chatpdflike
1.0.0
大規模な言語モデルAPIを使用したエンドツーエンドのドキュメント質問アプリケーション。
注:このプロジェクトは、CHATPDFと提携しておらず、承認されていません。これは、同様の機能を複製しようとする独立したプロジェクトです。
chatpdf-likeは、ユーザーがPDFドキュメントをアップロードし、自然言語クエリを使用して対話できるWebアプリケーションです。アプリケーションは、PDFのコンテンツを理解し、ユーザーの質問に対する簡潔で正確な回答を提供するために、OpenaiのGPT-3.5ターボのような大規模な言語モデル(LLM)を活用しています。
アプリケーションは、これらの主な手順に従います。
テキスト抽出と処理:
PyPDF2を使用して解析されます。埋め込み世代:
text-embedding-ada-002 )。ユーザークエリ処理:
類似性検索:
迅速な構築:
回答生成:
応答表示:
リポジトリをクローンします
git clone https://github.com/Ulov888/chatpdflike.git
cd chatpdflike依存関係をインストールします
pipを使用して、必要なパッケージをインストールします。
pip install -r requirements.txtOpenaiのAPIを使用するには:
OpenaiでAPIキーにサインアップします。
OPENAI_API_KEY環境変数を設定します。
export OPENAI_API_KEY= " your_openai_api_key "OllamaのAPIを使用するには(必要に応じて):
OllamaからAPIキーを取得します。
OLLAMA_API_KEY環境変数を設定します。
export OLLAMA_API_KEY= " your_ollama_api_key " アプリケーションを開始します
Flaskアプリケーションを実行します:
python run.pyデフォルトでは、サーバーはhttp://0.0.0.0:8080で実行されます。
Webインターフェイスにアクセスします
Webブラウザーを開き、 http://localhost:8080に移動します。
PDFドキュメントをアップロードします
どちらもできます:
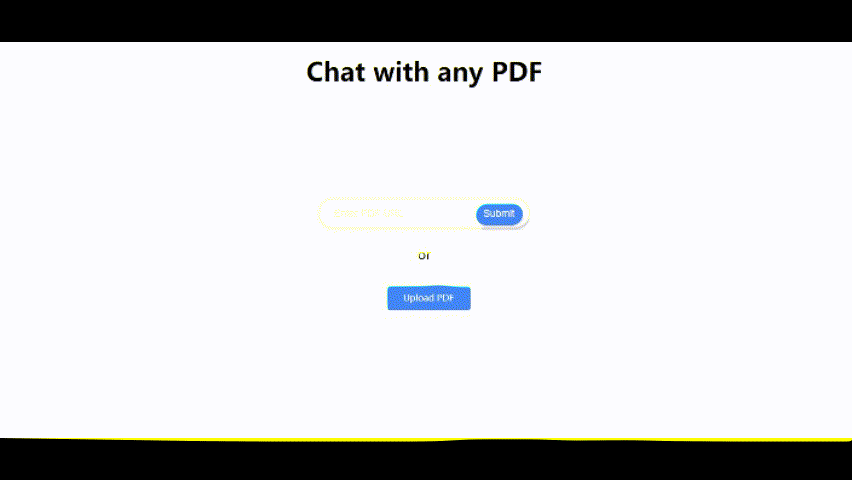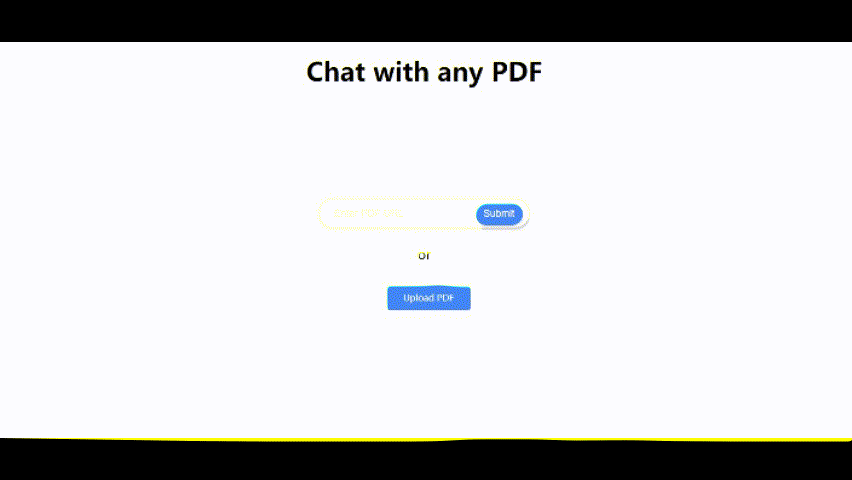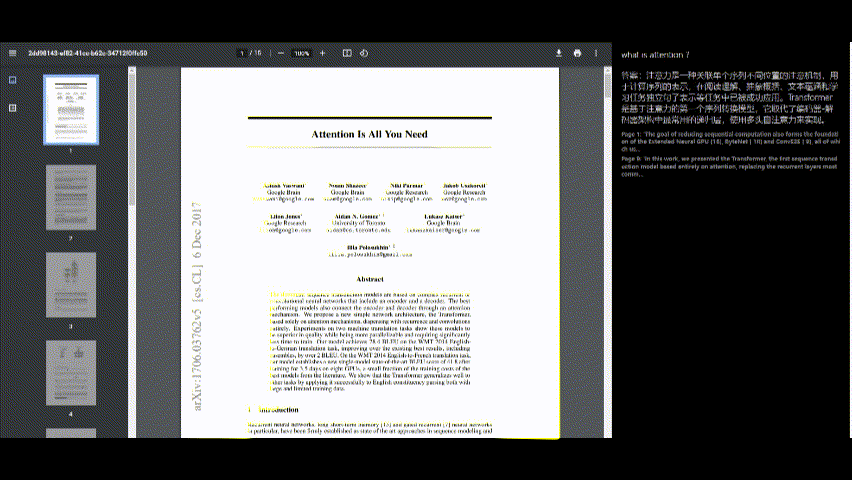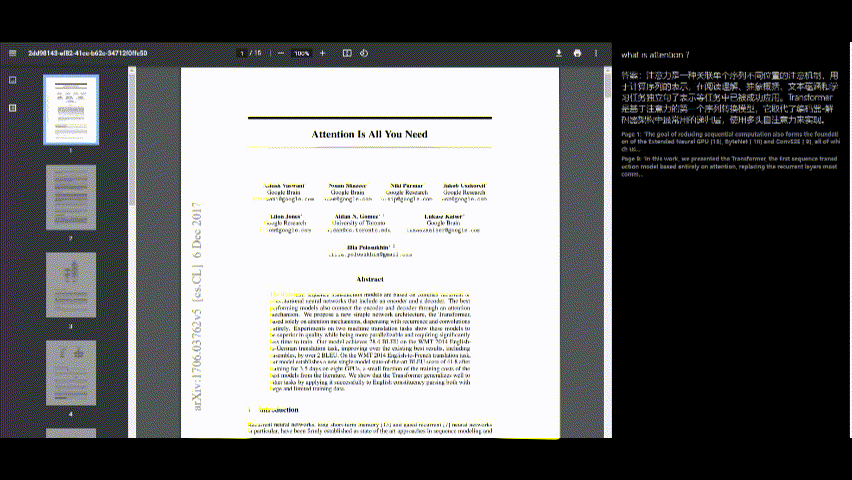
PDFと対話します
答えを表示します
言語モデルの動作は、特にChatbotクラスのcreate_promptメソッドで、 generate_embedding.py迅速な戦略を変更することでカスタマイズできます。
戦略は次のとおりです。
戦略を選択するには、 create_prompt呼び出すときにstrategyパラメーターを変更できます。
アプリケーションは現在、一部の戦略に対して中国語で回答を提供するように構成されています。プロンプトを変更して、言語を変更したり、モデルの動作を調整したりできます。
PyPDF2を使用します。これは、すべてのPDFを完全に処理しない場合があります。異常なフォーマットを備えた複雑なPDFは、正しく解析されない場合があります。貢献は大歓迎です!提案や改善がある場合は、問題を提出するか、リクエストをプルしてください。
このプロジェクトは、Apacheライセンスの下でライセンスされています。


