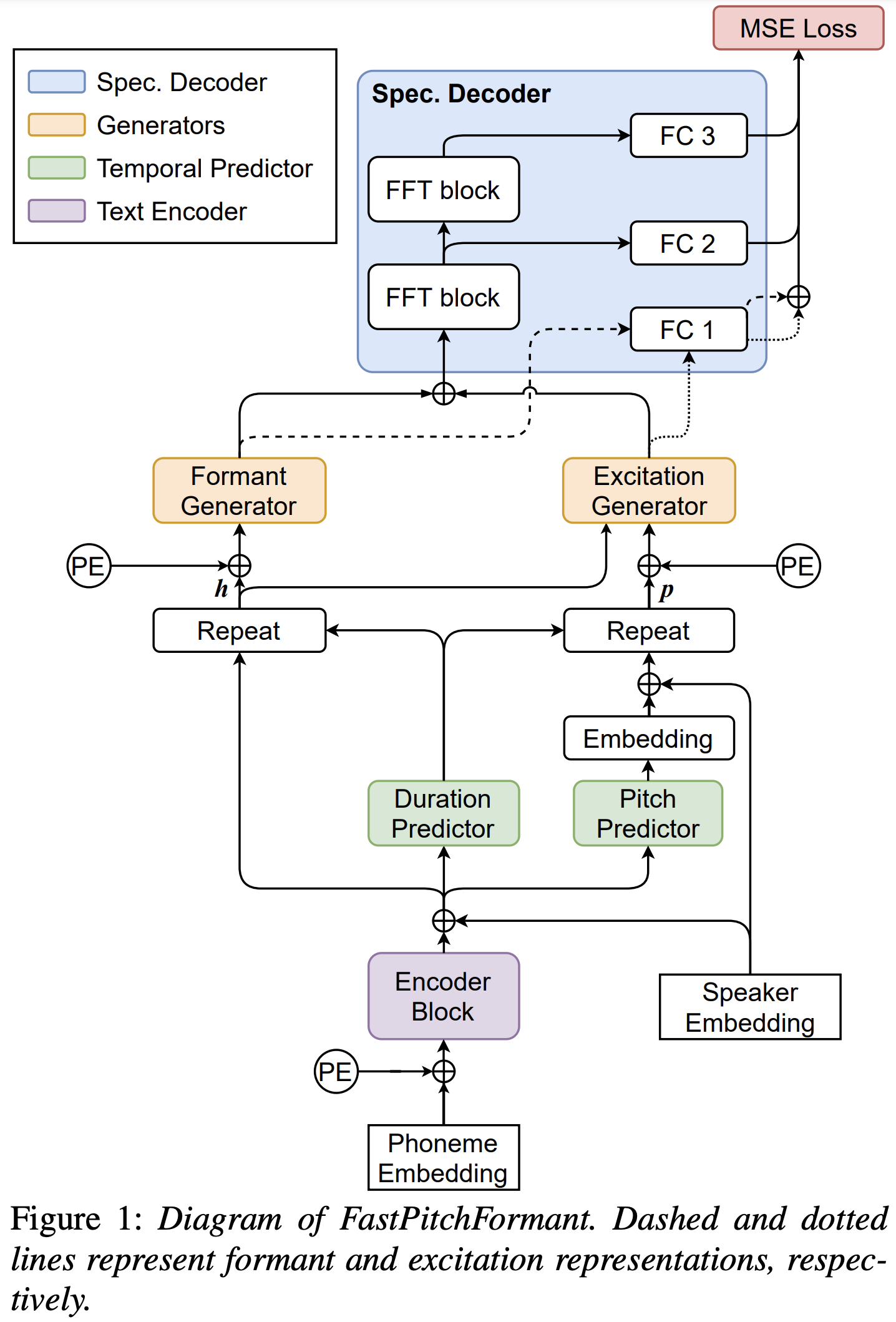
FastPitchFormant
v1.0.0
Implémentation Pytorch de FastPitchformant: modélisation décomposée basée sur les filtres source pour la synthèse de la parole.
Vous pouvez installer les dépendances Python avec
pip3 install -r requirements.txt
Vous devez télécharger les modèles pré-entraînés et les mettre en output/ckpt/LJSpeech/ .
Pour les TTS à haut-parleur anglais, courez
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 600000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Les énoncés générés seront placés en output/result/ .
L'inférence par lots est également prise en charge, essayez
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 600000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Pour synthétiser toutes les énoncés dans preprocessed_data/LJSpeech/val.txt
Le taux de hauteur / parlante des énoncés synthétisés peut être contrôlé en spécifiant les ratios de pitch / énergie / durée souhaités. Par exemple, on peut augmenter le taux de parole de 20% et diminuer le terrain de 20% par
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 600000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml --duration_control 0.8 --pitch_control 0.8
Les ensembles de données pris en charge sont
Tout d'abord, courez
python3 prepare_align.py config/LJSpeech/preprocess.yaml
pour certaines préparatifs.
Comme décrit dans l'article, l'aligneur forcé de Montréal (MFA) est utilisé pour obtenir les alignements entre les énoncés et les séquences de phonèmes. Les alignements pour les ensembles de données LJSPEECH sont fournis ici. Vous devez décompresser les fichiers dans preprocessed_data/LJSpeech/TextGrid/ .
Après cela, exécutez le script de prétraitement par
python3 preprocess.py config/LJSpeech/preprocess.yaml
Alternativement, vous pouvez aligner le corpus par vous-même. Téléchargez le package MFA officiel et exécutez
./montreal-forced-aligner/bin/mfa_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt english preprocessed_data/LJSpeech
ou
./montreal-forced-aligner/bin/mfa_train_and_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt preprocessed_data/LJSpeech
Pour aligner le corpus, puis exécutez le script de prétraitement.
python3 preprocess.py config/LJSpeech/preprocess.yaml
Former votre modèle avec
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Utiliser
tensorboard --logdir output/log/LJSpeech
pour servir Tensorboard sur votre hôte local. Les courbes de perte, les spectrogrammes de MEL synthétisés et les audios sont affichés.
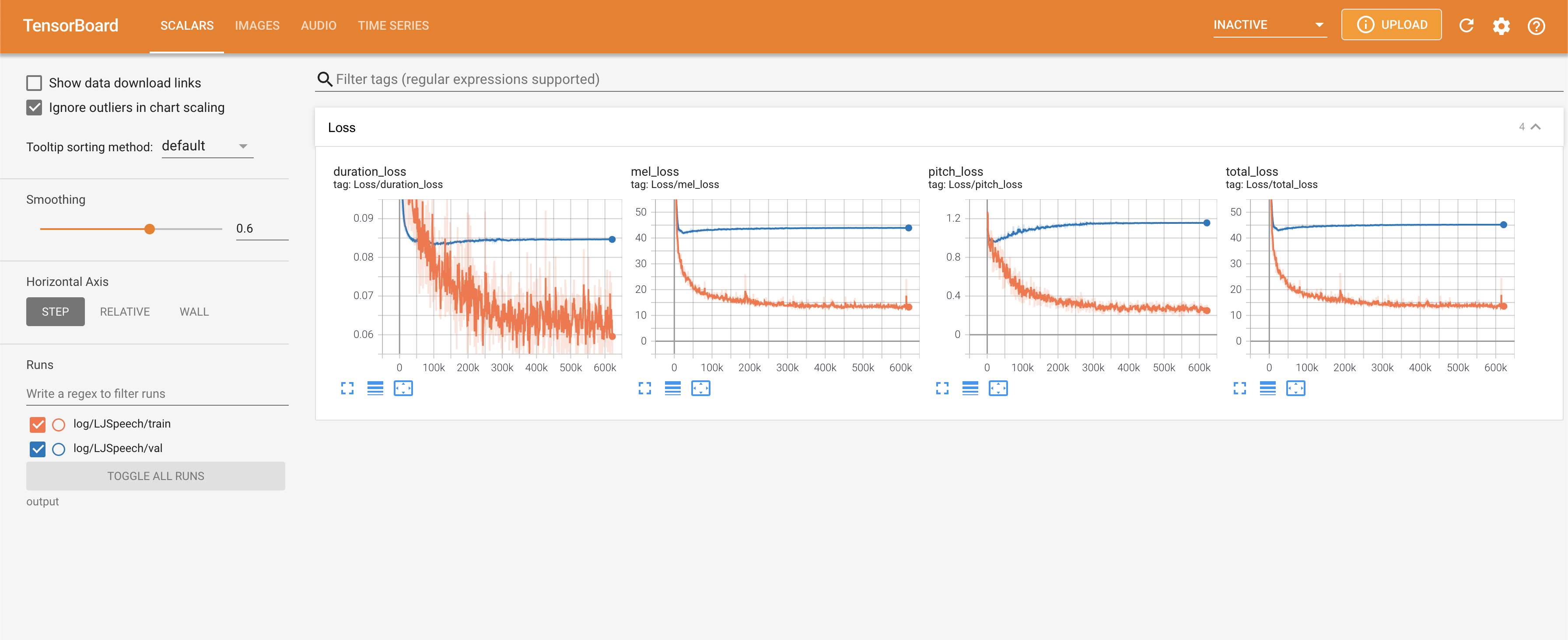
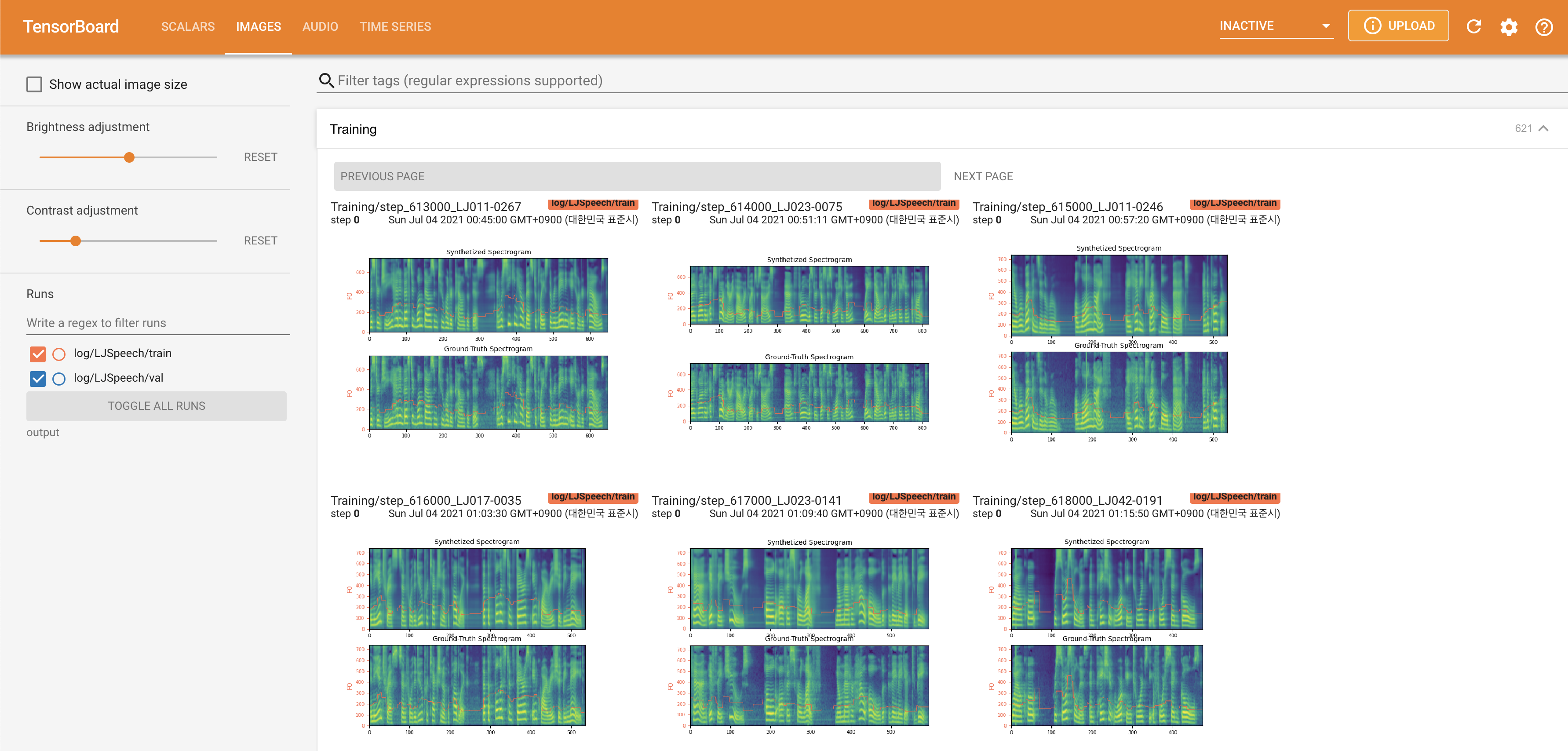
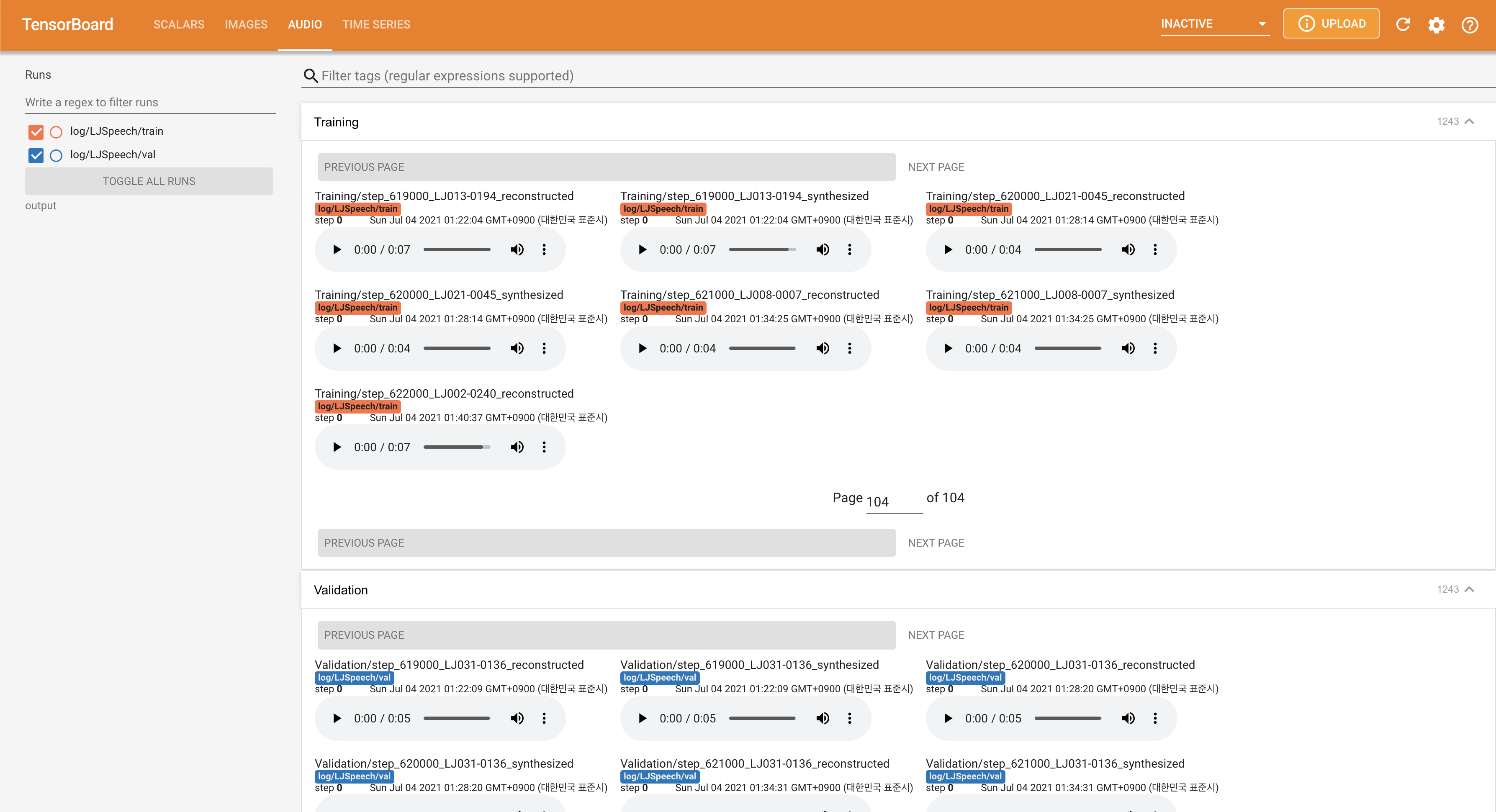
normalization sur False dans ./config/LJSpeech/preprocess.yaml lorsque vous avez besoin de voir plus de plage de hauteur comme décrit le papier. @misc{lee2021fastpitchformant,
author = {Lee, Keon},
title = {FastPitchFormant},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/FastPitchFormant}}
}


