PETALface
1.0.0
Kartik Narayan 1 Nithin Gopalakrishnan Nair 1 Jennifer Xu 2 Rama Chellappa 1 Vishal M. Patel 1
جامعة جونز هوبكنز 1 الأنظمة وبحوث التكنولوجيا 2
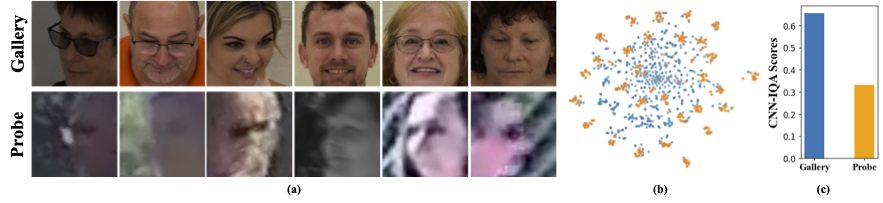
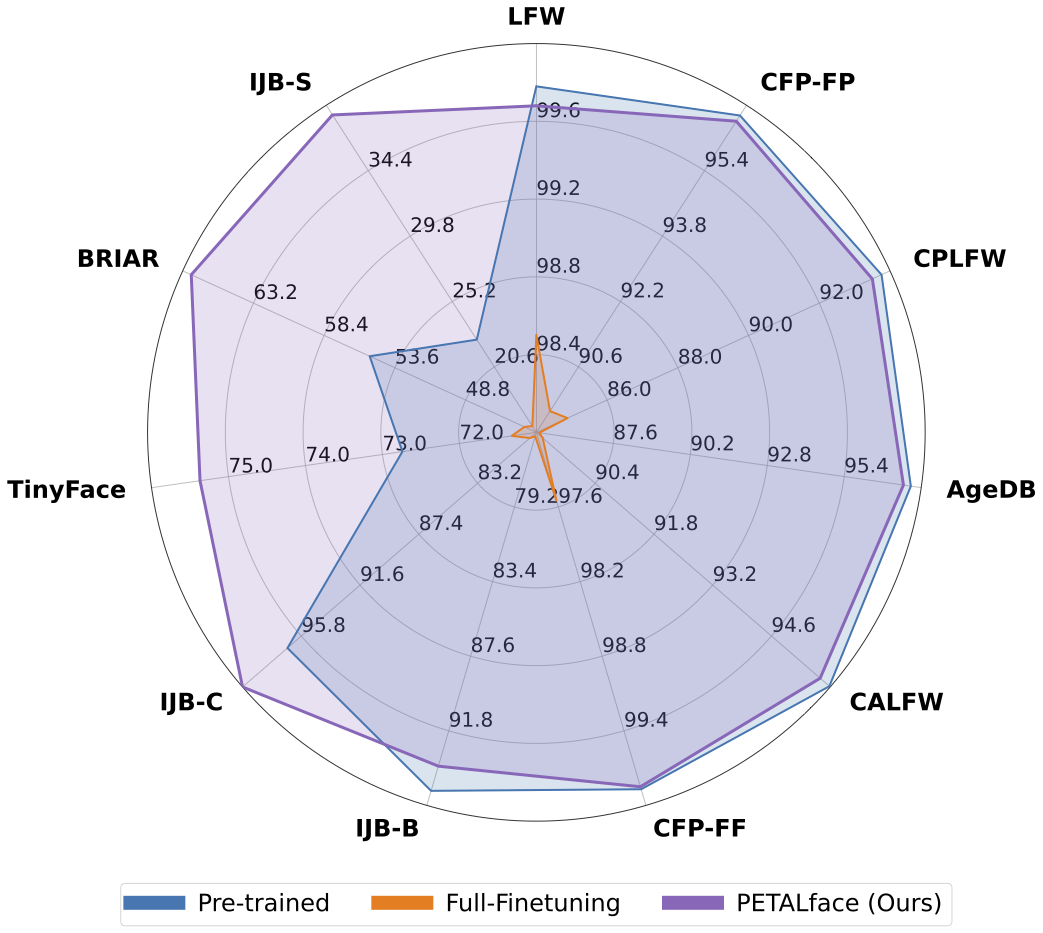
تحتوي مجموعات البيانات منخفضة الدقة على صور ذات وضوح ضعيف ، مما يجعل من الصعب استخراج ميزات تمييزية هادفة ضرورية للتعرف على الوجه والتحقق منها. علاوة على ذلك ، عادة ما تكون مجموعات البيانات منخفضة الدقة صغيرة ، مع وجود عدد محدود من الموضوعات ، حيث يتطلب تنسيقها وقتًا وجهد كبيرًا واستثمارًا. يجبر الأساليب الحالية على تعلم صور عالية الدقة ووجه منخفض الدقة في تشفير واحد ، وفشل في حساب اختلافات المجال بينهما. من الشكل 1 (أ) و 1 (ب) و 1 (ج) ، نلاحظ أن صور المعرض عالية الجودة وصور المسبار منخفضة الجودة تنتمي إلى مجالات مميزة ، وتتطلب ترميزات منفصلة لاستخراج ميزات ذات معنى للتصنيف. يتم الإشراف على النهج الساذج لتكييف النماذج التي تم تدريبها مسبقًا مع مجموعات البيانات منخفضة الدقة في صقل كامل على مجموعات البيانات هذه. ومع ذلك ، كما ذكرنا ، فإن مجموعات البيانات ذات الدقة منخفضة الحجم صغيرة الحجم ، وتحديث نموذج مع عدد كبير من المعلمات على مجموعة بيانات صغيرة منخفضة الدقة يؤدي إلى ضعف التقارب. هذا يجعل النموذج عرضة للنسيان الكارثي ونرى انخفاضًا في الأداء على مجموعات بيانات عالية الدقة وجودة مختلطة ، كما هو موضح في الشكل 2.
مع الدافع أعلاه ،
1-نقدم استخدام تقنية PETL المستندة إلى LORA لتكييف نماذج التعرف على الوجه قبل التدريب على مجموعات بيانات منخفضة الدقة.
2⃣ نقترح الترجيح القائم على جودة الصورة لوحدات LORA لإنشاء ترميزات بروكسي منفصلة للبيانات ذات الدقة العالية والمنخفضة الدقة ، مما يضمن استخراج فعال من التضمينات للتعرف على الوجه.
3⃣ نوضح تفوق الوجه بتلة في التكيف مع مجموعات البيانات منخفضة الدقة ، والتفوق على النماذج الحديثة الأخرى على المعايير منخفضة الدقة مع الحفاظ على الأداء على مجموعات البيانات عالية الدقة وجودة المختلطة.
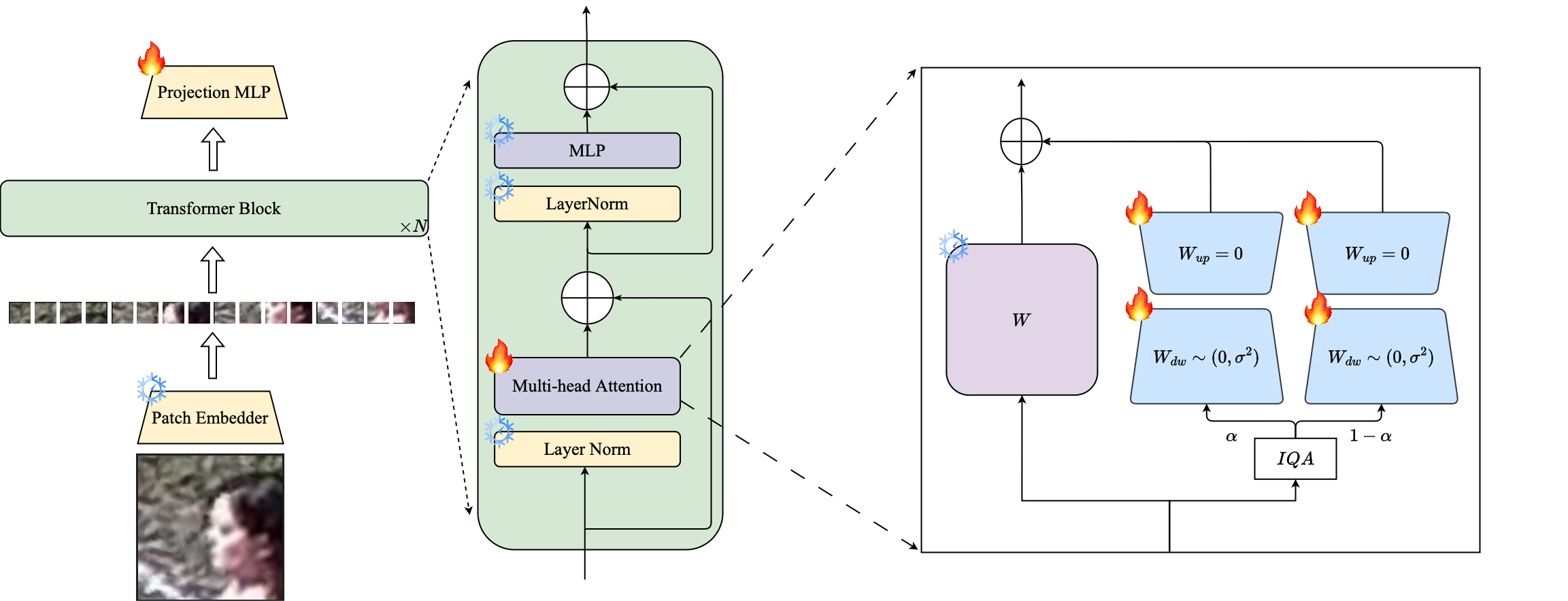
الخلاصة: كان التدريب المسبق على مجموعات البيانات واسعة النطاق واستخدام وظائف الخسارة القائمة على الهامش ناجحة للغاية في نماذج التدريب للتعرف على الوجه عالي الدقة. ومع ذلك ، فإن هذه النماذج تكافح مع مجموعات بيانات الوجه منخفضة الدقة ، حيث تفتقر الوجوه إلى سمات الوجه اللازمة للتمييز بين الوجوه المختلفة. إن التكييف الكامل على مجموعات البيانات منخفضة الدقة ، وهي طريقة ساذجة لتكييف النموذج ، تعطي أداءً أدنى بسبب نسيان الكارثي للمعرفة التي تم تدريبها مسبقًا. بالإضافة إلى ذلك ، يؤدي اختلاف المجال بين صور المعرض عالية الدقة (HR) والصور المنخفضة الدقة (LR) في مجموعات البيانات ذات الدقة المنخفضة إلى تقارب ضعيف لنموذج واحد للتكيف مع كل من المعرض والتحقيق بعد الضبط الدقيق. تحقيقًا لهذه الغاية ، نقترح Petalface ، وهو نهج التعلم الناقل الفعال للمعلمة للتعرف على الوجه منخفض الدقة. من خلال Petalface ، نحاول حل كل من المشاكل المذكورة أعلاه. (1) نقوم بحل نسيان الكارثي من خلال الاستفادة من قوة الضبط الدقيق الفعال للمعلمة (PEFT). (2) نقدم وحدتين للتكيف منخفضة الرتبة إلى العمود الفقري ، مع تعديل الأوزان استنادًا إلى جودة صورة الإدخال لحساب الفرق في الجودة لصور المعرض والتحقيق. على حد علمنا ، فإن Petalface هو أول عمل يستفيد من صلاحيات PEFT للتعرف على الوجه منخفض الدقة. توضح التجارب المكثفة أن الطريقة المقترحة تتفوق على صقل كامل على مجموعات البيانات منخفضة الدقة مع الحفاظ على الأداء على مجموعات البيانات عالية الدقة والجودة ، كل ذلك مع استخدام 0.48 ٪ فقط من المعلمات.
conda env create --file environment.yml
conda activate petalface يمكن تنزيل مجموعات البيانات من صفحات الويب الخاصة بكل منهما أو عن طريق إرسال البريدين للمؤلفين:
ترتيب مجموعة البيانات بالطريقة التالية:
data /
├── BRIAR /
│ ├── train_set_1 /
│ │ ├── train . idx
│ │ ├── train . lst
│ │ └── train . rec
│ └── train_set_2 /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
├── HQ_val /
│ ├── agedb_30 . bin
│ ├── calfw . bin
│ ├── cfp_ff . bin
│ ├── cfp_fp . bin
│ ├── cplfw . bin
│ └── lfw . bin
├── ijb /
│ ├── IJB_11 . py
│ ├── IJBB /
│ ├── IJBC /
│ ├── recognition /
│ └── run . sh
├── IJBS /
│ ├── ijbs_participant_publication_consent . csv
│ ├── img /
│ ├── img . md5
│ ├── protocols /
│ ├── README . pdf
│ ├── videos /
│ ├── videos . md5
│ ├── videos_ground_truth /
│ └── videos_ground_truth . md5
├── tinyface_aligned_112 /
│ ├── Gallery_Distractor /
│ ├── Gallery_Match /
│ ├── Probe /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
├── WebFace12M /
│ ├── train . idx
│ ├── train . lst
│ └── train . rec
└── WebFace4M /
├── train . idx
├── train . lst
└── train . recيمكن تنزيل نموذج ما قبل الأسطوانة يدويًا من Huggingface أو باستخدام Python:
from huggingface_hub import hf_hub_download
# Finetuned Weights
# The filename "swin_arcface_webface4m_tinyface" indicates that the model has a swin bakcbone and pretraind
# on webface4m dataset with arcface loss function and finetuned on tinyface.
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface4m_tinyface/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m_tinyface/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m_briar/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface12m_briar/model.pt" , local_dir = "./weights" )
# Pre-trained Weights
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface4m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface4m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_arcface_webface12m/model.pt" , local_dir = "./weights" )
hf_hub_download ( repo_id = "kartiknarayan/PETALface" , filename = "swin_cosface_webface12m/model.pt" , local_dir = "./weights" ) قم بتنزيل الأوزان المدربة من Huggingface وتأكد من تنزيل البيانات بهيكل الدليل المناسب.
### BRISQUE | CosFace | TinyFace ###
NCCL_P2P_DISABLE = 1 CUDA_VISIBLE_DEVICES = 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 torchrun - - nproc_per_node = 8 - - master_port = 29190 train_iqa . py
- - network swin_256new_iqa
- - head partial_fc
- - output / mnt / store / knaraya4 / PETALface / < model_save_folder >
- - margin_list 1.0 , 0.0 , 0.4
- - batch - size 8
- - optimizer adamw
- - weight_decay 0.1
- - rec / data / knaraya4 / data / < folder_to_rec_file >
- - num_classes 2570
- - num_image 7804
- - num_epoch 50
- - lr 0.0005
- - fp16
- - warmup_epoch 2
- - image_size 120
- - use_lora
- - lora_rank 8
- - iqa brisque
- - threshold < threshold >
- - seed 19
- - load_pretrained / mnt / store / knaraya4 / PETALface / < path_to_pretrained_model >
###
# For CosFace, --margin_list 1.0,0.0,0.4; For ArcFace, --margin_list 1.0,0.5,0.0
# For BRISQUE, --iqa brisque; For CNNIQA, --iqa cnniqa; set the threshold accordingly
# For TinyFace,
# --num_classes 2570
# --num_image 7804
# --num_epoch 40
# --warmup_epoch 2
# For BRIAR,
# --num_classes 778
# --num_image 301000
# --num_epoch 10
# --warmup_epoch 1
### يتم تخزين النماذج المدربة في "ouptut" المحددة.
ملاحظة : يتم توفير البرامج النصية التدريبية للتدريب المسبق و Lora Finetuning في Petalface/البرامج النصية.
# Validation HQ dataset
CUDA_VISIBLE_DEVICES = 0 python validation_hq / validate_hq_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / < hq_dataset_folder >
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold threshold
# Validation Mixed Quality Dataset | IJBC
CUDA_VISIBLE_DEVICES = 0 python validation_ijb / eval_ijb_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / ijb / < ijbc_dataset_folder >
- - batch - size 1024
- - model_type swin_256new_iqa
- - target IJBC
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Mixed Quality Dataset | IJBB
CUDA_VISIBLE_DEVICES = 0 python validation_ijb / eval_ijb_iqa . py
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - data_root / data / knaraya4 / data / < ijbb_dataset_folder >
- - batch - size 1024
- - model_type swin_256new_iqa
- - target IJBB
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Low-quality Dataset | TinyFace
CUDA_VISIBLE_DEVICES = 0 python validation_lq / validate_tinyface_iqa . py
- - data_root / data / knaraya4 / data
- - batch_size 512
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >
# Validation Low-quality Dataset | IJBS
CUDA_VISIBLE_DEVICES = 0 python validation_lq / validate_ijbs_iqa . py
- - data_root / mnt / store / knaraya4 / data / < ijbs_dataset_folder >
- - batch_size 2048
- - model_load_path / mnt / store / knaraya4 / PETALface / < folder_name > / model . pt
- - model_type swin_256new_iqa
- - image_size 120
- - lora_rank 8
- - use_lora
- - iqa cnniqa
- - threshold < threshold >ملاحظة : يتم توفير البرامج النصية للاستدلال في Petalface/النصوص.
إذا وجدت وجه بتلة مفيدًا لبحثك ، فيرجى التفكير في الاستشهاد بنا:
@article { narayan2024petalface ,
title = { PETALface: Parameter Efficient Transfer Learning for Low-resolution Face Recognition } ,
author = { Narayan, Kartik and Nair, Nithin Gopalakrishnan and Xu, Jennifer and Chellappa, Rama and Patel, Vishal M } ,
journal = { arXiv preprint arXiv:2412.07771 } ,
year = { 2024 }
}إذا كان لديك أي أسئلة ، يرجى إنشاء مشكلة على هذا المستودع أو الاتصال على [email protected]


