PETALface
1.0.0
Kartik Narayan 1 Nithin Gopalakrishnan Nair 1 Jennifer Xu 2 Rama Chellappa 1 Vishal M. Patel 1
Johns Hopkins University 1 Systems and Technology Research 2
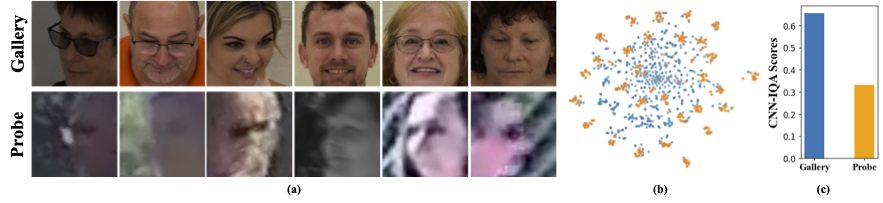
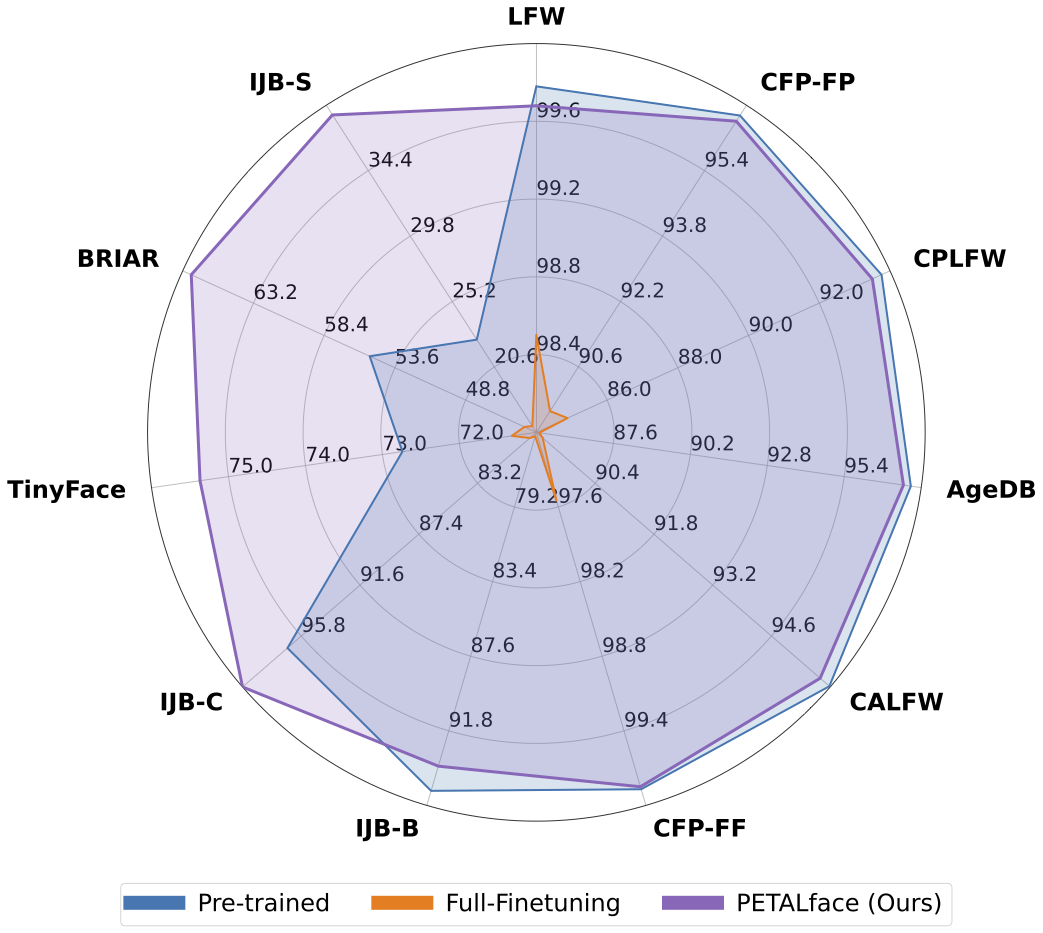
Los conjuntos de datos de baja resolución contienen imágenes con poca claridad, lo que hace que sea difícil extraer características discriminativas significativas esenciales para el reconocimiento y la verificación facial. Además, los conjuntos de datos de baja resolución suelen ser pequeños, con un número limitado de sujetos, ya que curarlos requiere un tiempo, esfuerzo e inversión significativos. Los métodos existentes forzan el aprendizaje de imágenes de cara de alta resolución y baja resolución en un solo codificador, sin dar cuenta de las diferencias de dominio entre ellas. De la Figura 1 (a), 1 (b) y 1 (c), observamos que las imágenes de la galería de alta calidad y las imágenes de la sonda de baja calidad pertenecen a dominios distintos, y requerimos codificadores separados para extraer características significativas para la clasificación. Un enfoque ingenuo para adaptar modelos previamente capacitados a conjuntos de datos de baja resolución se supervisa el ajuste completo completo en estos conjuntos de datos. Sin embargo, como se mencionó, los conjuntos de datos de baja resolución son de tamaño pequeño, y la actualización de un modelo con una gran cantidad de parámetros en un pequeño conjunto de datos de baja resolución da como resultado una convergencia deficiente. Esto hace que el modelo sea propenso al olvido catastrófico y vemos una caída en el rendimiento en conjuntos de datos de alta resolución y calidad mixta, como se muestra en la Figura 2.
Con la motivación anterior,
1ans introducimos el uso de la técnica PETL con sede en Lora para adaptar grandes modelos de reconocimiento de la cara priorratados a conjuntos de datos de baja resolución.
2minte ⃣ Proponemos una ponderación basada en la calidad de la imagen de los módulos Lora para crear codificadores proxy separados para datos de alta resolución y baja resolución, lo que garantiza una extracción efectiva de incrustaciones para el reconocimiento facial.
3️⃣ demostramos la superioridad de la cara del pétalos en la adaptación a conjuntos de datos de baja resolución, superando a otros modelos de vanguardia en puntos de referencia de baja resolución mientras se mantiene el rendimiento en conjuntos de datos de alta resolución y de calidad mixta.
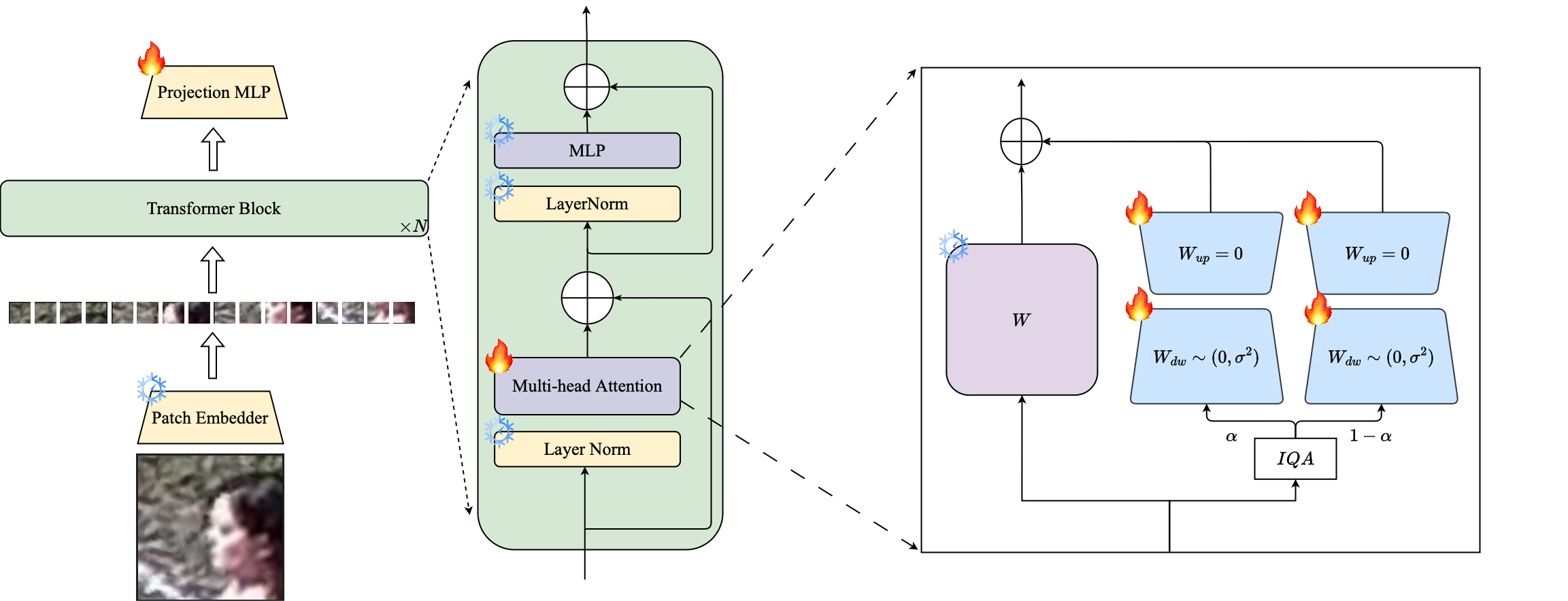
Resumen: El entrenamiento previo en conjuntos de datos a gran escala y la utilización de funciones de pérdida basadas en margen ha tenido mucho éxito en los modelos de capacitación para el reconocimiento facial de alta resolución. Sin embargo, estos modelos luchan con conjuntos de datos de cara de baja resolución, en los que las caras carecen de los atributos faciales necesarios para distinguir diferentes caras. El ajuste completo de los conjuntos de datos de baja resolución, un método ingenuo para adaptar el modelo, produce un rendimiento inferior debido al olvido catastrófico del conocimiento previamente capacitado. Además, la diferencia de dominio entre las imágenes de la galería de alta resolución (HR) y las imágenes de sonda de baja resolución (LR) en conjuntos de datos de baja resolución conducen a una convergencia deficiente para que un solo modelo se adapte tanto a la galería como a la sonda después del ajuste. Con este fin, proponemos Petalface, un enfoque de aprendizaje de transferencia de parámetros-eficiente para el reconocimiento facial de baja resolución. A través de Petalface, intentamos resolver ambos problemas antes mencionados. (1) Resolvemos el olvido catastrófico aprovechando la potencia del ajuste fino eficiente de los parámetros (PEFT). (2) Introducimos dos módulos de adaptación de bajo rango en la columna vertebral, con pesos ajustados en función de la calidad de imagen de entrada para tener en cuenta la diferencia de calidad para las imágenes de la galería y la sonda. Hasta donde sabemos, Petalface es el primer trabajo que aprovecha los poderes de PEFT para el reconocimiento facial de baja resolución. Experimentos extensos demuestran que el método propuesto supera el ajuste completo de los conjuntos de datos de baja resolución al tiempo que preserva el rendimiento en conjuntos de datos de alta resolución y calidad mixta, todo mientras usa solo el 0.48% de los parámetros.
conda env create --file environment.yml
conda activate petalface Los conjuntos de datos se pueden descargar desde sus respectivas páginas web o enviando por correo a los autores:
Organice el conjunto de datos de la siguiente manera:
data /
├── BRIAR /
│ ├── train_set_1 /
│ │ ├── train . idx
│ │ ├── train . lst
│ │ └── train . rec
│ └── train_set_2 /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
├── HQ_val /
│ ├── agedb_30 . bin
│ ├── calfw . bin
│ ├── cfp_ff . bin
│ ├── cfp_fp . bin
│ ├── cplfw . bin
│ └── lfw . bin
├── ijb /
│ ├── IJB_11 . py
│ ├── IJBB /
│ ├── IJBC /
│ ├── recognition /
│ └── run . sh
├── IJBS /
│ ├── ijbs_participant_publication_consent . csv
│ ├── img /
│ ├── img . md5
│ ├── protocols /
│ ├── README . pdf
│ ├── videos /
│ ├── videos . md5
│ ├── videos_ground_truth /
│ └── videos_ground_truth . md5
├── tinyface_aligned_112 /
│ ├── Gallery_Distractor /
│ ├── Gallery_Match /
│ ├── Probe /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
├── WebFace12M /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
└── WebFace4M /
├── train . idx
├── train . lst
└── train . recEl modelo pre-Traind se puede descargar manualmente desde Huggingface o usando Python:
from huggingface_hub import hf_hub_download
# Finetuned Weights
# The filename "swin_arcface_webface4m_tinyface" indicates that the model has a swin bakcbone and pretraind
# on webface4m dataset with arcface loss function and finetuned on tinyface.
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface4m_tinyface/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m_tinyface/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m_briar/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface12m_briar/model.pt" , local_dir = "./weights" )
# Pre-trained Weights
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface4m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface12m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface12m/model.pt" , local_dir = "./weights" ) Descargue las pesas capacitadas de Huggingface y asegúrese de que los datos se descarguen con la estructura de directorio adecuada.
### BRISQUE | CosFace | TinyFace ###
NCCL_P2P_DISABLE = 1 CUDA_VISIBLE_DEVICES = 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 torchrun - - nproc_per_node = 8 - - master_port = 29190 train_iqa . py
- - network swin_256new_iqa
- - head partial_fc
- - output / mnt / store / knaraya4 / PETALface / < model_save_folder >
- - margin_list 1.0 , 0.0 , 0.4
- - batch - size 8
- - optimizer adamw
- - weight_decay 0.1
- - rec / data / knaraya4 / data / < folder_to_rec_file >
- - num_classes 2570
- - num_image 7804
- - num_epoch 50
- - lr 0.0005
- - fp16
- - warmup_epoch 2
- - image_size 120
- - use_lora
- - lora_rank 8
- - iqa brisque
- - threshold < threshold >
- - seed 19
- - load_pretrained / mnt / store / knaraya4 / PETALface / < path_to_pretrained_model >
###
# For CosFace, --margin_list 1.0,0.0,0.4; For ArcFace, --margin_list 1.0,0.5,0.0
# For BRISQUE, --iqa brisque; For CNNIQA, --iqa cnniqa; set the threshold accordingly
# For TinyFace,
# --num_classes 2570
# --num_image 7804
# --num_epoch 40
# --warmup_epoch 2
# For BRIAR,
# --num_classes 778
# --num_image 301000
# --num_epoch 10
# --warmup_epoch 1
### Los modelos entrenados se almacenan en el "output" especificado.
Nota : Los scripts de capacitación para el preado y la finunga de Lora se proporcionan en Petalface/Scripts.
# Validation HQ dataset
CUDA_VISIBLE_DEVICES = 0 python validation_hq / validate_hq_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / < hq_dataset_folder >
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold threshold
# Validation Mixed Quality Dataset | IJBC
CUDA_VISIBLE_DEVICES = 0 python validation_ijb / eval_ijb_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / ijb / < ijbc_dataset_folder >
- - batch - size 1024
- - model_type swin_256new_iqa
- - target IJBC
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Mixed Quality Dataset | IJBB
CUDA_VISIBLE_DEVICES = 0 python validation_ijb / eval_ijb_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / < ijbb_dataset_folder >
- - batch - size 1024
- - model_type swin_256new_iqa
- - target IJBB
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Low-quality Dataset | TinyFace
CUDA_VISIBLE_DEVICES = 0 python validation_lq / validate_tinyface_iqa . py
- - data_root / data / knaraya4 / data
- - batch_size 512
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Low-quality Dataset | IJBS
CUDA_VISIBLE_DEVICES = 0 python validation_lq / validate_ijbs_iqa . py
- - data_root / mnt / store / knaraya4 / data / < ijbs_dataset_folder >
- - batch_size 2048
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >Nota : Los scripts de inferencia se proporcionan en Petalface/Scripts.
Si encuentra útil la cara de pétalos para su investigación, considere citarnos:
@article { narayan2024petalface ,
title = { PETALface: Parameter Efficient Transfer Learning for Low-resolution Face Recognition } ,
author = { Narayan, Kartik and Nair, Nithin Gopalakrishnan and Xu, Jennifer and Chellappa, Rama and Patel, Vishal M } ,
journal = { arXiv preprint arXiv:2412.07771 } ,
year = { 2024 }
}Si tiene alguna pregunta, cree un problema en este repositorio o comuníquese con [email protected]


