min dalle
v0.4
Caminata por YouTube por la Epifanía AI
Este es un puerto rápido y mínimo de Dall · e mini de Boris Dayma (con mega pesos). Se ha despojado para inferencia y convertido a Pytorch. Las únicas dependencias de terceros son Numpy, solicitudes, almohada y antorcha.
Para generar una cuadrícula 3x3 de imágenes de Dall · E Mega Toma:
Aquí hay un desglose más detallado del rendimiento en un A100. Crédito a @Technobird22 y su bot Neogen Discord Bot para el gráfico. 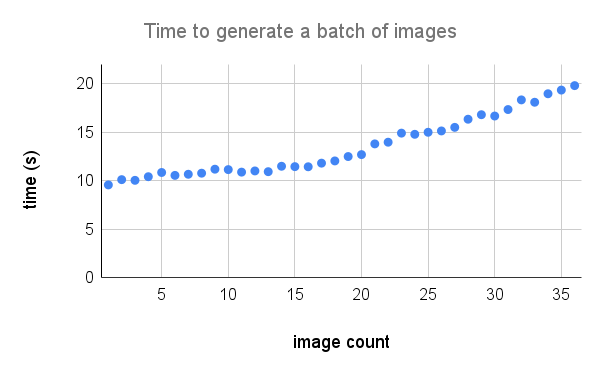
El modelo de lino y el código para convertirlo en antorcha se pueden encontrar aquí.
$ pip install min-dalleCargue los parámetros del modelo una vez y reutilice el modelo para generar múltiples imágenes.
from min_dalle import MinDalle
model = MinDalle (
models_root = './pretrained' ,
dtype = torch . float32 ,
device = 'cuda' ,
is_mega = True ,
is_reusable = True
) Los modelos requeridos se descargarán a models_root si aún no están allí. Establezca el dtype en torch.float16 para guardar la memoria de GPU. Si tiene una GPU de arquitectura Ampere, puede usar torch.bfloat16 . Establezca el device en "CUDA" o "CPU". Una vez que todo haya terminado de inicializarse, llame generate_image con algún texto tantas veces como desee. Use una seed positiva para resultados reproducibles. Los valores más altos para supercondition_factor dan como resultado un mejor acuerdo con el texto, pero una variedad más estrecha de imágenes generadas. Cada token de imagen se muestrea desde los tokens más probables top_k . El logit más grande se resta de los logits para evitar INFS. Los logits se dividen por la temperature . Si is_seamless es verdadero, la cuadrícula de la imagen se balancea en el espacio de token, no en el espacio de píxeles.
image = model . generate_image (
text = 'Nuclear explosion broccoli' ,
seed = - 1 ,
grid_size = 4 ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 32 ,
is_verbose = False
)
display ( image )
Crédito a @hardmaru por el ejemplo
Las imágenes también se pueden generar como un FloatTensor en caso de que desee procesarlas manualmente.
images = model . generate_images (
text = 'Nuclear explosion broccoli' ,
seed = - 1 ,
grid_size = 3 ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 16 ,
is_verbose = False
)Para obtener una imagen en formato PIL, primero tendrá que mover las imágenes a la CPU y convertir el tensor en una matriz Numpy.
images = images . to ( 'cpu' ). numpy () Luego imagen
image = Image . fromarray ( images [ i ])
image . save ( 'image_{}.png' . format ( i )) Si el modelo se usa de manera interactiva (por ejemplo, en un cuaderno) generate_image_stream se puede usar para generar una secuencia de imágenes a medida que el modelo se decodifica. El Delokenizer agrega un ligero retraso para cada imagen. Establezca progressive_outputs en True para habilitar esto. Se implementa un ejemplo en el Colab.
image_stream = model . generate_image_stream (
text = 'Dali painting of WALL·E' ,
seed = - 1 ,
grid_size = 3 ,
progressive_outputs = True ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 16 ,
is_verbose = False
)
for image in image_stream :
display ( image )
Use image_from_text.py para generar imágenes desde la línea de comando.
$ python image_from_text.py --text= ' artificial intelligence ' --no-mega


