min dalle
v0.4
YouTube-Durchgang durch die Ai-Epiphany
Dies ist ein schneller, minimaler Hafen von Boris Daymas Dall · E Mini (mit Megagewichten). Es wurde zur Folgerung abgezogen und in Pytorch umgewandelt. Die einzigen Abhängigkeiten Dritter sind Numpy, Anfragen, Kissen und Taschenlampe.
So erzeugen Sie ein 3x3 -Gitter von Dall · E -Mega -Bildern, die es benötigt:
Hier ist eine detailliertere Aufschlüsselung der Leistung auf einem A100. Kredit an @Technobird22 und sein Neogen Discord Bot für die Grafik. 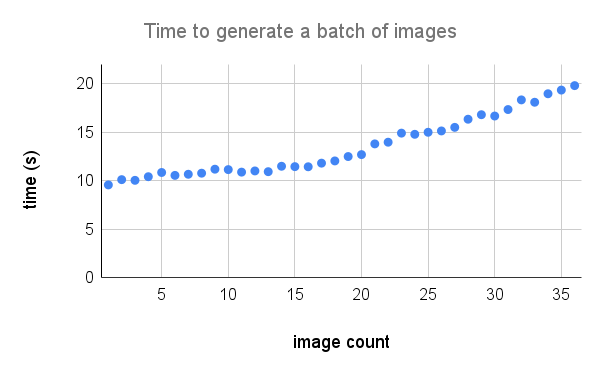
Das Flachsmodell und der Code zum Konvertieren in Torch finden Sie hier.
$ pip install min-dalleLaden Sie die Modellparameter einmal und verwenden Sie das Modell wieder, um mehrere Bilder zu generieren.
from min_dalle import MinDalle
model = MinDalle (
models_root = './pretrained' ,
dtype = torch . float32 ,
device = 'cuda' ,
is_mega = True ,
is_reusable = True
) Die erforderlichen Modelle werden auf models_root heruntergeladen, wenn sie nicht bereits vorhanden sind. Stellen Sie den dtype auf torch.float16 ein, um den GPU -Speicher zu speichern. Wenn Sie eine Ampere -Architektur -GPU haben, können Sie torch.bfloat16 verwenden. Stellen Sie das device entweder auf "CUDA" oder "CPU" ein. Sobald alles initialisiert wurde, call generate_image mit etwas Text so oft wie gewünscht. Verwenden Sie einen positiven seed für reproduzierbare Ergebnisse. Höhere Werte für supercondition_factor führen zu einer besseren Übereinstimmung mit dem Text, aber zu einer engeren Vielfalt erzeugter Bilder. Jedes Bild -Token wird von den wahrscheinlichsten Token top_k abgetastet. Der größte Logit wird von den Logits abgezogen, um INFs zu vermeiden. Die Logits werden dann durch die temperature geteilt. Wenn is_seamless wahr ist, wird das Bildraster im Token -Raum und nicht im Pixelraum gefliest.
image = model . generate_image (
text = 'Nuclear explosion broccoli' ,
seed = - 1 ,
grid_size = 4 ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 32 ,
is_verbose = False
)
display ( image )
Kredit an @hardmaru für das Beispiel
Die Bilder können auch als FloatTensor erzeugt werden, falls Sie sie manuell verarbeiten möchten.
images = model . generate_images (
text = 'Nuclear explosion broccoli' ,
seed = - 1 ,
grid_size = 3 ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 16 ,
is_verbose = False
)Um ein Bild in das PIL -Format zu bringen, müssen Sie zuerst die Bilder in die CPU verschieben und den Tensor in ein Numpy -Array umwandeln.
images = images . to ( 'cpu' ). numpy () Dann Bild
image = Image . fromarray ( images [ i ])
image . save ( 'image_{}.png' . format ( i )) Wenn das Modell interaktiv verwendet wird (z. B. in einem Notizbuch), kann generate_image_stream verwendet werden, um einen Bilderstrom zu generieren, wenn das Modell entschlüsselt wird. Der Detokenizer fügt für jedes Bild eine leichte Verzögerung hinzu. Stellen Sie progressive_outputs auf True um dies zu aktivieren. Ein Beispiel wird im Colab implementiert.
image_stream = model . generate_image_stream (
text = 'Dali painting of WALL·E' ,
seed = - 1 ,
grid_size = 3 ,
progressive_outputs = True ,
is_seamless = False ,
temperature = 1 ,
top_k = 256 ,
supercondition_factor = 16 ,
is_verbose = False
)
for image in image_stream :
display ( image )
Verwenden Sie image_from_text.py um Bilder aus der Befehlszeile zu generieren.
$ python image_from_text.py --text= ' artificial intelligence ' --no-mega


