FastPitchFormant
v1.0.0
Implementación de Pytorch de FastPitchFormant: modelado descompuesto basado en filtros fuente para la síntesis del habla.
Puede instalar las dependencias de Python con
pip3 install -r requirements.txt
Debe descargar los modelos previos a la aparición y ponerlos en output/ckpt/LJSpeech/ .
Para TTS de un solo hablante inglés, ejecute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 600000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Las expresiones generadas se colocarán en output/result/ .
También es compatible con la inferencia por lotes, intente
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 600000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Para sintetizar todas las expresiones en preprocessed_data/LJSpeech/val.txt
La tasa de tono/habla de las expresiones sintetizadas se puede controlar especificando las relaciones de tono/energía/duración deseadas. Por ejemplo, uno puede aumentar la tasa de habla en un 20 % y disminuir el tono en un 20 % en
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 600000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml --duration_control 0.8 --pitch_control 0.8
Los conjuntos de datos compatibles son
Primero, corre
python3 prepare_align.py config/LJSpeech/preprocess.yaml
para algunos preparativos.
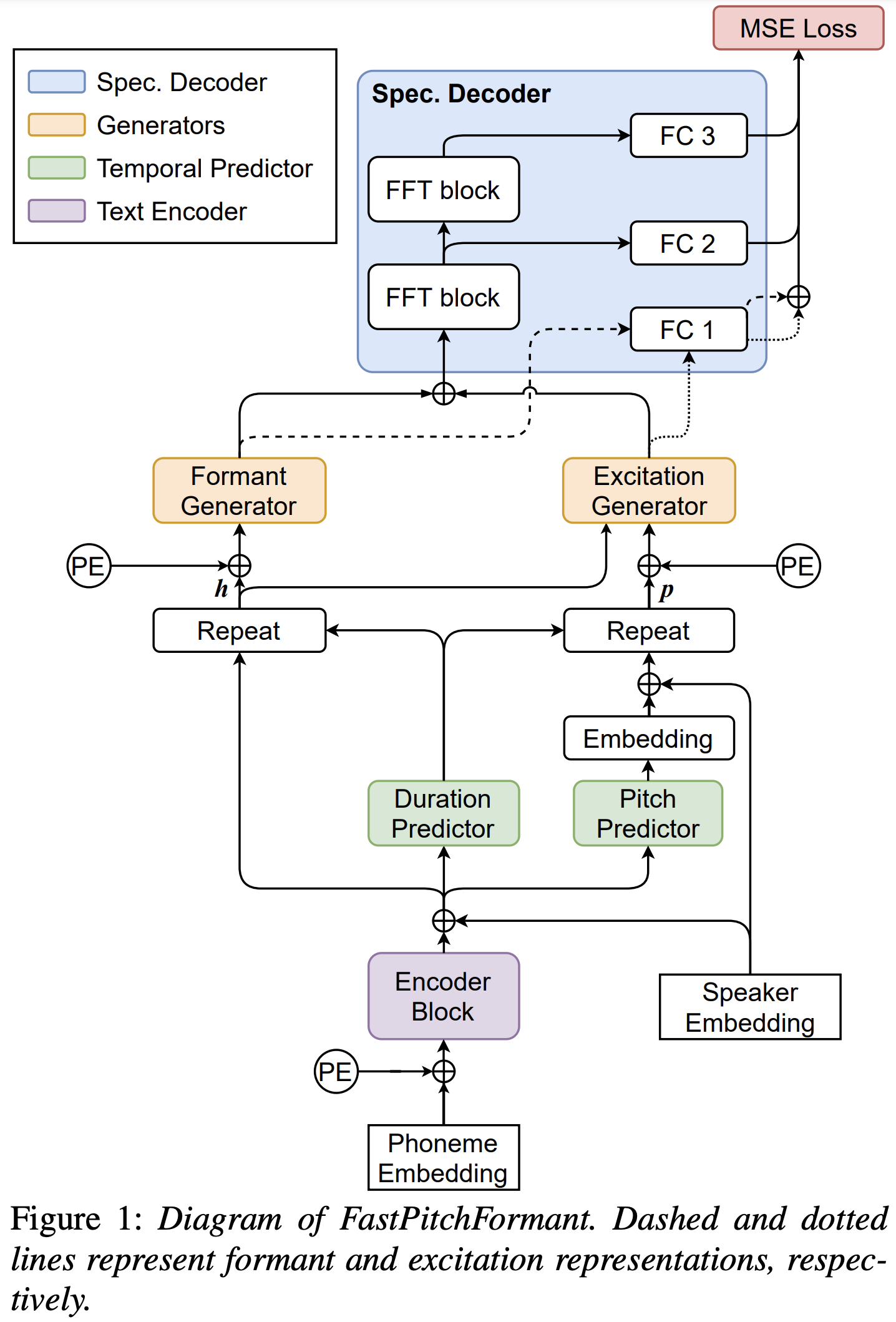
Como se describe en el documento, el alineador forzado de Montreal (MFA) se usa para obtener las alineaciones entre las expresiones y las secuencias de fonema. Aquí se proporcionan alineaciones para los conjuntos de datos LJSPEECch. Debe descomprimir los archivos en preprocessed_data/LJSpeech/TextGrid/ .
Después de eso, ejecute el script de preprocesamiento por
python3 preprocess.py config/LJSpeech/preprocess.yaml
Alternativamente, puede alinear el corpus usted mismo. Descargue el paquete oficial de MFA y ejecute
./montreal-forced-aligner/bin/mfa_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt english preprocessed_data/LJSpeech
o
./montreal-forced-aligner/bin/mfa_train_and_align raw_data/LJSpeech/ lexicon/librispeech-lexicon.txt preprocessed_data/LJSpeech
Para alinear el corpus y luego ejecutar el script de preprocesamiento.
python3 preprocess.py config/LJSpeech/preprocess.yaml
Entrena tu modelo con
python3 train.py -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
Usar
tensorboard --logdir output/log/LJSpeech
para servir tensorboard en su localhost. Se muestran las curvas de pérdida, los espectrogramas MEL sintetizados y los audios.
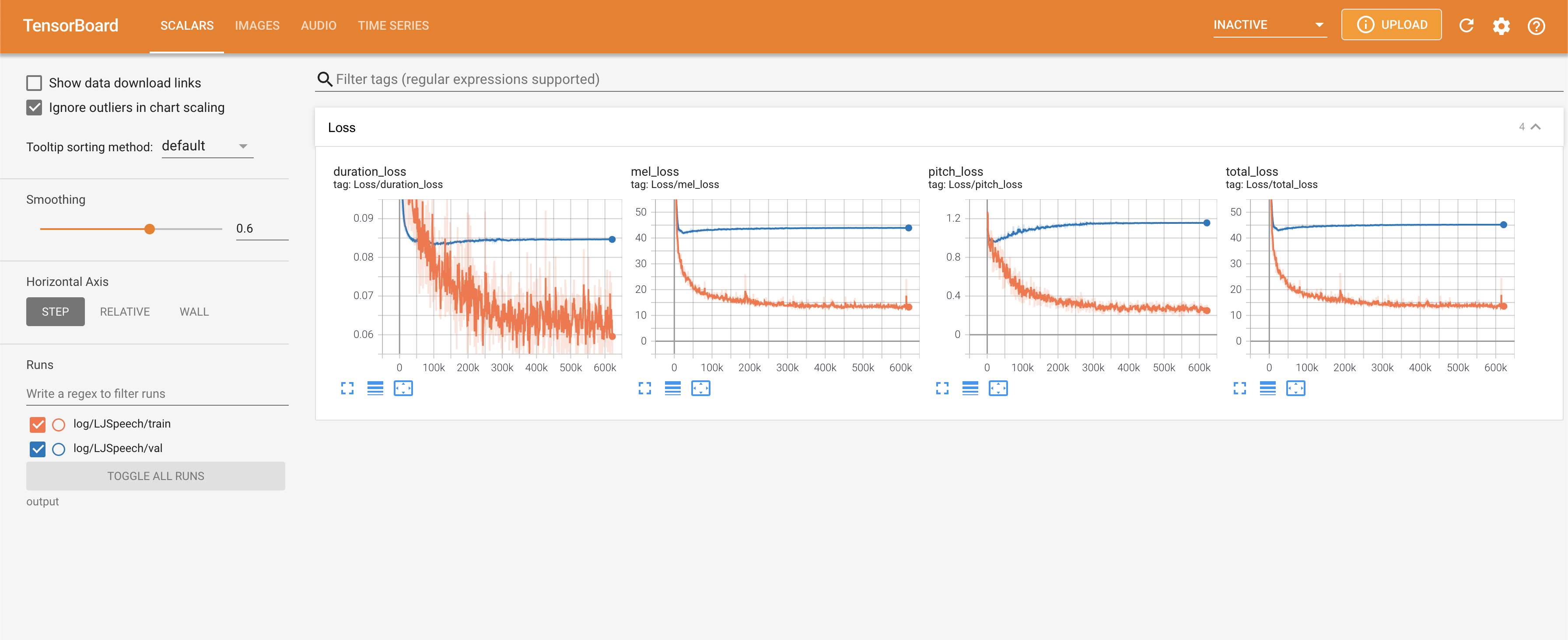
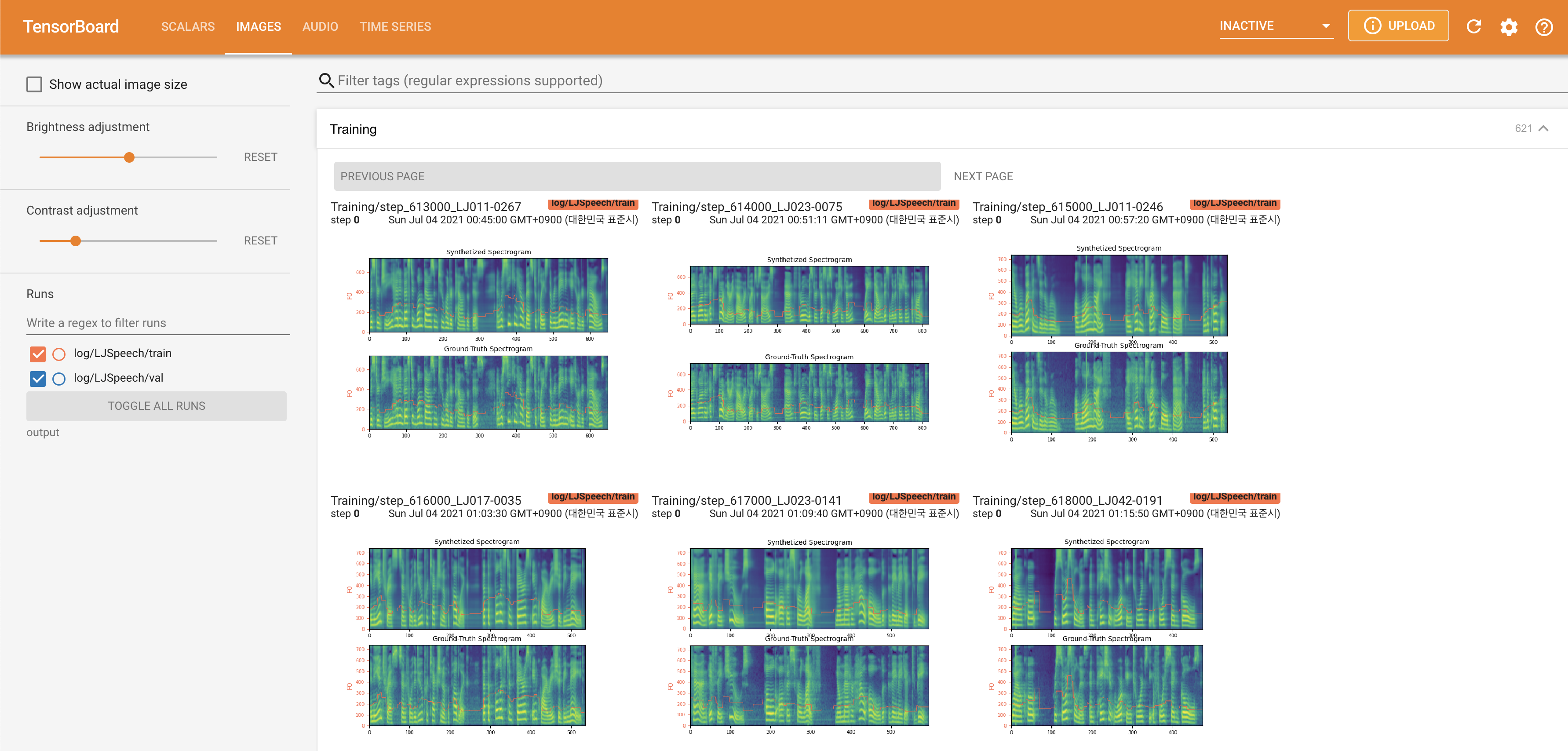
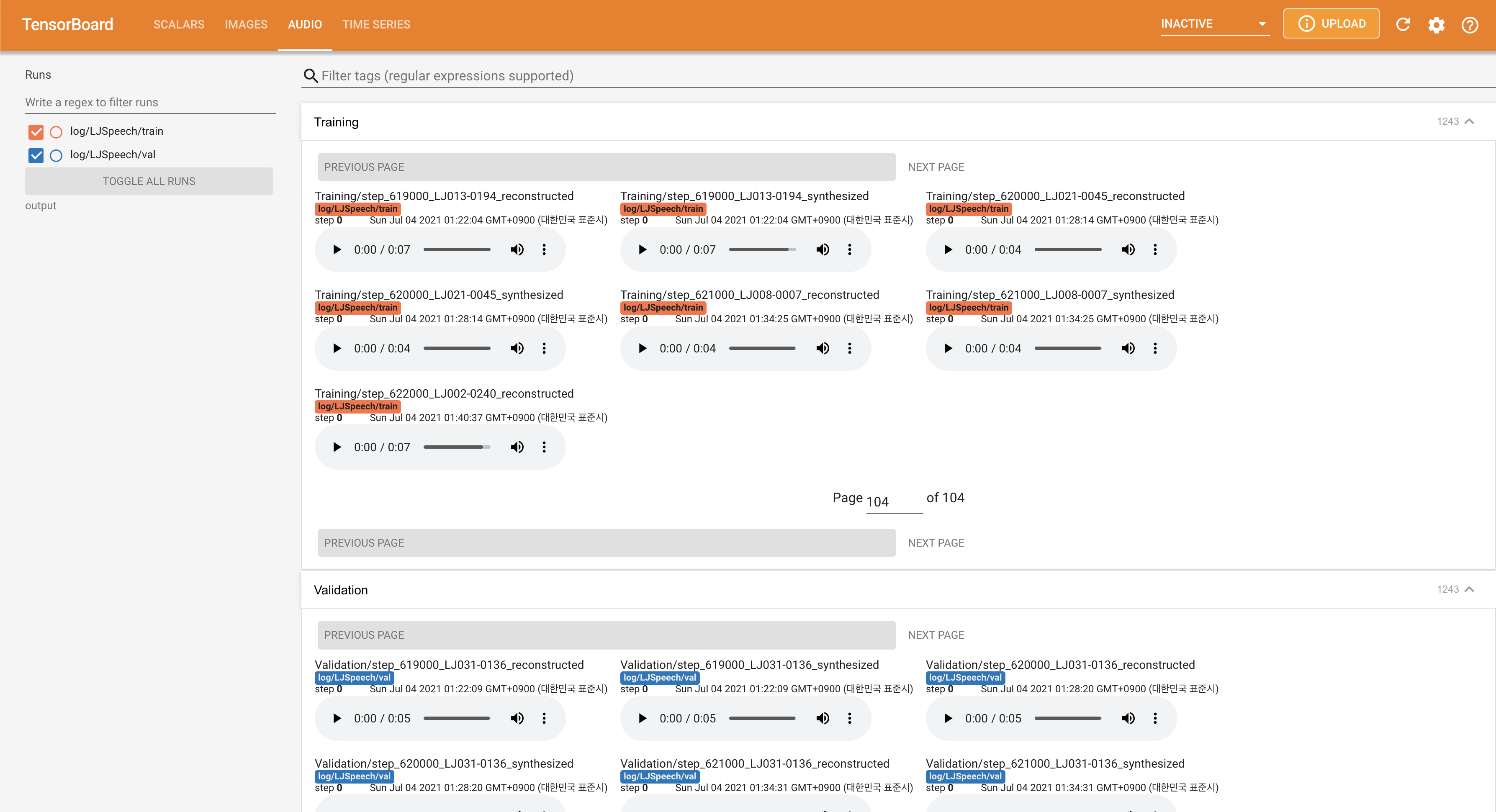
normalization en False en ./config/LJSpeech/preprocess.yaml cuando necesite ver un rango de lanzamiento más amplio como se describió el documento. @misc{lee2021fastpitchformant,
author = {Lee, Keon},
title = {FastPitchFormant},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/FastPitchFormant}}
}


