PETALface
1.0.0
Kartik Narayan 1 Nithin Gopalakrishnan Nair 1 Jennifer Xu 2 Rama Chellappa 1 Vishal M. Patel 1
Johns Hopkins University 1 System- und Technologieforschung 2
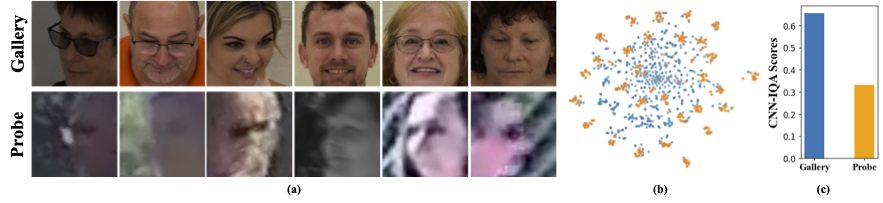
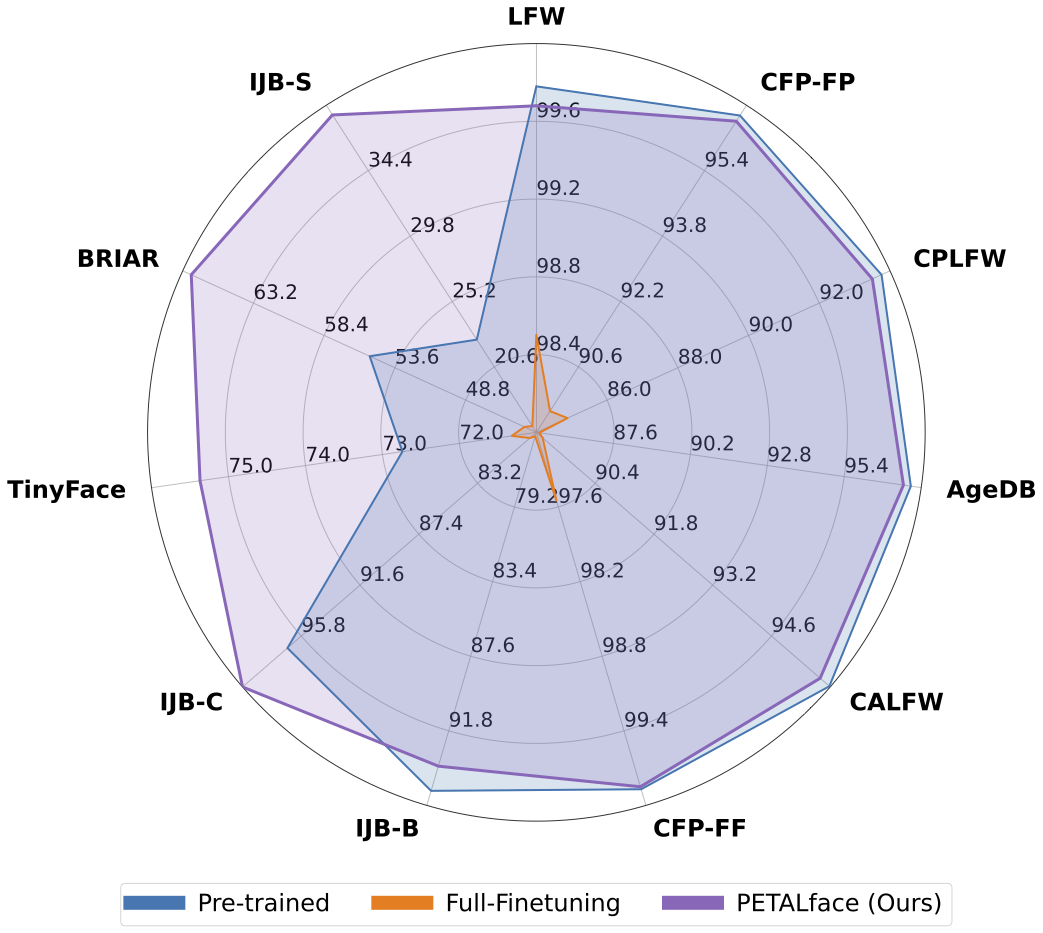
Datensätze mit niedriger Auflösung enthalten Bilder mit schlechter Klarheit, was es schwierig macht, aussagekräftige diskriminative Merkmale zu extrahieren, die für die Gesichtserkennung und -überprüfung wesentlich sind. Darüber hinaus sind Datensätze mit niedriger Auflösung in der Regel gering, wobei eine begrenzte Anzahl von Probanden, da das Kuratieren sie ansässig ist, erhebliche Zeit, Aufwand und Investition erfordert. Bestehende Methoden erzwingen das Lernen von hochauflösenden und geringen Auflösungsbildern in einem einzelnen Encoder, was die Domänenunterschiede zwischen ihnen nicht berücksichtigt. Aus Abbildung 1 (a), 1 (b) und 1 (c) beobachten wir, dass hochwertige Galeriebilder und minderwertige Sondenbilder zu verschiedenen Domänen gehören und separate Encoder benötigen, um aussagekräftige Merkmale für die Klassifizierung zu extrahieren. Ein naiver Ansatz zur Anpassung vor ausgebildeter Modelle an Datensätze mit niedriger Auflösung wird die vollständige Feinabstimmung in diesen Datensätzen überwacht. Wie bereits erwähnt, sind die Datensätze mit niedriger Auflösung jedoch gering, und die Aktualisierung eines Modells mit einer großen Anzahl von Parametern auf einem kleinen Datensatz mit geringer Auflösung führt zu einer schlechten Konvergenz. Dies macht das Modell anfällig für katastrophales Vergessen und wir sehen einen Leistungsrückgang bei hochauflösenden und gemischten Qualitätsdatensätzen, wie in Abbildung 2 gezeigt.
Mit der obigen Motivation,
1️⃣ Wir stellen die Verwendung der LORA-basierten PETL-Technik zur Anpassung großer vorgebildeter Gesichtserkennungsmodelle an Datensätze mit niedriger Auflösung ein.
2️⃣ Wir schlagen eine bildqualitätsbasierte Gewichtung von LORA-Modulen vor, um separate Proxy-Encoder für hochauflösende und geringe Auflösungsdaten zu erstellen, um eine effektive Extraktion von Einbettungen für die Gesichtserkennung sicherzustellen.
3️⃣ Wir demonstrieren die Überlegenheit der Blütenblattgesicht bei der Anpassung an Datensätze mit niedriger Auflösung und übertreffen andere hochmoderne Modelle für Benchmarks mit niedriger Auflösung und gleichzeitig die Leistung bei hochauflösenden und gemischten Qualitätsdatensätzen.
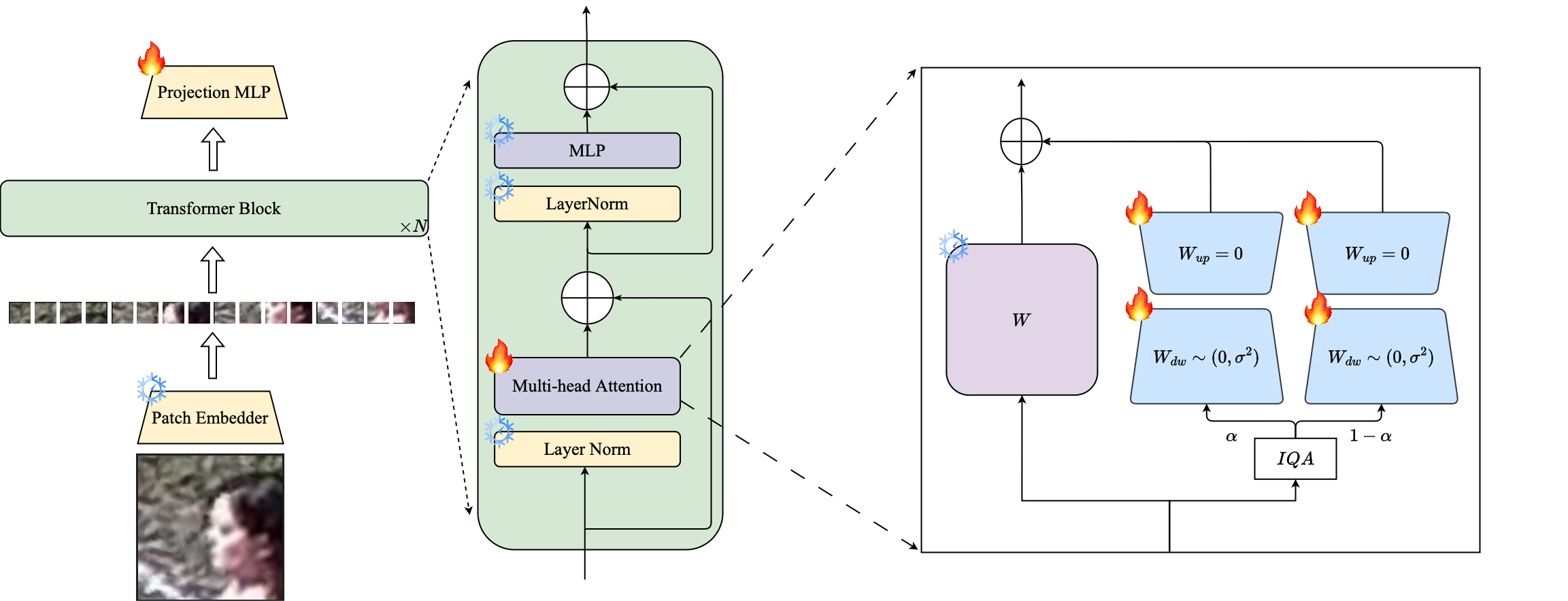
Zusammenfassung: Vorausbildung in groß angelegten Datensätzen und die Verwendung von Niederlagen auf Randbasis waren in Trainingsmodellen für hochauflösende Gesichtserkennung sehr erfolgreich. Diese Modelle haben jedoch mit geringen Auflösungsdatensätzen zu kämpfen, bei denen den Gesichtern die Gesichtsattribute fehlen, die für die Unterscheidung verschiedener Gesichter erforderlich sind. Die vollständige Feinabstimmung auf Datensätzen mit niedriger Auflösung, einer naiven Methode zum Anpassung des Modells, liefert aufgrund des katastrophalen Vergessens von vorgebildetem Wissen eine minderwertige Leistung. Zusätzlich führt der Domänenunterschied zwischen hochauflösenden Galerie-Bildern und Bildern mit niedriger Auflösung (LR) -Sondenbilder in Datensätzen mit niedriger Auflösung zu einer schlechten Konvergenz, damit ein einzelnes Modell nach der Feinabstimmung an die Galerie und die Sonde anpasst. Zu diesem Zweck schlagen wir Petalface vor, einen parametereffizienten Transferlernansatz für die Gesichtserkennung mit geringer Auflösung. Durch Petalface versuchen wir, beide oben genannten Probleme zu lösen. (1) Wir lösen katastrophales Vergessen, indem wir die Leistung der Parameter effizienten Feinabstimmung (PEFT) nutzen. (2) Wir führen zwei niedrigrangige Anpassungsmodule in das Rückgrat ein, wobei die Gewichte basierend auf der Eingangsbildqualität angepasst sind, um den Qualitätsunterschied für die Galerie- und Sondenbilder zu berücksichtigen. Nach unserem Kenntnisstand ist Petalface die erste Arbeit, die die Kräfte von PEFT für eine geringe Auflösung der Gesichtserkennung nutzt. Umfangreiche Experimente zeigen, dass die vorgeschlagene Methode die vollständige Feinabstimmung in Datensätzen mit niedriger Auflösung übertrifft und gleichzeitig die Leistung bei hochauflösenden und gemischten Datensätzen beibehält, während sie nur 0,48% der Parameter verwenden.
conda env create --file environment.yml
conda activate petalface Die Datensätze können von ihren jeweiligen Webseiten oder per Post die Autoren heruntergeladen werden:
Ordnen Sie den Datensatz auf folgende Weise an:
data /
├── BRIAR /
│ ├── train_set_1 /
│ │ ├── train . idx
│ │ ├── train . lst
│ │ └── train . rec
│ └── train_set_2 /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
├── HQ_val /
│ ├── agedb_30 . bin
│ ├── calfw . bin
│ ├── cfp_ff . bin
│ ├── cfp_fp . bin
│ ├── cplfw . bin
│ └── lfw . bin
├── ijb /
│ ├── IJB_11 . py
│ ├── IJBB /
│ ├── IJBC /
│ ├── recognition /
│ └── run . sh
├── IJBS /
│ ├── ijbs_participant_publication_consent . csv
│ ├── img /
│ ├── img . md5
│ ├── protocols /
│ ├── README . pdf
│ ├── videos /
│ ├── videos . md5
│ ├── videos_ground_truth /
│ └── videos_ground_truth . md5
├── tinyface_aligned_112 /
│ ├── Gallery_Distractor /
│ ├── Gallery_Match /
│ ├── Probe /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
├── WebFace12M /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
└── WebFace4M /
├── train . idx
├── train . lst
└── train . recDas Modell vor der Traunzierung kann manuell von Umarmungen oder Python manuell heruntergeladen werden:
from huggingface_hub import hf_hub_download
# Finetuned Weights
# The filename "swin_arcface_webface4m_tinyface" indicates that the model has a swin bakcbone and pretraind
# on webface4m dataset with arcface loss function and finetuned on tinyface.
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface4m_tinyface/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m_tinyface/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m_briar/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface12m_briar/model.pt" , local_dir = "./weights" )
# Pre-trained Weights
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface4m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface12m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface12m/model.pt" , local_dir = "./weights" ) Laden Sie die geschulten Gewichte von Suggingface herunter und stellen Sie sicher, dass die Daten mit entsprechender Verzeichnisstruktur heruntergeladen werden.
### BRISQUE | CosFace | TinyFace ###
NCCL_P2P_DISABLE = 1 CUDA_VISIBLE_DEVICES = 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 torchrun - - nproc_per_node = 8 - - master_port = 29190 train_iqa . py
- - network swin_256new_iqa
- - head partial_fc
- - output / mnt / store / knaraya4 / PETALface / < model_save_folder >
- - margin_list 1.0 , 0.0 , 0.4
- - batch - size 8
- - optimizer adamw
- - weight_decay 0.1
- - rec / data / knaraya4 / data / < folder_to_rec_file >
- - num_classes 2570
- - num_image 7804
- - num_epoch 50
- - lr 0.0005
- - fp16
- - warmup_epoch 2
- - image_size 120
- - use_lora
- - lora_rank 8
- - iqa brisque
- - threshold < threshold >
- - seed 19
- - load_pretrained / mnt / store / knaraya4 / PETALface / < path_to_pretrained_model >
###
# For CosFace, --margin_list 1.0,0.0,0.4; For ArcFace, --margin_list 1.0,0.5,0.0
# For BRISQUE, --iqa brisque; For CNNIQA, --iqa cnniqa; set the threshold accordingly
# For TinyFace,
# --num_classes 2570
# --num_image 7804
# --num_epoch 40
# --warmup_epoch 2
# For BRIAR,
# --num_classes 778
# --num_image 301000
# --num_epoch 10
# --warmup_epoch 1
### Die ausgebildeten Modelle werden in der angegebenen "OUPTUT" gespeichert.
Hinweis : Die Trainingsskripte für Vorab- und Lora -Finetuning sind in Blatt/Skripten bereitgestellt.
# Validation HQ dataset
CUDA_VISIBLE_DEVICES = 0 python validation_hq / validate_hq_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / < hq_dataset_folder >
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold threshold
# Validation Mixed Quality Dataset | IJBC
CUDA_VISIBLE_DEVICES = 0 python validation_ijb / eval_ijb_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / ijb / < ijbc_dataset_folder >
- - batch - size 1024
- - model_type swin_256new_iqa
- - target IJBC
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Mixed Quality Dataset | IJBB
CUDA_VISIBLE_DEVICES = 0 python validation_ijb / eval_ijb_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / < ijbb_dataset_folder >
- - batch - size 1024
- - model_type swin_256new_iqa
- - target IJBB
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Low-quality Dataset | TinyFace
CUDA_VISIBLE_DEVICES = 0 python validation_lq / validate_tinyface_iqa . py
- - data_root / data / knaraya4 / data
- - batch_size 512
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Low-quality Dataset | IJBS
CUDA_VISIBLE_DEVICES = 0 python validation_lq / validate_ijbs_iqa . py
- - data_root / mnt / store / knaraya4 / data / < ijbs_dataset_folder >
- - batch_size 2048
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >Hinweis : Die Inferenzskripte sind in Petalface/Skripten bereitgestellt.
Wenn Sie Blütenblattgesicht für Ihre Recherche nützlich finden, sollten Sie uns angeben:
@article { narayan2024petalface ,
title = { PETALface: Parameter Efficient Transfer Learning for Low-resolution Face Recognition } ,
author = { Narayan, Kartik and Nair, Nithin Gopalakrishnan and Xu, Jennifer and Chellappa, Rama and Patel, Vishal M } ,
journal = { arXiv preprint arXiv:2412.07771 } ,
year = { 2024 }
}Wenn Sie Fragen haben, erstellen Sie bitte ein Problem in diesem Repository oder wenden Sie sich an [email protected]


