Chatpdflike
Ein End-to-End-Dokument-Fragen-Antworten-Anwendung unter Verwendung von APIs mit großer Sprachmodells.
HINWEIS : Dieses Projekt ist nicht mit ChatPDF verbunden oder von ChatPDF unterstützt. Dies ist ein unabhängiges Projekt, das versucht, ähnliche Funktionen zu replizieren.
Überblick
Chatpdf-Like ist eine Webanwendung, mit der Benutzer PDF-Dokumente hochladen und mit ihnen mit natürlichen Sprachanfragen interagieren können. Die Anwendung nutzt große Sprachmodelle (LLMs) wie OpenAIs GPT-3.5-Turbo, um den Inhalt des PDF zu verstehen und präzise und genaue Antworten auf Benutzerfragen zu geben.
Merkmale
- PDF -Dokument hochladen : Laden Sie lokale PDF -Dateien hoch oder geben Sie eine URL in ein PDF -Dokument an.
- Natürliche Sprachinteraktion : Stellen Sie Fragen zum Inhalt des PDF in der natürlichen Sprache.
- Relevante Antworten : Sachen Antworten auf der Grundlage des Inhalts des Dokuments erhalten.
- Quellreferenzen : Quellen anzeigen (Abschnitte des PDF), mit denen die Antwort generiert wurde.
- Mehrere LLM -Anbieter : Unterstützung für OpenAI- und Ollama -Modelle.
- Webschnittstelle : Einfache und intuitive Weboberfläche, die mit Flask und JavaScript erstellt wurde.
Wie es funktioniert
Die Anwendung folgt folgenden Hauptschritten:
Textextraktion und -verarbeitung :
- Das PDF wird mit
PyPDF2 analysiert. - Der Text wird von jeder Seite extrahiert und große Textstücke werden in überschaubare Stücke aufgeteilt.
Einbettung der Erzeugung :
- Für jeden Textblock wird ein Einbettungsvektor unter Verwendung des ausgewählten Einbettungsmodells (z. B. OpenAIs
text-embedding-ada-002 ) generiert. - Diese Einbettungen repräsentieren die semantische Bedeutung der Textbrocken und werden für Ähnlichkeitsberechnungen gespeichert.
Benutzerabfragehandhabung :
- Wenn ein Benutzer eine Frage stellt, wird ein Einbettungsvektor für die Abfrage unter Verwendung desselben Einbettungsmodells generiert.
Ähnlichkeitssuche :
- Die Anwendung berechnet die Kosinus -Ähnlichkeit zwischen der Einbettung von Abfragen und den Einbettungen des Textbetts.
- Die relevantesten Textbrocken werden basierend auf den höchsten Ähnlichkeitswerten ausgewählt.
Sofortige Konstruktion :
- Für das Sprachmodell wird eine Eingabeaufforderung erstellt, die die Frage des Benutzers und die relevantesten Textbrocken enthält.
Antwortgenerierung :
- Die Eingabeaufforderung wird an das Sprachmodell (z. B. OpenAIs GPT-3.5 Turbo) gesendet.
- Das Modell generiert eine Antwort auf die Frage des Benutzers basierend auf dem bereitgestellten Kontext.
Antwortanzeige :
- Die Antwort wird dem Benutzer in der Weboberfläche angezeigt.
- Verweise auf die Quelltextbrocken sind auch für Transparenz bereitgestellt.
Erste Schritte
Voraussetzungen
- Python : Version 3.6 oder höher ist erforderlich.
- API -Schlüssel :
- OpenAI -API -Schlüssel : OpenAIs Modelle für Einbettungen und Antwortgenerierung.
- Ollama API -Schlüssel : Optional. Erforderlich, wenn Sie Ollama -Modelle verwenden möchten.
Installation
Klonen Sie das Repository
git clone https://github.com/Ulov888/chatpdflike.git
cd chatpdflike
Abhängigkeiten installieren
Installieren Sie die erforderlichen Pakete mit pip :
pip install -r requirements.txt
API -Schlüssel
Um Openais API zu verwenden:
Melden Sie sich für einen API -Schlüssel bei OpenAI an.
Setzen Sie die Umgebungsvariable OPENAI_API_KEY :
export OPENAI_API_KEY= " your_openai_api_key "
Um Ollamas API (falls gewünscht) zu verwenden:
Erhalten Sie einen API -Schlüssel von Ollama.
Legen Sie die Umgebungsvariable OLLAMA_API_KEY fest:
export OLLAMA_API_KEY= " your_ollama_api_key "
Verwendung
Starten Sie die Anwendung
Führen Sie die Flask -Anwendung aus:
Standardmäßig wird der Server unter http://0.0.0.0:8080 ausgeführt.
Greifen Sie auf die Weboberfläche zu
Öffnen Sie einen Webbrowser und navigieren Sie zu http://localhost:8080 .
Laden Sie ein PDF -Dokument hoch hoch
Sie können entweder:
- Klicken Sie auf "PDF hochladen", um eine PDF -Datei von Ihrem Computer auszuwählen und hochzuladen.
- Geben Sie eine URL in ein PDF -Dokument ein und klicken Sie auf "Senden".
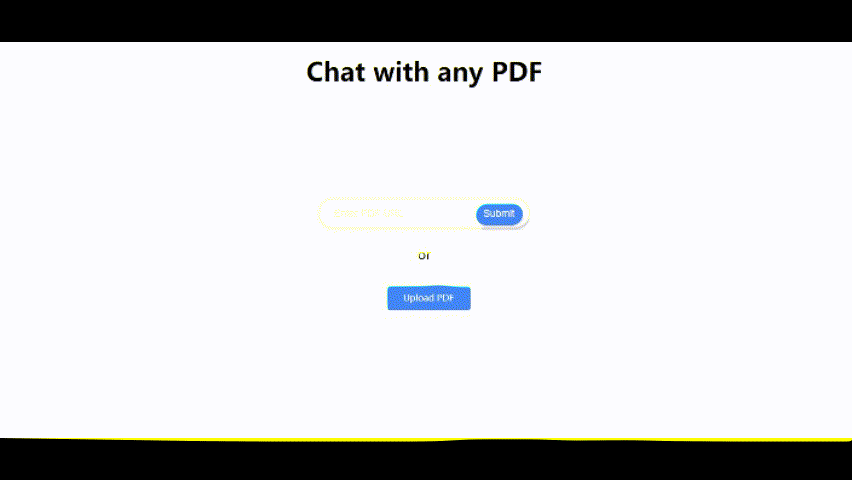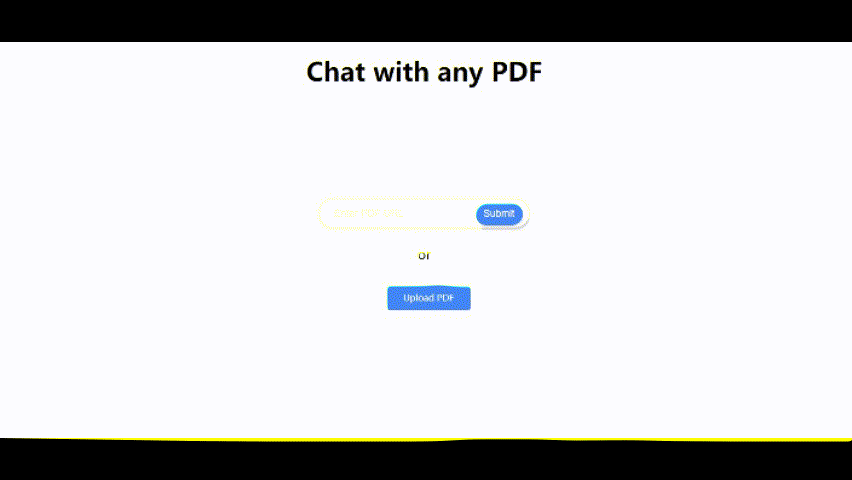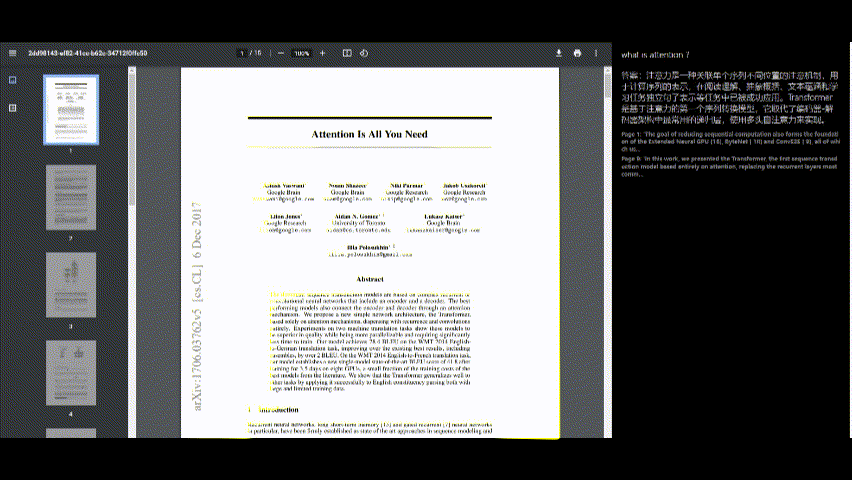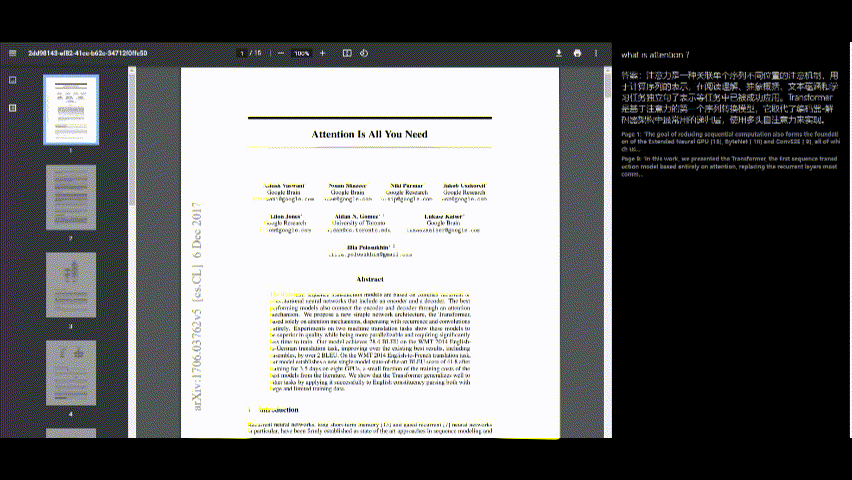
Interagieren Sie mit dem PDF
- Sobald der PDF verarbeitet wurde, können Sie Fragen zu den Inhalten mit der Chat -Schnittstelle auf der rechten Seite des Bildschirms stellen.
- Geben Sie Ihre Frage in das Eingabefeld ein und drücken Sie "Senden".
Antworten anzeigen
- Die Antwort der Anwendung wird unter Ihrer Frage angezeigt.
- Quellreferenzen (z. B. Seitennummern und Auszüge) werden für den Kontext bereitgestellt.
Anpassung
Schnelle Strategien
Das Verhalten des Sprachmodells kann angepasst werden, indem die Eingabeaufforderungstrategien in generate_embedding.py geändert werden, insbesondere in der Methode create_prompt der Chatbot -Klasse.
Zu den Strategien gehören:
- Papier : Für die Zusammenfassung wissenschaftlicher Papiere.
- Handbuch : Für die Zusammenfassung von Finanzhandbüchern (Antworten auf Chinesisch).
- Vertrag : zum Verständnis von Verträgen (Antworten auf Chinesisch).
- Ausfall : Allgemeine Strategie (Antworten auf Chinesisch).
Um eine Strategie auszuwählen, können Sie den strategy beim Aufrufen create_prompt ändern.
Sprache und Ausgabe
Die Anwendung ist derzeit so konfiguriert, dass sie Antworten auf Chinesisch für einige Strategien liefern. Sie können die Eingabeaufforderungen ändern, um die Sprache zu ändern oder das Verhalten des Modells anzupassen.
Einschränkungen
- OpenAI -API -Kosten : Die Verwendung von OpenAIs API entspricht Kosten auf der Grundlage der Nutzung. Stellen Sie sicher, dass Sie Ihre API -Verwendung überwachen, um unerwartete Gebühren zu vermeiden.
- PDF -Parsing : Die Anwendung verwendet
PyPDF2 , die möglicherweise nicht alle PDFs perfekt verarbeiten. Komplexe PDFs mit ungewöhnlicher Formatierung können nicht korrekt analysiert. - Einbettungsgrenzen : Die maximale Token -Grenze für Einbettungen kann die Größe der Textstücke oder die maximale Länge der Eingabeaufforderung einschränken.
- Modellantworten : Die Qualität und Genauigkeit der Antworten hängt von der Leistung des Sprachmodells und der Relevanz der abgerufenen Textbrocken ab.
Beitragen
Beiträge sind willkommen! Wenn Sie Vorschläge oder Verbesserungen haben, können Sie sich gerne ein Problem einreichen oder anfordern.
Lizenz
Dieses Projekt ist unter der Apache -Lizenz lizenziert.


