Chatpdflike
Une application de questions-répondants de document de bout en bout utilisant des API de modèle de grande langue.
Remarque : Ce projet n'est pas affilié ou approuvé par ChatPDF. Il s'agit d'un projet indépendant qui tente de reproduire des fonctionnalités similaires.
Aperçu
ChatPdf-like est une application Web qui permet aux utilisateurs de télécharger des documents PDF et d'interagir avec eux à l'aide de requêtes en langage naturel. L'application exploite les modèles de grandes langues (LLMS) comme le GPT-3.5 Turbo d'OpenAI pour comprendre le contenu du PDF et fournir des réponses concises et précises aux questions des utilisateurs.
Caractéristiques
- Téléchargement de document PDF : téléchargez les fichiers PDF locaux ou fournissez une URL à un document PDF.
- Interaction en langage naturel : posez des questions sur le contenu du PDF en langage naturel.
- Réponses pertinentes : recevez des réponses concises en fonction du contenu du document.
- RÉFÉRENCES DE SOURCE : Voir les sources (sections du PDF) qui ont été utilisées pour générer la réponse.
- Plusieurs fournisseurs LLM : Prise en charge des modèles OpenAI et OLLAMA.
- Interface Web : interface Web simple et intuitive construite avec Flask et JavaScript.
Comment ça marche
L'application suit ces étapes principales:
Extraction et traitement de texte :
- Le PDF est analysé en utilisant
PyPDF2 . - Le texte est extrait de chaque page et les gros morceaux de texte sont divisés en morceaux gérables.
Génération d'intégration :
- Pour chaque morceau de texte, un vecteur d'incorporation est généré à l'aide du modèle d'incorporation sélectionné (par exemple,
text-embedding-ada-002 d'OpenAI). - Ces intérêts représentent la signification sémantique des morceaux de texte et sont stockés pour des calculs de similitude.
Manipulation de la requête utilisateur :
- Lorsqu'un utilisateur pose une question, un vecteur d'intégration pour la requête est généré en utilisant le même modèle d'intégration.
Recherche de similitude :
- L'application calcule la similitude du cosinus entre l'intégration de la requête et les incorporations de morceaux de texte.
- Les morceaux de texte les plus pertinents sont sélectionnés en fonction des scores de similitude les plus élevés.
Construction rapide :
- Une invite est créée pour le modèle de langue, incorporant la question de l'utilisateur et les morceaux de texte les plus pertinents.
Génération de réponses :
- L'invite est envoyée au modèle de langue (par exemple, le GPT-3.5 Turbo d'OpenAI).
- Le modèle génère une réponse à la question de l'utilisateur en fonction du contexte fourni.
Affichage de la réponse :
- La réponse est affichée à l'utilisateur dans l'interface Web.
- Des références aux morceaux de texte source sont également fournies pour la transparence.
Commencer
Condition préalable
- Python : la version 3.6 ou plus est requise.
- Clés API :
- Clé API OpenAI : requis pour utiliser les modèles d'Openai pour les intégres et la génération de réponses.
- Clé API Olllama : Facultatif. Requis si vous souhaitez utiliser des modèles Olllama.
Installation
Cloner le référentiel
git clone https://github.com/Ulov888/chatpdflike.git
cd chatpdflike
Installer des dépendances
À l'aide de pip , installez les packages requis:
pip install -r requirements.txt
Clés API
Pour utiliser l'API d'Openai:
Inscrivez-vous à une clé API à Openai.
Définissez la variable d'environnement OPENAI_API_KEY :
export OPENAI_API_KEY= " your_openai_api_key "
Pour utiliser l'API d'Olllama (si vous le souhaitez):
Obtenez une clé API de Olllama.
Définissez la variable d'environnement OLLAMA_API_KEY :
export OLLAMA_API_KEY= " your_ollama_api_key "
Usage
Démarrer la demande
Exécutez l'application Flask:
Par défaut, le serveur s'exécute sur http://0.0.0.0:8080 .
Accéder à l'interface Web
Ouvrez un navigateur Web et accédez à http://localhost:8080 .
Télécharger un document PDF
Vous pouvez soit:
- Cliquez sur "Télécharger PDF" pour sélectionner et télécharger un fichier PDF à partir de votre ordinateur.
- Entrez une URL dans un document PDF et cliquez sur "Soumettre".
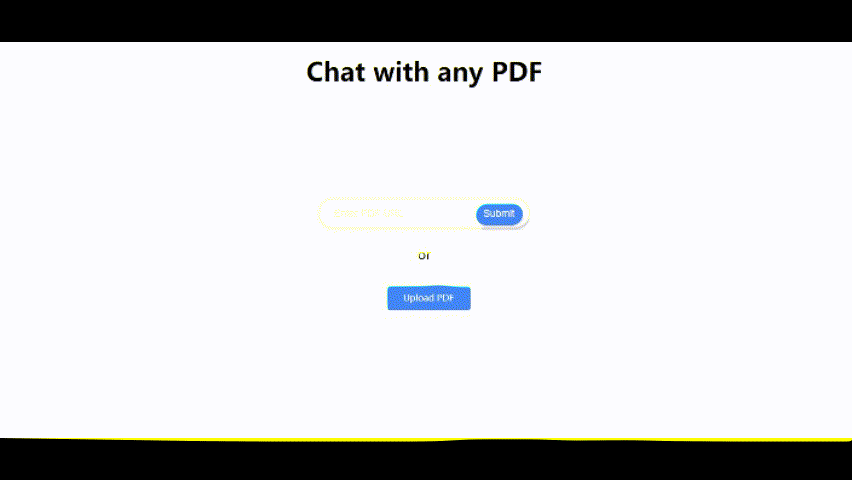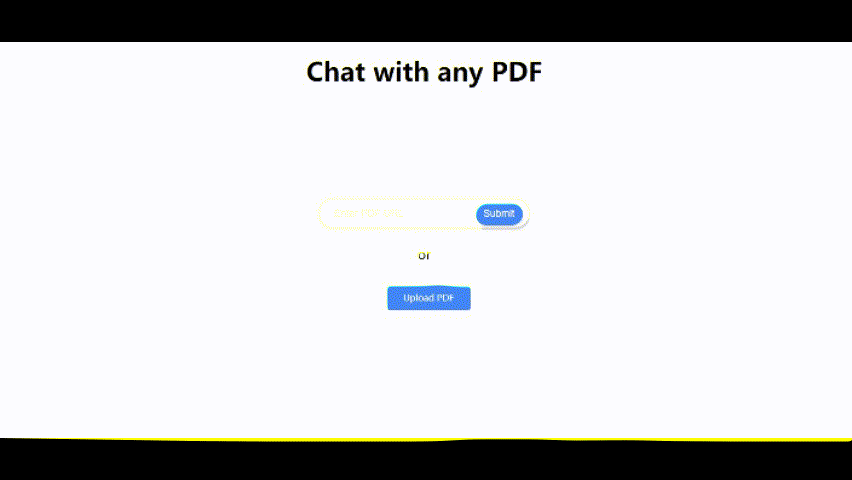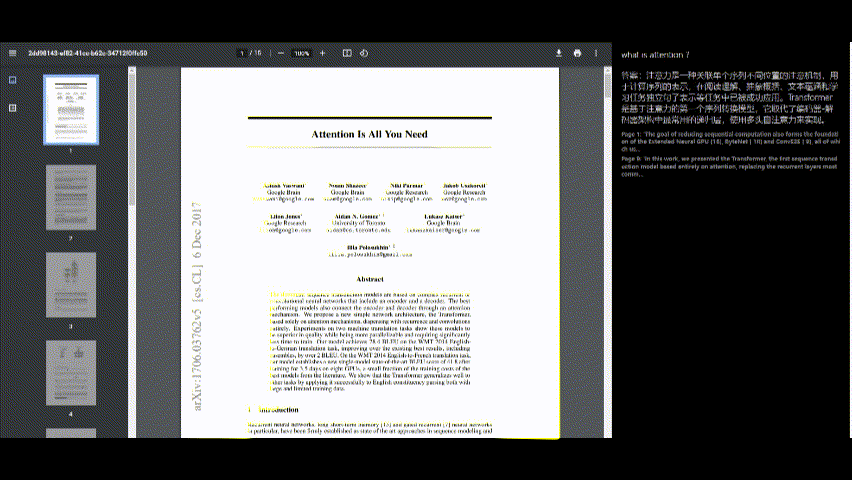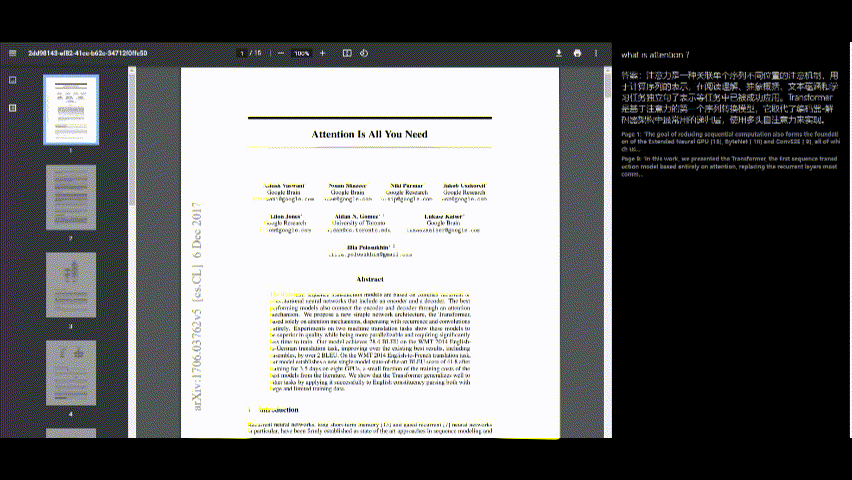
Interagir avec le PDF
- Une fois le PDF traité, vous pouvez poser des questions sur son contenu à l'aide de l'interface de chat sur le côté droit de l'écran.
- Tapez votre question dans la zone d'entrée et appuyez sur "Envoyer".
Afficher les réponses
- La réponse de la demande apparaîtra sous votre question.
- Les références source (par exemple, numéros de page et extraits) sont fournies pour le contexte.
Personnalisation
Stratégies rapides
Le comportement du modèle de langue peut être personnalisé en modifiant les stratégies rapides dans generate_embedding.py , en particulier dans la méthode create_prompt de la classe Chatbot .
Les stratégies comprennent:
- Document : pour résumer les articles scientifiques.
- Manuel : pour résumer les manuels financiers (réponses en chinois).
- Contrat : pour comprendre les contrats (réponses en chinois).
- Par défaut : stratégie à usage général (réponses en chinois).
Pour sélectionner une stratégie, vous pouvez modifier le paramètre strategy lors de l'appel create_prompt .
Langue et sortie
L'application est actuellement configurée pour fournir des réponses en chinois pour certaines stratégies. Vous pouvez modifier les invites pour modifier la langue ou ajuster le comportement du modèle.
Limites
- Coûts de l'API OpenAI : L'utilisation de l'API d'Openai entraînera des coûts en fonction de l'utilisation. Assurez-vous de surveiller votre utilisation de l'API pour éviter les frais inattendus.
- Analyse PDF : l'application utilise
PyPDF2 , qui peut ne pas gérer parfaitement tous les PDF. Les PDF complexes avec formatage inhabituel peuvent ne pas analyser correctement. - Limites d'incorporation : la limite de jeton maximale pour les intérêts peut restreindre la taille des morceaux de texte ou la longueur maximale de l'invite.
- Réponses du modèle : la qualité et la précision des réponses dépendent des performances du modèle de langue et de la pertinence des morceaux de texte récupérés.
Contributif
Les contributions sont les bienvenues! Si vous avez des suggestions ou des améliorations, n'hésitez pas à soumettre une demande de problème ou de traction.
Licence
Ce projet est sous licence Apache.


