080
เข้าถึงเว็บอินเตอร์เฟส
เปิดเว็บเบราว์เซอร์และนำทางไปที่ http://localhost:8080
อัปโหลดเอกสาร PDF
คุณสามารถ:
- คลิกที่ "อัปโหลด PDF" เพื่อเลือกและอัปโหลดไฟล์ PDF จากคอมพิวเตอร์ของคุณ
- ป้อน URL ไปยังเอกสาร PDF แล้วคลิก "ส่ง"
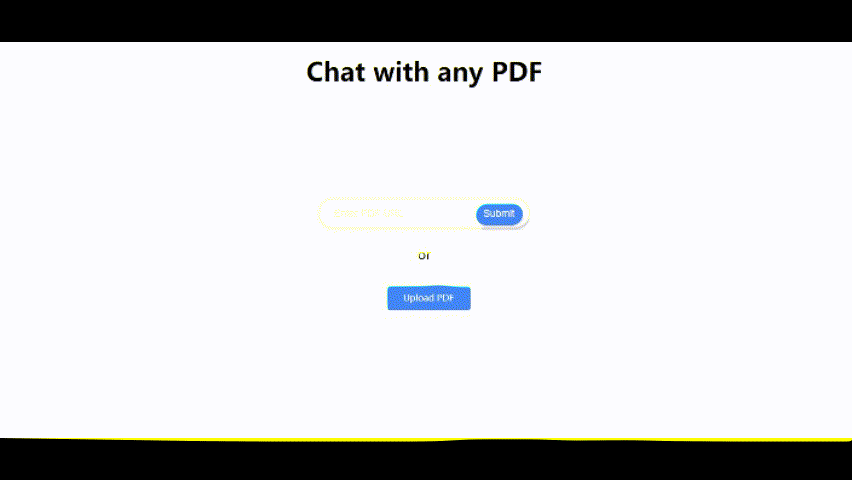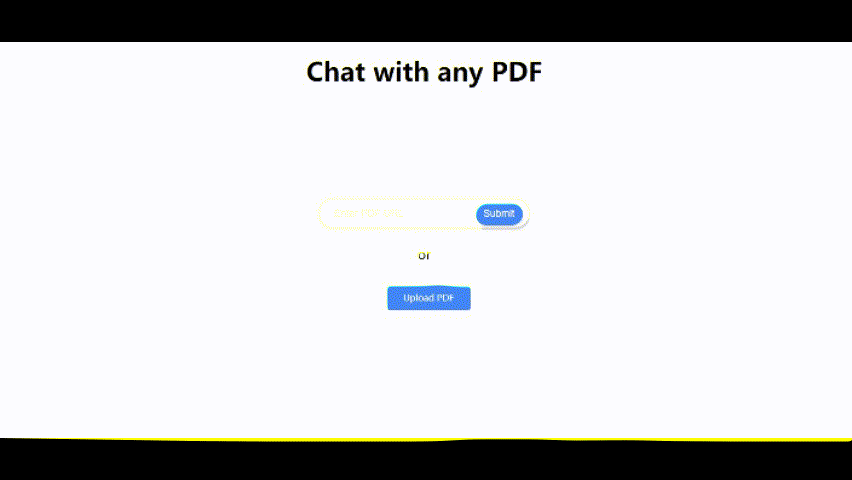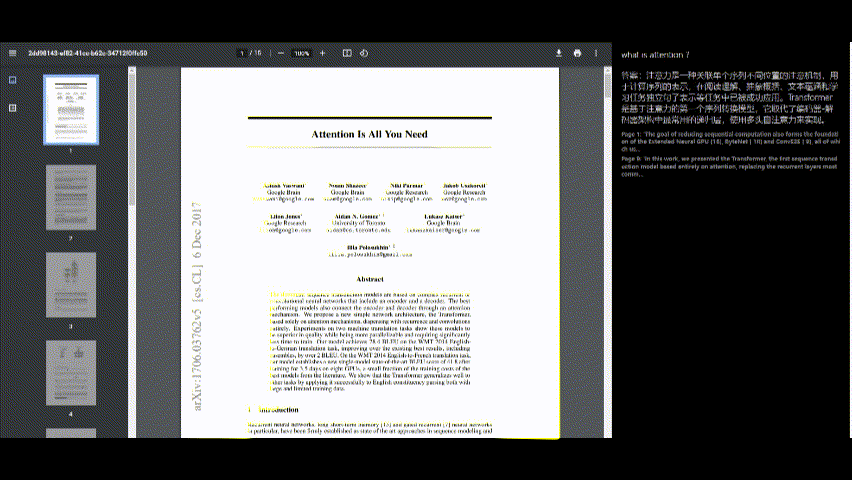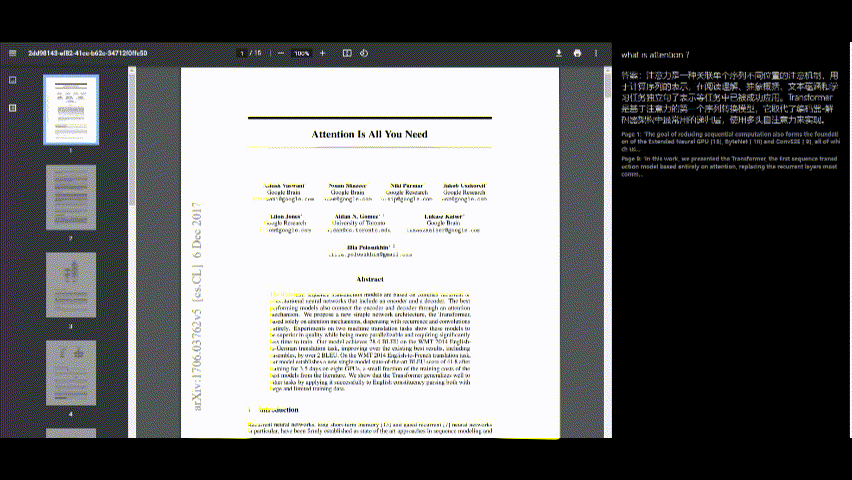
โต้ตอบกับ PDF
- เมื่อประมวลผล PDF แล้วคุณสามารถถามคำถามเกี่ยวกับเนื้อหาโดยใช้อินเทอร์เฟซแชททางด้านขวาของหน้าจอ
- พิมพ์คำถามของคุณในกล่องอินพุตแล้วกด "ส่ง"
ดูคำตอบ
- คำตอบของแอปพลิเคชันจะปรากฏอยู่ด้านล่างคำถามของคุณ
- การอ้างอิงแหล่งที่มา (เช่นหมายเลขหน้าและข้อความที่ตัดตอนมา) มีให้สำหรับบริบท
การปรับแต่ง
กลยุทธ์ที่รวดเร็ว
พฤติกรรมของแบบจำลองภาษาสามารถปรับแต่งได้โดยการปรับเปลี่ยนกลยุทธ์ที่รวดเร็วใน generate_embedding.py โดยเฉพาะในวิธี create_prompt ของคลาส Chatbot
กลยุทธ์รวมถึง:
- กระดาษ : สำหรับการสรุปเอกสารทางวิทยาศาสตร์
- คู่มือ : สำหรับการสรุปคู่มือทางการเงิน (คำตอบเป็นภาษาจีน)
- สัญญา : เพื่อทำความเข้าใจสัญญา (คำตอบเป็นภาษาจีน)
- ค่าเริ่มต้น : กลยุทธ์อเนกประสงค์ทั่วไป (คำตอบเป็นภาษาจีน)
ในการเลือกกลยุทธ์คุณสามารถแก้ไขพารามิเตอร์ strategy เมื่อเรียก create_prompt
ภาษาและผลลัพธ์
ขณะนี้แอปพลิเคชันได้รับการกำหนดค่าเพื่อให้คำตอบเป็นภาษาจีนสำหรับกลยุทธ์บางอย่าง คุณสามารถปรับเปลี่ยนพรอมต์เพื่อเปลี่ยนภาษาหรือปรับพฤติกรรมของโมเดล
ข้อ จำกัด
- ค่าใช้จ่าย OpenAI API : การใช้ API ของ OpenAI จะต้องเสียค่าใช้จ่ายตามการใช้งาน ตรวจสอบให้แน่ใจว่าได้ตรวจสอบการใช้ API ของคุณเพื่อหลีกเลี่ยงค่าใช้จ่ายที่ไม่คาดคิด
- การแยกวิเคราะห์ PDF : แอปพลิเคชันใช้
PyPDF2 ซึ่งอาจไม่สามารถจัดการ PDF ทั้งหมดได้อย่างสมบูรณ์แบบ PDF ที่ซับซ้อนที่มีการจัดรูปแบบที่ผิดปกติอาจไม่สามารถแยกวิเคราะห์ได้อย่างถูกต้อง - ขีด จำกัด การฝัง : ขีด จำกัด โทเค็นสูงสุดสำหรับการฝังตัวอาจ จำกัด ขนาดของชิ้นข้อความหรือความยาวสูงสุดของพรอมต์
- การตอบสนองแบบจำลอง : คุณภาพและความถูกต้องของคำตอบขึ้นอยู่กับประสิทธิภาพของรูปแบบภาษาและความเกี่ยวข้องของชิ้นข้อความที่ดึงมา
การบริจาค
ยินดีต้อนรับ! หากคุณมีข้อเสนอแนะหรือการปรับปรุงใด ๆ อย่าลังเลที่จะส่งปัญหาหรือดึงคำขอ
ใบอนุญาต
โครงการนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต Apache


