FastPitchFormant
v1.0.0
Реализация Pytorch FastPitchFormant: разлагаемое моделирование на основе исходного фильтра для синтеза речи.
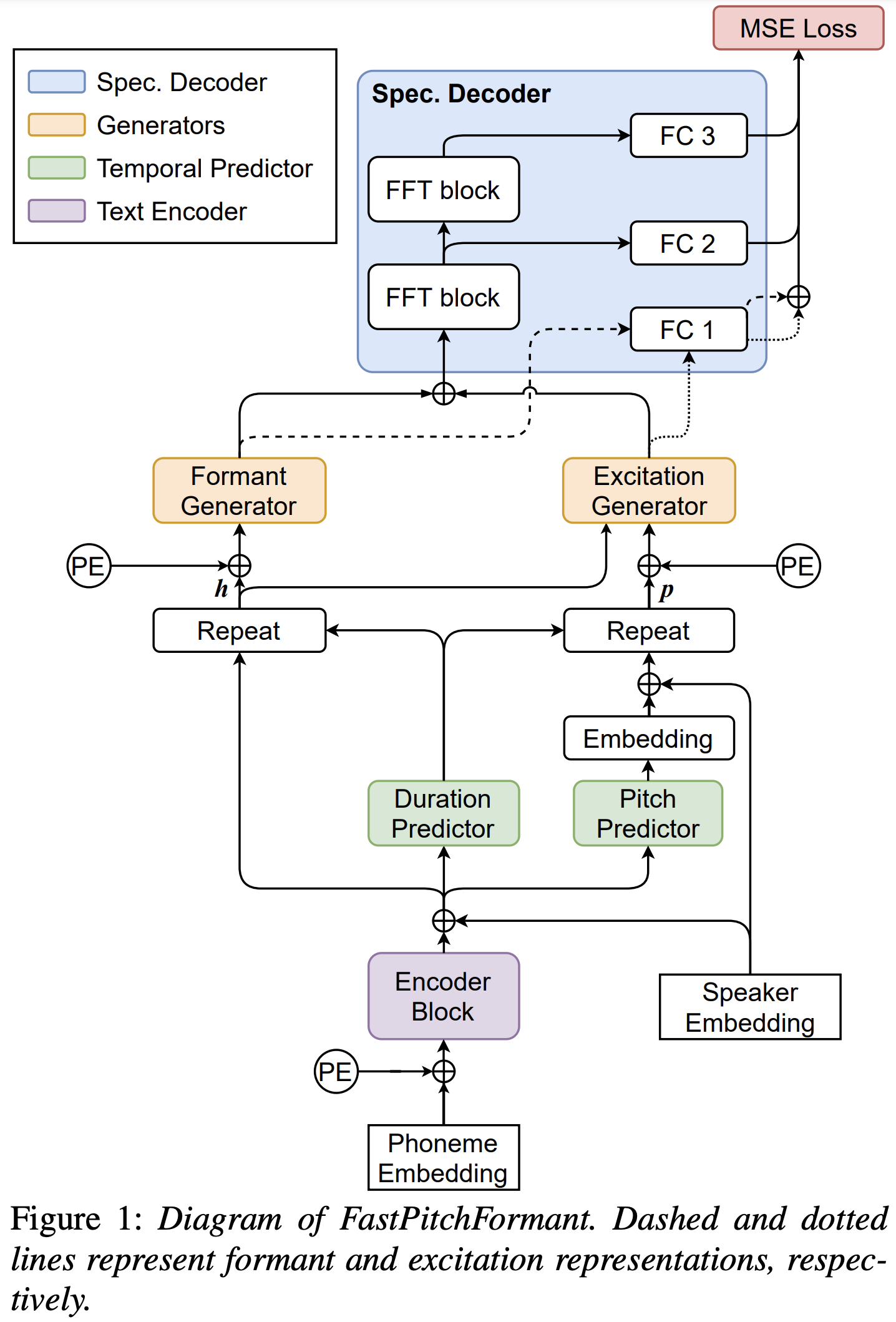
Вы можете установить зависимости Python с
pip3 install -r requirements.txt
Вы должны загрузить предварительно подготовленные модели и поместить их в output/ckpt/LJSpeech/ .
Для английских однополосных TTS, бегите
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 600000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Сгенерированные высказывания будут помещены в output/result/ .
Пакетный вывод также поддерживается, попробуйте
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 600000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
синтезировать все высказывания в preprocessed_data/LJSpeech/val.txt
Скорость шага/разговора синтезированных высказываний может контролироваться путем указания желаемых соотношений шага/энергии/продолжительности. Например, можно увеличить скорость разговора на 20 % и уменьшить шаг на 20 % на
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 600000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml --duration_control 0.8 --pitch_control 0.8
Поддерживаемые наборы данных
Сначала беги
python3 prepare_align.py config/LJSpeech/preprocess.yaml
для некоторых приготовлений.
Как описано в статье, Montreal принудительный Aligner (MFA) используется для получения выравнивания между высказываниями и последовательностями фонем. Выравнивания для наборов данных LJSPEECH представлены здесь. Вы должны разаржать файлы в preprocessed_data/LJSpeech/TextGrid/ .
После этого запустите сценарий предварительной обработки
python3 preprocess.py config/LJSpeech/preprocess.yaml
С другой стороны, вы можете выровнять корпус самостоятельно. Загрузите официальный пакет MFA и запустите
./montreal-forced-aligner/bin/mfa_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt english preprocessed_data/LJSpeech
или
./montreal-forced-aligner/bin/mfa_train_and_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt preprocessed_data/LJSpeech
Чтобы выровнять корпус, а затем запустить сценарий предварительной обработки.
python3 preprocess.py config/LJSpeech/preprocess.yaml
Тренировать свою модель с
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Использовать
tensorboard --logdir output/log/LJSpeech
Подавать в Tensorboard на вашем местном хосте. Кривые потерь, синтезированные мель-спектрограммы и аудио показаны.
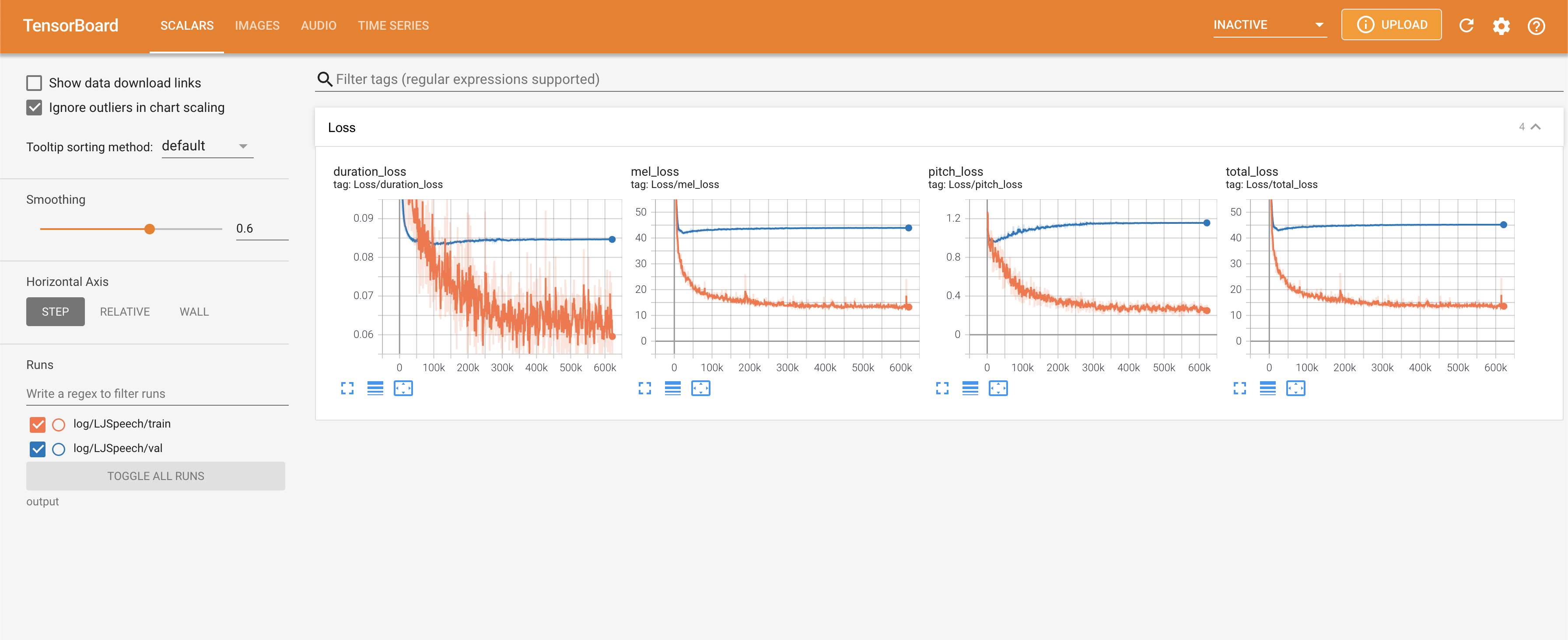
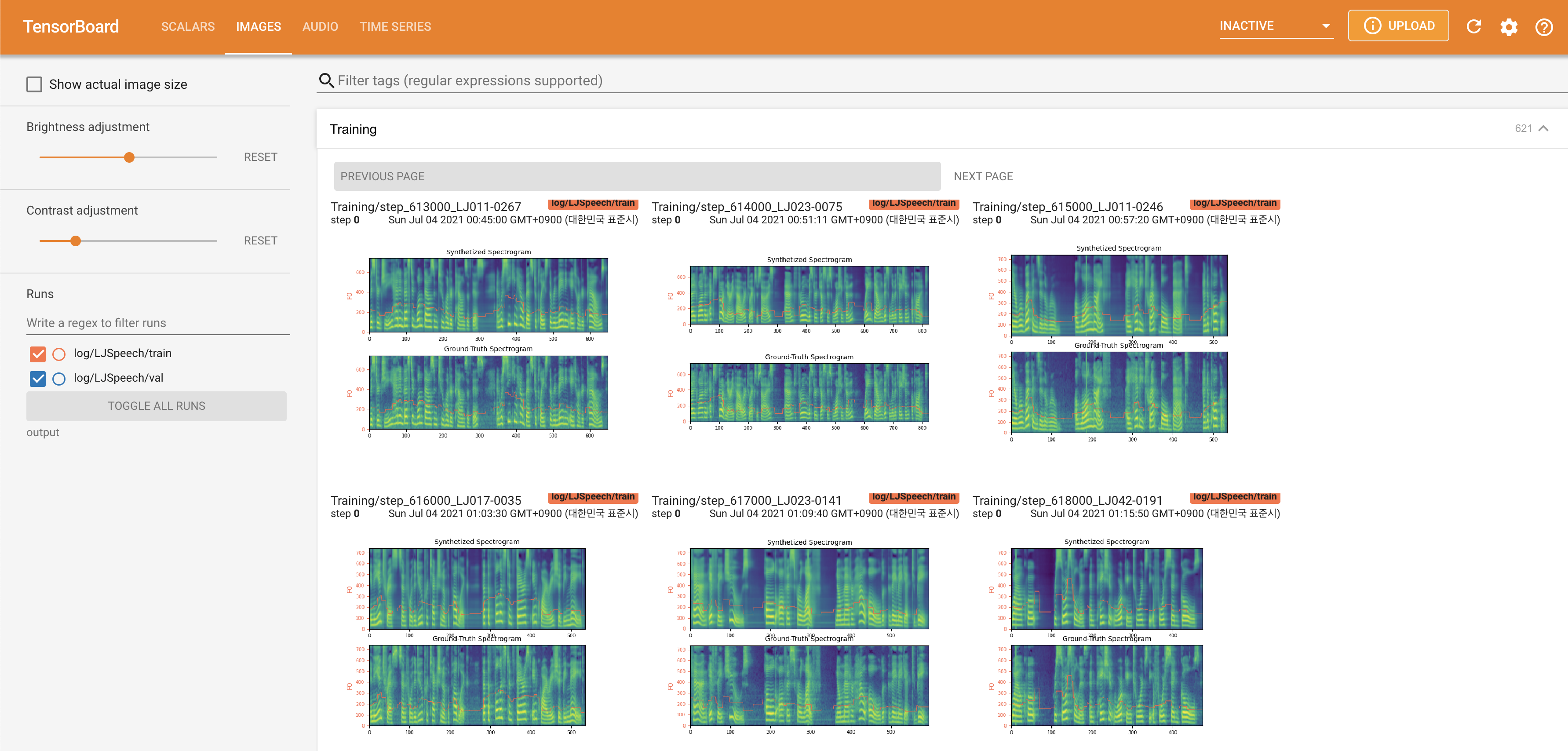
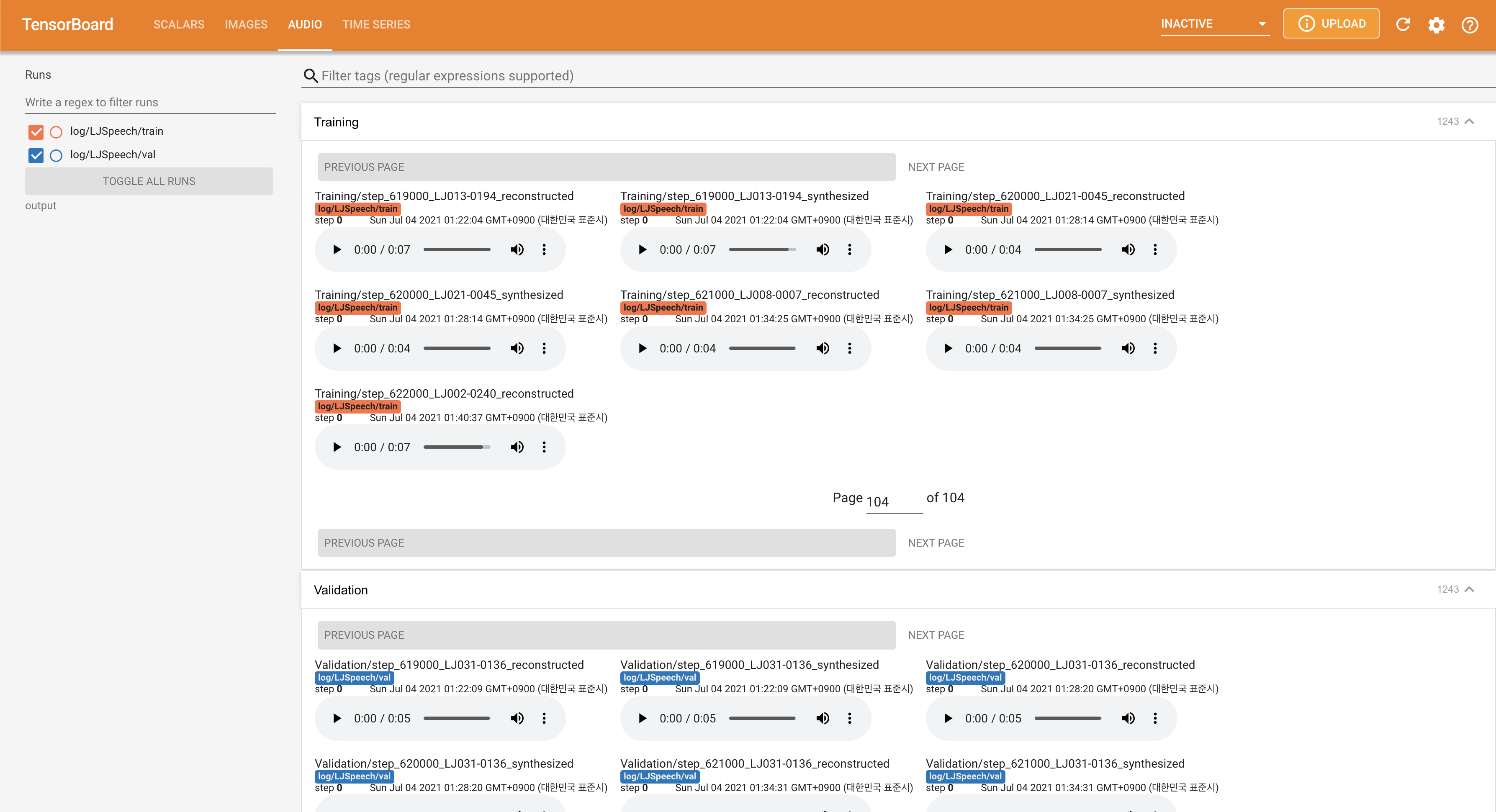
normalization в False In ./config/LJSpeech/preprocess.yaml , когда вам нужно увидеть больше широкого диапазона высоты тона, как описана статья. @misc{lee2021fastpitchformant,
author = {Lee, Keon},
title = {FastPitchFormant},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/FastPitchFormant}}
}


