min dalle
v0.4
AIエピファニーによるYouTubeウォークスルー
これは、Boris DaymaのDall・E Mini(メガウェイト付き)の高速で最小限のポートです。推論のために剥奪され、Pytorchに変換されました。サードパーティの唯一の依存関係は、numpy、リクエスト、枕、トーチです。
Dall・E Mega画像の3x3グリッドを生成するには:
A100でのパフォーマンスのより詳細な内訳は次のとおりです。グラフの @Technobird22と彼のNeogen Discord Botのクレジット。 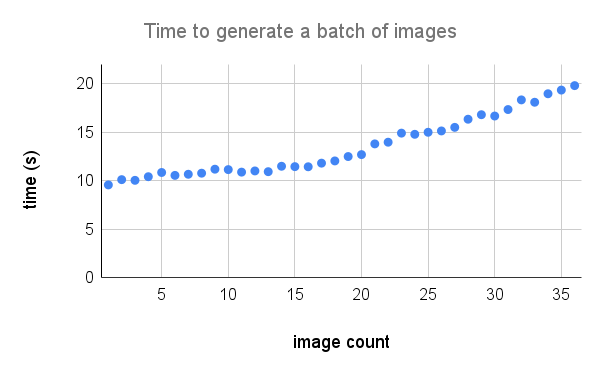
それをトーチに変換するための亜麻モデルとコードは、ここで見つけることができます。
$ pip install min-dalleモデルパラメーターを一度ロードし、モデルを再利用して複数の画像を生成します。
from min_dalle import MinDalle
model = MinDalle (
models_root = './pretrained' ,
dtype = torch . float32 ,
device = 'cuda' ,
is_mega = True ,
is_reusable = True
)必要なモデルは、まだ存在していない場合はmodels_rootにダウンロードされます。 GPUメモリを保存するには、 dtypeをtorch.float16に設定します。アンペアアーキテクチャGPUをお持ちの場合は、 torch.bfloat16使用できます。 device 「cuda」または「cpu」のいずれかに設定します。すべてが初期化が終了したら、必要なだけテキストでgenerate_image呼び出します。再現可能な結果には肯定的なseedを使用してください。 supercondition_factorの値が高いと、テキストとよりよく一致しますが、生成された画像の多様性が狭くなります。すべての画像トークンは、 top_k最も可能性の高いトークンからサンプリングされます。最大のロジットは、INFを避けるためにロジットから差し引かれます。ロジットはtemperatureで除算されます。 is_seamlessがtrueの場合、画像グリッドはピクセルスペースではなくトークンスペースでタイル張りになります。
image = model . generate_image (
text = 'Nuclear explosion broccoli' ,
seed = - 1 ,
grid_size = 4 ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 32 ,
is_verbose = False
)
display ( image )
例については、@hardmaruのクレジット
画像は、手動で処理する場合に備えて、 FloatTensorとして生成することもできます。
images = model . generate_images (
text = 'Nuclear explosion broccoli' ,
seed = - 1 ,
grid_size = 3 ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 16 ,
is_verbose = False
)画像をPIL形式にするには、最初に画像をCPUに移動し、テンソルをnumpyアレイに変換する必要があります。
images = images . to ( 'cpu' ). numpy ()次に画像
image = Image . fromarray ( images [ i ])
image . save ( 'image_{}.png' . format ( i ))モデルがインタラクティブに使用されている場合(ノートブックでは)、モデルがデコードされているときに、 generate_image_stream使用して画像のストリームを生成できます。デトゥケン剤は、各画像にわずかな遅延を追加します。これを有効にするために、 progressive_outputsをTrueに設定します。コラブに例が実装されています。
image_stream = model . generate_image_stream (
text = 'Dali painting of WALL·E' ,
seed = - 1 ,
grid_size = 3 ,
progressive_outputs = True ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 16 ,
is_verbose = False
)
for image in image_stream :
display ( image )
image_from_text.pyを使用して、コマンドラインから画像を生成します。
$ python image_from_text.py --text= ' artificial intelligence ' --no-mega


