chatpdflike
تطبيق لجد المستندات الشامل للأسئلة باستخدام واجهات برمجة تطبيقات نموذج اللغة الكبيرة.
ملاحظة : لا ينتم هذا المشروع أو معتمد من قبل chatpdf. هذا مشروع مستقل يحاول تكرار وظائف مماثلة.
ملخص
يشبه ChatPDF هو تطبيق ويب يسمح للمستخدمين بتحميل مستندات PDF والتفاعل معهم باستخدام استعلامات اللغة الطبيعية. يعمل التطبيق على الاستفادة من نماذج اللغة الكبيرة (LLMS) مثل Turbo من Openai GPT-3.5 لفهم محتوى PDF وتقديم إجابات موجزة ودقيقة لأسئلة المستخدم.
سمات
- تحميل مستند PDF : قم بتحميل ملفات PDF المحلية أو توفير عنوان URL لمستند PDF.
- تفاعل اللغة الطبيعية : اطرح أسئلة حول محتوى PDF باللغة الطبيعية.
- الإجابات ذات الصلة : تلقي إجابات موجزة بناءً على محتوى المستند.
- مراجع المصدر : مصادر العرض (أقسام من PDF) التي تم استخدامها لإنشاء الإجابة.
- مقدمي LLM متعددين : دعم كل من نماذج Openai و Ollama.
- واجهة الويب : واجهة ويب بسيطة وبديهية مصممة مع Flask و JavaScript.
كيف تعمل
يتبع التطبيق هذه الخطوات الرئيسية:
استخراج النص والمعالجة :
- يتم تحليل PDF باستخدام
PyPDF2 . - يتم استخراج النص من كل صفحة ، ويتم تقسيم أجزاء كبيرة من النص إلى قطع يمكن التحكم فيها.
توليد التضمين :
- لكل قطعة نصية ، يتم إنشاء متجه التضمين باستخدام نموذج التضمين المحدد (على سبيل المثال ، Openai
text-embedding-ada-002 ). - تمثل هذه التضمينات المعنى الدلالي لقطاعات النص ويتم تخزينها لحسابات التشابه.
معالجة استعلام المستخدم :
- عندما يسأل المستخدم سؤالًا ، يتم إنشاء متجه التضمين للاستعلام باستخدام نفس نموذج التضمين.
البحث عن التشابه :
- يقوم التطبيق بحساب تشابه جيب التمام بين تضمين الاستعلام وتضمينات النصوص النصية.
- يتم اختيار أجزاء النص الأكثر صلة بناءً على أعلى درجات التشابه.
البناء الفوري :
- يتم إنشاء موجه لنموذج اللغة ، مما يدمج سؤال المستخدم وقطع النص الأكثر صلة.
توليد الجواب :
- يتم إرسال المطالبة إلى نموذج اللغة (على سبيل المثال ، GPT-3.5 Turbo من Openai).
- يقوم النموذج بإنشاء إجابة على سؤال المستخدم بناءً على السياق المقدم.
عرض الاستجابة :
- يتم عرض الإجابة على المستخدم في واجهة الويب.
- كما يتم توفير إشارات إلى قطع النص المصدر للشفافية.
ابدء
المتطلبات الأساسية
- Python : الإصدار 3.6 أو أعلى مطلوب.
- مفاتيح API :
- Openai API Key : مطلوب لاستخدام نماذج Openai للتضمينات وتوليد الإجابة.
- مفتاح Ollama API : اختياري. مطلوب إذا كنت ترغب في استخدام نماذج Ollama.
تثبيت
استنساخ المستودع
git clone https://github.com/Ulov888/chatpdflike.git
cd chatpdflike
تثبيت التبعيات
باستخدام pip ، قم بتثبيت الحزم المطلوبة:
pip install -r requirements.txt
مفاتيح API
لاستخدام واجهة برمجة تطبيقات Openai:
اشترك في مفتاح API في Openai.
اضبط متغير بيئة OPENAI_API_KEY :
export OPENAI_API_KEY= " your_openai_api_key "
لاستخدام واجهة برمجة تطبيقات Ollama (إذا رغبت في ذلك):
الحصول على مفتاح API من Ollama.
اضبط متغير بيئة OLLAMA_API_KEY :
export OLLAMA_API_KEY= " your_ollama_api_key "
الاستخدام
ابدأ التطبيق
قم بتشغيل تطبيق Flask:
بشكل افتراضي ، يعمل الخادم على http://0.0.0.0:8080 .
الوصول إلى واجهة الويب
افتح متصفح الويب وانتقل إلى http://localhost:8080 .
تحميل مستند PDF
يمكنك إما:
- انقر على "تحميل PDF" لتحديد ملف PDF وتحميله من جهاز الكمبيوتر الخاص بك.
- أدخل عنوان URL إلى مستند PDF وانقر فوق "إرسال".
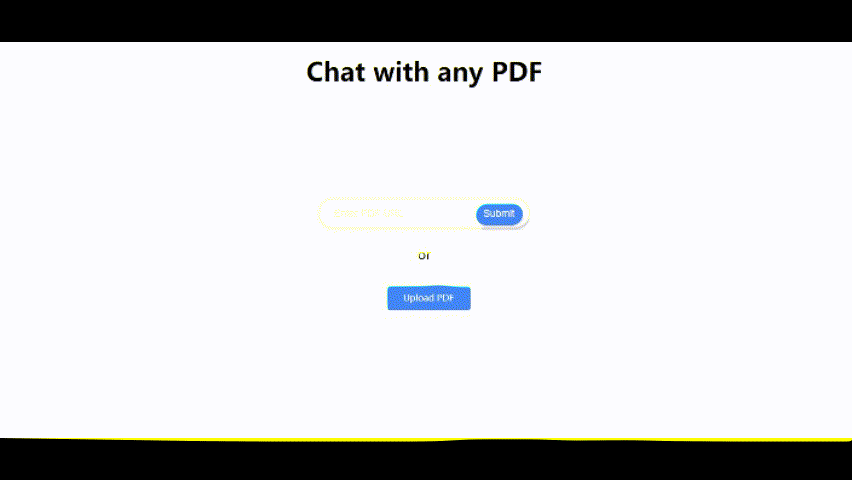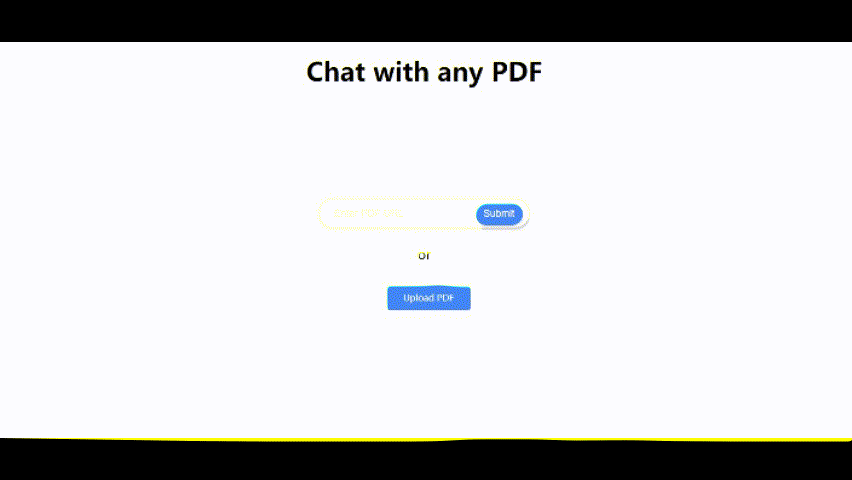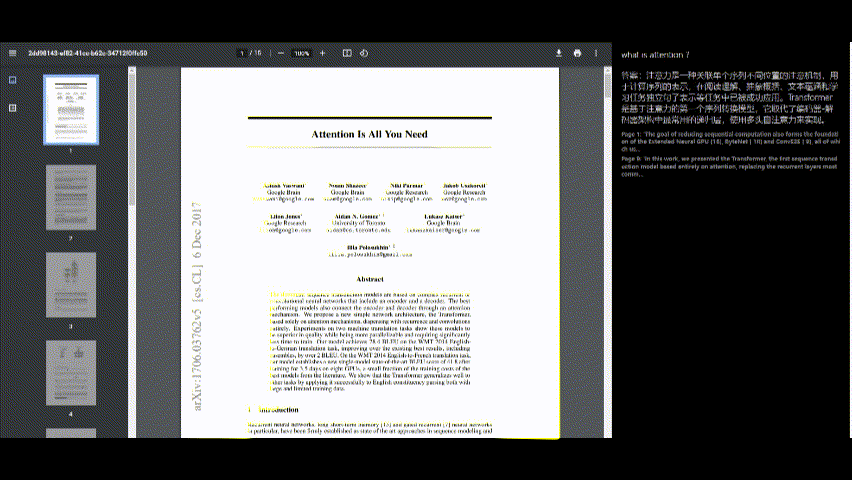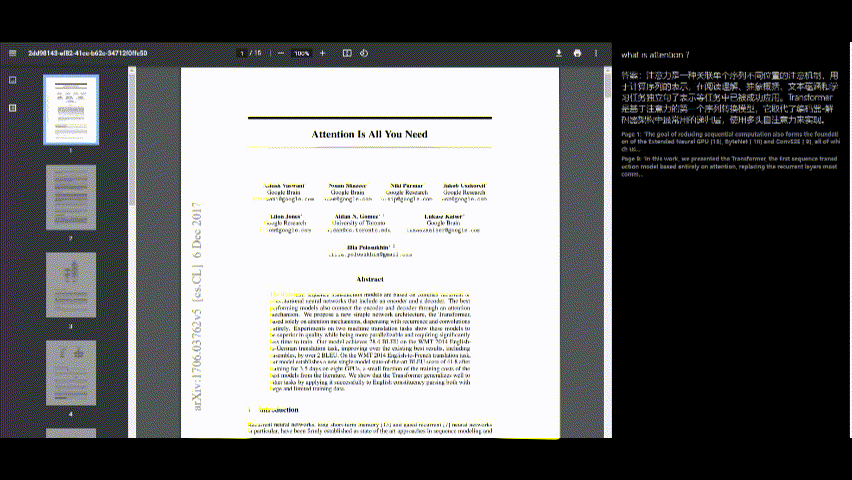
التفاعل مع PDF
- بمجرد معالجة PDF ، يمكنك طرح أسئلة حول محتواه باستخدام واجهة الدردشة على الجانب الأيمن من الشاشة.
- اكتب سؤالك في مربع الإدخال واضغط على "إرسال".
عرض الإجابات
- سيظهر رد التطبيق أسفل سؤالك.
- يتم توفير مراجع المصدر (على سبيل المثال ، أرقام الصفحات والمقتطفات) للسياق.
التخصيص
استراتيجيات سريعة
يمكن تخصيص سلوك نموذج اللغة عن طريق تعديل الاستراتيجيات المطالبة في generate_embedding.py ، وتحديداً في طريقة create_prompt لفئة Chatbot .
تشمل الاستراتيجيات:
- ورقة : لتلخيص الأوراق العلمية.
- كتيب : لتلخيص الكتيبات المالية (الإجابات باللغة الصينية).
- العقد : لفهم العقود (الإجابات باللغة الصينية).
- الافتراضي : استراتيجية للأغراض العامة (إجابات باللغة الصينية).
لتحديد استراتيجية ، يمكنك تعديل معلمة strategy عند استدعاء create_prompt .
اللغة والإخراج
تم تكوين التطبيق حاليًا لتوفير إجابات باللغة الصينية لبعض الاستراتيجيات. يمكنك تعديل المطالبات لتغيير اللغة أو ضبط سلوك النموذج.
القيود
- تكاليف Openai API : سيؤدي استخدام API من Openai إلى تكاليف على أساس الاستخدام. تأكد من مراقبة استخدام API الخاص بك لتجنب الرسوم غير المتوقعة.
- PDF Parsing : يستخدم التطبيق
PyPDF2 ، والذي قد لا يتعامل مع جميع PDFs تمامًا. قد لا يتم تحليل PDF المعقدة بتنسيق غير عادي بشكل صحيح. - حدود التضمين : قد يقيد الحد الأقصى لحد الرمز المميز للتضمينات حجم قطع النص أو الحد الأقصى لطول المطالبة.
- الاستجابات النموذجية : تعتمد جودة ودقة الإجابات على أداء نموذج اللغة وأهمية قطع النص المستردة.
المساهمة
المساهمات مرحب بها! إذا كان لديك أي اقتراحات أو تحسينات ، فلا تتردد في تقديم مشكلة أو طلب سحب.
رخصة
هذا المشروع مرخص بموجب ترخيص Apache.


