PETALface
1.0.0
Картик Нараян 1 Нитин Гопалакришнан Наир 1 Дженнифер Сюй 2 Рама Челлаппа 1 Вишал М. Патель 1
Johns Hopkins University 1 Системные и технологические исследования 2
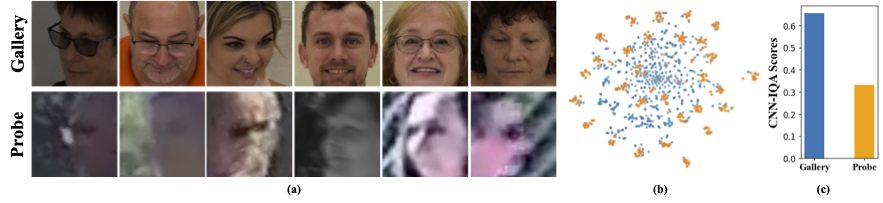
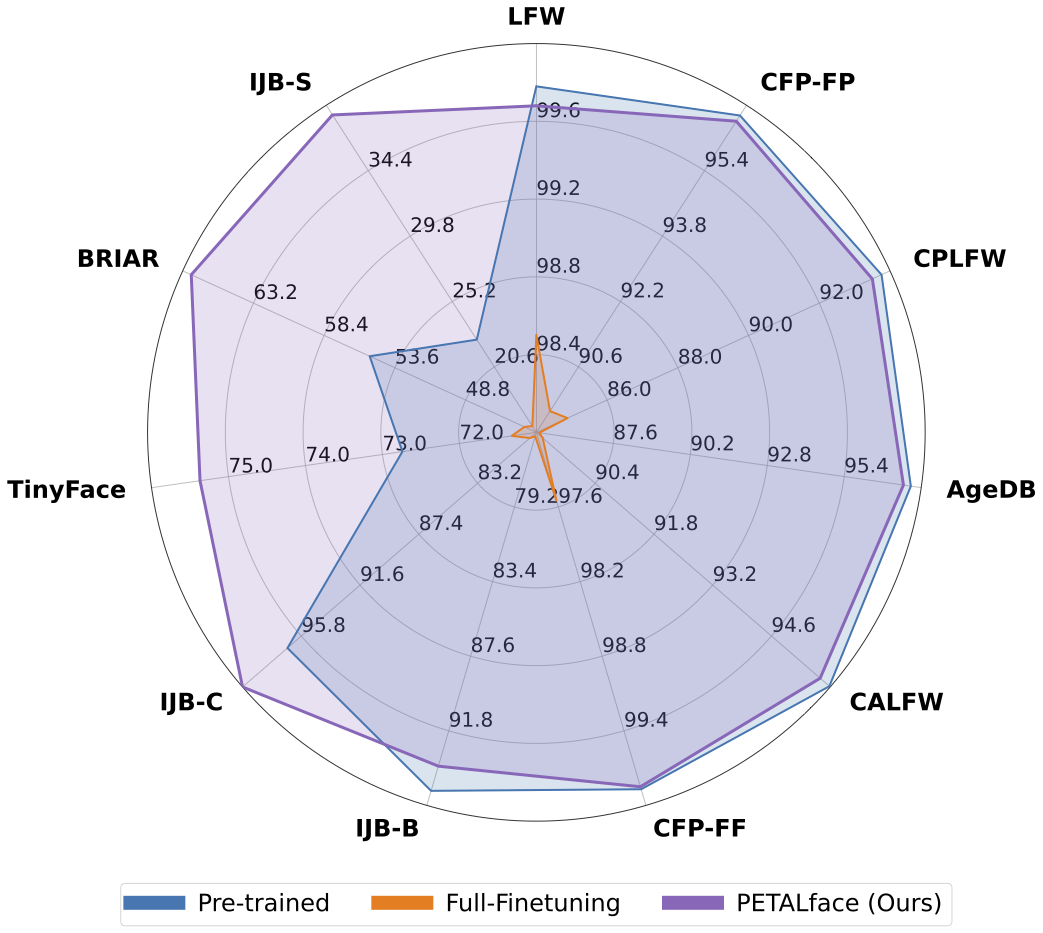
Наборы данных с низким разрешением содержат изображения с плохой ясностью, что делает трудности извлечь значимые дискриминационные особенности, необходимые для распознавания и проверки лица. Кроме того, наборы данных с низким разрешением обычно небольшие, с ограниченным количеством субъектов, поскольку их куратор требует значительного времени, усилий и инвестиций. Существующие методы заставляют изучение изображений с высоким разрешением и низким разрешением в одном энкодере, не учитывая между ними различия. Из рисунка 1 (a), 1 (b) и 1 (c) мы наблюдаем, что высококачественные изображения галереи и низкокачественные зонда относятся к отдельным доменам и требуем отдельных кодеров для извлечения значимых функций для классификации. Наивный подход к адаптации предварительно обученных моделей к наборам данных с низким разрешением контролируется полная точная настройка на этих наборах данных. Однако, как уже упоминалось, наборы данных с низким разрешением имеют небольшие размеры, и обновление модели с большим количеством параметров на небольшом наборе данных низкого разрешения приводит к плохой сходимости. Это делает модель склонной к катастрофическим забыванию, и мы видим снижение производительности на наборах данных высокого разрешения и смешанного качества, как показано на рисунке 2.
С приведенной выше мотивацией,
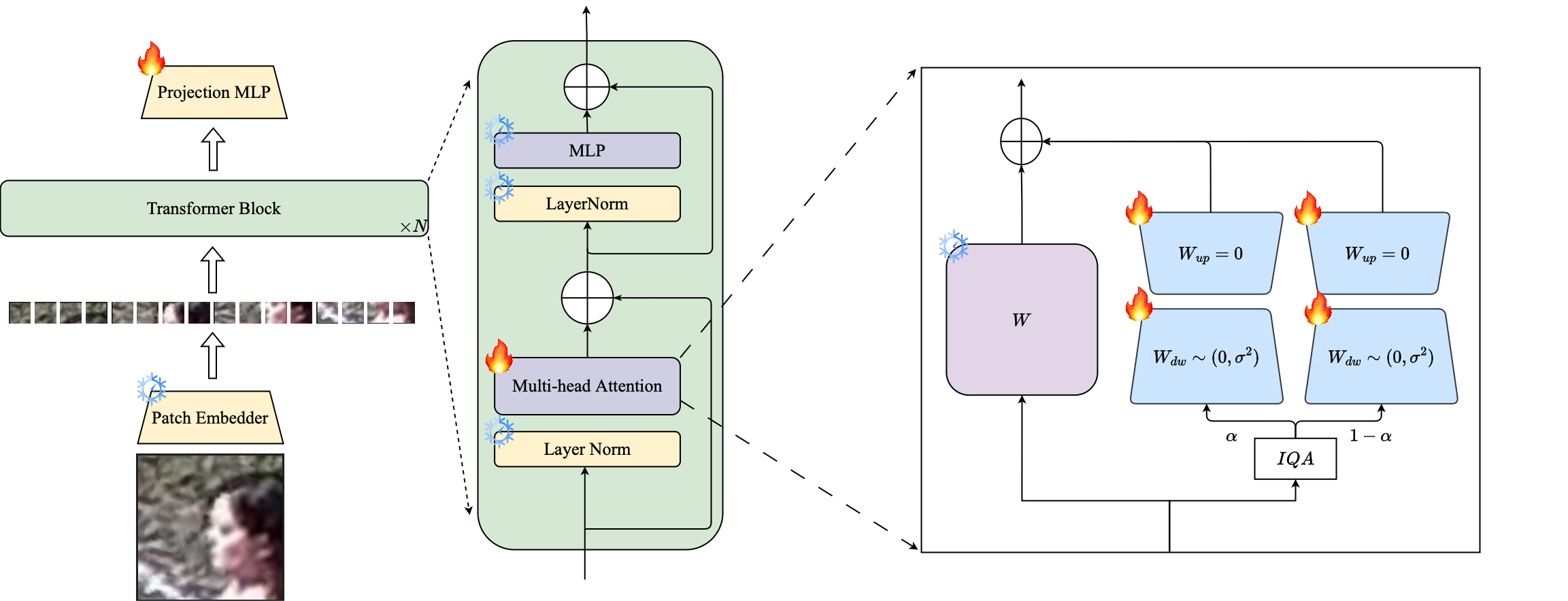
1⃣ Мы вводим использование методики Petl на основе LORA для адаптации больших предварительно обученных моделей распознавания лица к наборам данных с низким разрешением.
2⃣ Мы предлагаем взвешивание модулей LORA на основе изображений для создания отдельных прокси-энкодеров для данных с высоким разрешением и низким разрешением, обеспечивая эффективную экстракцию внедрения для распознавания лица.
3⃣ Мы демонстрируем превосходство лепестки при адаптации к наборам данных с низким разрешением, опережая другие современные модели на контрольных показателях с низким разрешением, сохраняя при этом производительность на наборах данных высокого разрешения и смешанного качества.
Аннотация: Предварительное обучение на крупномасштабных наборах данных и использование функций потерь на основе маржи очень успешны в тренировочных моделях для распознавания лиц с высоким разрешением. Тем не менее, эти модели борются с наборами данных с низким разрешением, в которых у лицах нет атрибутов лица, необходимых для различения различных лиц. Полная точная настройка на наборе данных с низким разрешением, наивный метод для адаптации модели, дает более низкую производительность из-за катастрофического забывания о предварительно обученных знаниях. Кроме того, разность доменов между изображениями галереи с высоким разрешением (HR) и изображениями зондов с низким разрешением (LR) в наборах данных с низким разрешением приводит к плохой конвергенции для одной модели, чтобы адаптироваться как к галерее, так и к зонду после тонкой настройки. С этой целью мы предлагаем PetAlface, экономичный подход к переносу для распознавания лиц с низким разрешением. Через лепесток мы пытаемся решить обе вышеупомянутые проблемы. (1) Мы решаем катастрофическое забывание, используя мощность эффективной тонкой настройки параметров (PEFT). (2) Мы вводим два модуля с низким уровнем адаптации в основную цепь, причем веса на основе входного качества изображения, чтобы учесть разницу в качеством для галереи и изображений зонда. Насколько нам известно, Petalface - это первая работа, использующая силы PEFT для распознавания с низким разрешением. Обширные эксперименты показывают, что предлагаемый метод превосходит полную точную настройку на наборах данных с низким разрешением, сохраняя при этом производительность на наборах данных высокого разрешения и смешанного качества, при этом используя только 0,48% параметров.
conda env create --file environment.yml
conda activate petalface Наборы данных могут быть загружены на их соответствующих веб -страницах или путем рассылки авторов:
Расположить набор данных следующим образом:
data /
├── BRIAR /
│ ├── train_set_1 /
│ │ ├── train . idx
│ │ ├── train . lst
│ │ └── train . rec
│ └── train_set_2 /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
├── HQ_val /
│ ├── agedb_30 . bin
│ ├── calfw . bin
│ ├── cfp_ff . bin
│ ├── cfp_fp . bin
│ ├── cplfw . bin
│ └── lfw . bin
├── ijb /
│ ├── IJB_11 . py
│ ├── IJBB /
│ ├── IJBC /
│ ├── recognition /
│ └── run . sh
├── IJBS /
│ ├── ijbs_participant_publication_consent . csv
│ ├── img /
│ ├── img . md5
│ ├── protocols /
│ ├── README . pdf
│ ├── videos /
│ ├── videos . md5
│ ├── videos_ground_truth /
│ └── videos_ground_truth . md5
├── tinyface_aligned_112 /
│ ├── Gallery_Distractor /
│ ├── Gallery_Match /
│ ├── Probe /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
├── WebFace12M /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
└── WebFace4M /
├── train . idx
├── train . lst
└── train . recМодель Pre-Traind может быть загружена вручную от HuggingFace или с использованием Python:
from huggingface_hub import hf_hub_download
# Finetuned Weights
# The filename "swin_arcface_webface4m_tinyface" indicates that the model has a swin bakcbone and pretraind
# on webface4m dataset with arcface loss function and finetuned on tinyface.
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface4m_tinyface/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m_tinyface/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m_briar/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface12m_briar/model.pt" , local_dir = "./weights" )
# Pre-trained Weights
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface4m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface12m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface12m/model.pt" , local_dir = "./weights" ) Загрузите обученные веса от HuggingFace и убедитесь, что данные загружаются с соответствующей структурой каталогов.
### BRISQUE | CosFace | TinyFace ###
NCCL_P2P_DISABLE = 1 CUDA_VISIBLE_DEVICES = 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 torchrun - - nproc_per_node = 8 - - master_port = 29190 train_iqa . py
- - network swin_256new_iqa
- - head partial_fc
- - output / mnt / store / knaraya4 / PETALface / < model_save_folder >
- - margin_list 1.0 , 0.0 , 0.4
- - batch - size 8
- - optimizer adamw
- - weight_decay 0.1
- - rec / data / knaraya4 / data / < folder_to_rec_file >
- - num_classes 2570
- - num_image 7804
- - num_epoch 50
- - lr 0.0005
- - fp16
- - warmup_epoch 2
- - image_size 120
- - use_lora
- - lora_rank 8
- - iqa brisque
- - threshold < threshold >
- - seed 19
- - load_pretrained / mnt / store / knaraya4 / PETALface / < path_to_pretrained_model >
###
# For CosFace, --margin_list 1.0,0.0,0.4; For ArcFace, --margin_list 1.0,0.5,0.0
# For BRISQUE, --iqa brisque; For CNNIQA, --iqa cnniqa; set the threshold accordingly
# For TinyFace,
# --num_classes 2570
# --num_image 7804
# --num_epoch 40
# --warmup_epoch 2
# For BRIAR,
# --num_classes 778
# --num_image 301000
# --num_epoch 10
# --warmup_epoch 1
### Обученные модели хранятся в указанном «OUPTUT».
Примечание . Обучающие сценарии для предварительной подготовки и создания Лоры представлены в лепестках/сценариях.
# Validation HQ dataset
CUDA_VISIBLE_DEVICES = 0 python validation_hq / validate_hq_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / < hq_dataset_folder >
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold threshold
# Validation Mixed Quality Dataset | IJBC
CUDA_VISIBLE_DEVICES = 0 python validation_ijb / eval_ijb_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / ijb / < ijbc_dataset_folder >
- - batch - size 1024
- - model_type swin_256new_iqa
- - target IJBC
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Mixed Quality Dataset | IJBB
CUDA_VISIBLE_DEVICES = 0 python validation_ijb / eval_ijb_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / < ijbb_dataset_folder >
- - batch - size 1024
- - model_type swin_256new_iqa
- - target IJBB
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Low-quality Dataset | TinyFace
CUDA_VISIBLE_DEVICES = 0 python validation_lq / validate_tinyface_iqa . py
- - data_root / data / knaraya4 / data
- - batch_size 512
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Low-quality Dataset | IJBS
CUDA_VISIBLE_DEVICES = 0 python validation_lq / validate_ijbs_iqa . py
- - data_root / mnt / store / knaraya4 / data / < ijbs_dataset_folder >
- - batch_size 2048
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >ПРИМЕЧАНИЕ . Сценарии вывода представлены в лепестках/сценариях.
Если вы обнаружите, что лицо лепестка полезным для вашего исследования, пожалуйста, рассмотрите возможность сослаться на нас:
@article { narayan2024petalface ,
title = { PETALface: Parameter Efficient Transfer Learning for Low-resolution Face Recognition } ,
author = { Narayan, Kartik and Nair, Nithin Gopalakrishnan and Xu, Jennifer and Chellappa, Rama and Patel, Vishal M } ,
journal = { arXiv preprint arXiv:2412.07771 } ,
year = { 2024 }
}Если у вас есть какие -либо вопросы, пожалуйста, создайте проблему в этом репозитории или свяжитесь с [email protected]


