min dalle
v0.4
YouTube проходит прозрение AI
Это быстрый минимальный порт Boris Dayma's Dall · E Mini (с мегапольными весами). Он был урезан для вывода и преобразован в Pytorch. Единственными сторонними зависимостями являются Numpy, запросы, подушка и факел.
Чтобы сгенерировать сетку 3x3 Dall · Ee Mega Images, которые требуются:
Вот более подробный разбивка производительности на A100. Кредит @Technobird22 и его Nevogen Discord Bot для графика. 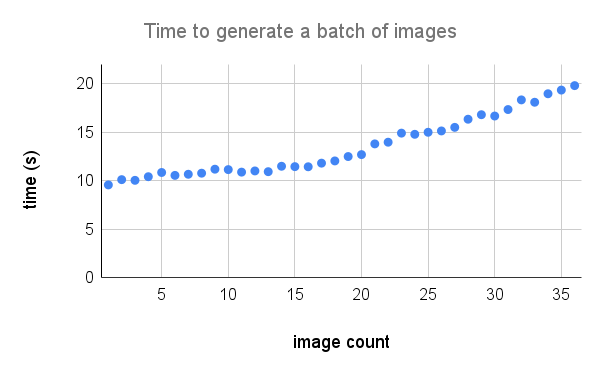
Модель льна и код для преобразования в факел можно найти здесь.
$ pip install min-dalleЗагрузите параметры модели один раз и повторно используйте модель для генерации нескольких изображений.
from min_dalle import MinDalle
model = MinDalle (
models_root = './pretrained' ,
dtype = torch . float32 ,
device = 'cuda' ,
is_mega = True ,
is_reusable = True
) Требуемые модели будут загружены на models_root , если их еще нет. Установите dtype на torch.float16 , чтобы сохранить память графического процессора. Если у вас есть графический процессор Ampere Architecture, вы можете использовать torch.bfloat16 . Установите device на «Cuda» или «CPU». Как только все завершит инициализацию, вызовите generate_image с некоторым текстом столько раз, сколько захотите. Используйте положительное seed для воспроизводимых результатов. Более высокие значения для supercondition_factor приводят к лучшему согласию с текстом, но более узкое разнообразие сгенерированных изображений. Каждый токен изображения отображается из наиболее вероятных токенов top_k . Самый большой логит вычитается из логитов, чтобы избежать инф. Затем логиты делятся на temperature . Если is_seamless это правда, сетка изображения будет покрыта плит в пространстве токена, а не в пиксельном пространстве.
image = model . generate_image (
text = 'Nuclear explosion broccoli' ,
seed = - 1 ,
grid_size = 4 ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 32 ,
is_verbose = False
)
display ( image )
Заслужить @hardmaru для примера
Изображения также могут быть сгенерированы как FloatTensor , если вы хотите обработать их вручную.
images = model . generate_images (
text = 'Nuclear explosion broccoli' ,
seed = - 1 ,
grid_size = 3 ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 16 ,
is_verbose = False
)Чтобы получить изображение в формат PIL, вам придется сначала переместить изображения в процессор и преобразовать тензор в массив Numpy.
images = images . to ( 'cpu' ). numpy () Затем изображение
image = Image . fromarray ( images [ i ])
image . save ( 'image_{}.png' . format ( i )) Если модель используется интерактивно (например, в ноутбуке) generate_image_stream может использоваться для генерации потока изображений, когда модель декодирует. Детоцессор добавляет небольшую задержку для каждого изображения. Установите progressive_outputs в True чтобы включить это. Пример реализован в Colab.
image_stream = model . generate_image_stream (
text = 'Dali painting of WALL·E' ,
seed = - 1 ,
grid_size = 3 ,
progressive_outputs = True ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 16 ,
is_verbose = False
)
for image in image_stream :
display ( image )
Используйте image_from_text.py , чтобы генерировать изображения из командной строки.
$ python image_from_text.py --text= ' artificial intelligence ' --no-mega


